
Graphics IP supplier Imagination Technologies has long advocated the acceleration of edge-based deep learning inference operations via the combination of the company's GPU and ISP cores. Latest-generation graphics architectures from the company continue this trend, enhancing performance and reducing memory bandwidth and capacity requirements in entry-level and mainstream SoCs and systems based on them. And, for more demanding deep learning applications, the company has introduced its first neural network coprocessor core family (Figure 1).
Figure 1. Enhanced graphics cores, along with a new neural network IP family, give Imagination Technologies' licensees options for deep learning acceleration.
The entry-level PowerVR 9XE and mainstream 9XM graphics IP families, intended to succeed the 8XE and 8XEP, respectively, extend the longstanding Rogue architecture rather than using the Furian architecture successor that forms the foundation of the high-end 8XT product line (Figure 2).
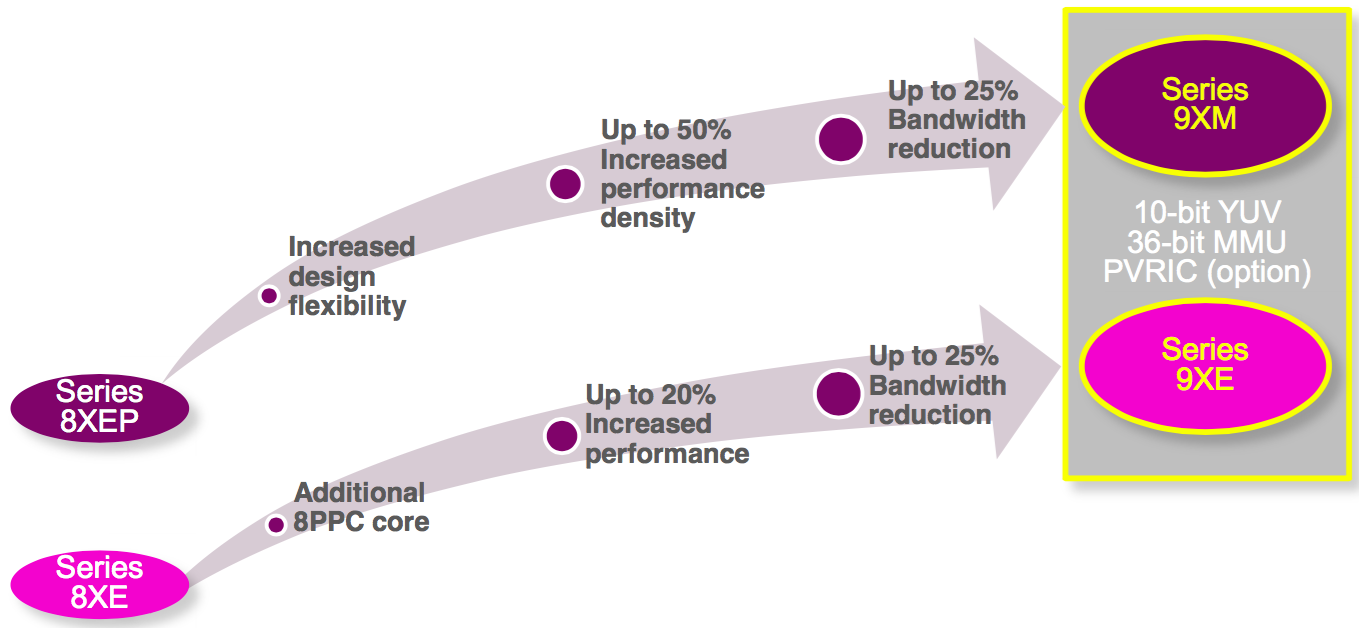
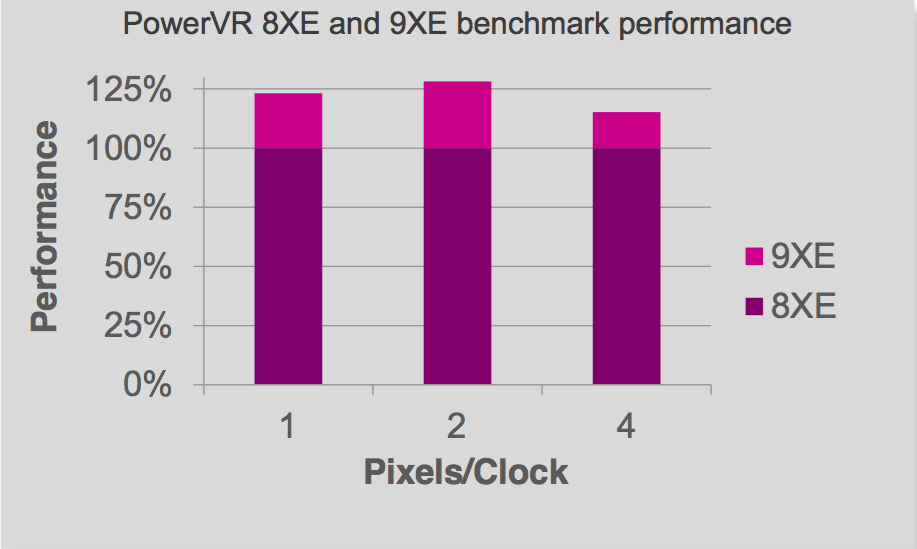
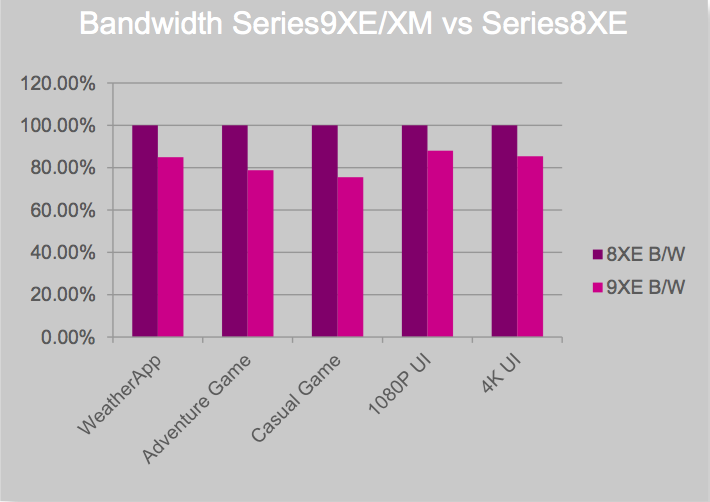
Figure 2. Imagination Technologies' 9XE and 9XM graphics core families build on their predecessors (top) with various performance improvements (middle) along with reductions in required memory bandwidth (bottom).
The performance improvements are important to both graphics applications and to emerging deep learning inference and other "GPU compute" functions; equally critical is delivering this performance with reduced silicon area and power consumption. Reducing the required bandwidth between the GPU and frame buffer, along with the required size of the frame buffer, has implications in terms of the amount, type and speed of DRAM needed in the design; such bandwidth reductions also reduce the power consumption of the graphics subsystem.
Scalability both within and between the product families was also a key consideration in their development, according to Chris Longstaff, the company's senior director of marketing for PowerVR products (Figure 3). Different customers have varying, and often very specific, requirements for performance, power consumption, silicon area consumption, and other parameters. The baseline specifications for any customer, Longstaff explained in a recent briefing, are the display resolution and frame rate, therefore the texture and pixel fillrates that need to be supported. Once these parameters are determined, the complexity of graphics tasks, along with deep learning and other computation tasks, to be supported determines which product family (and member of a given family) is appropriate in a particular situation.
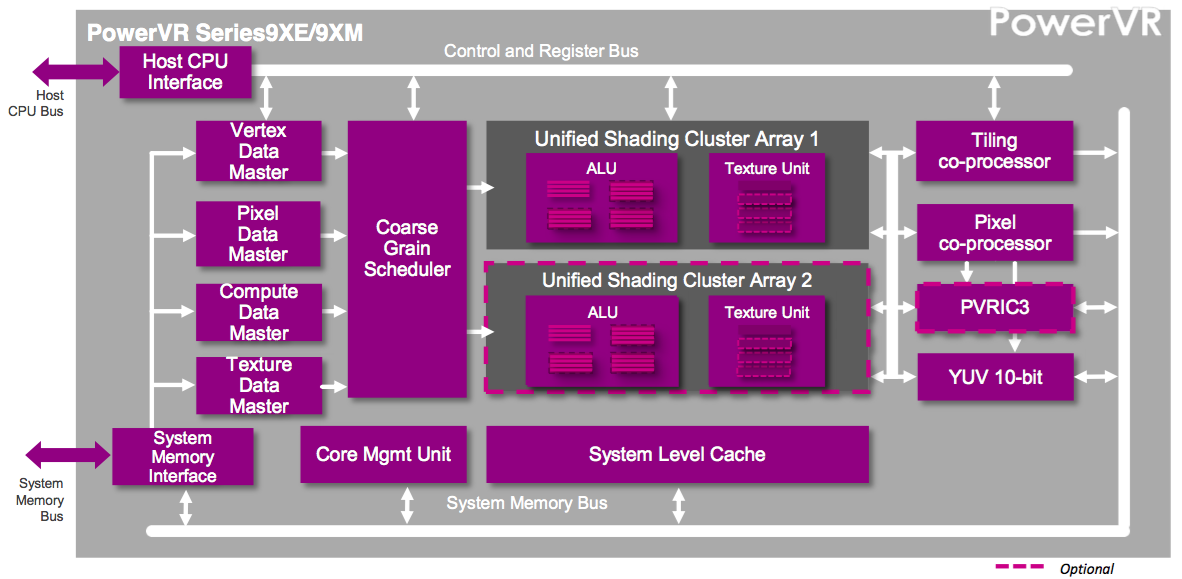

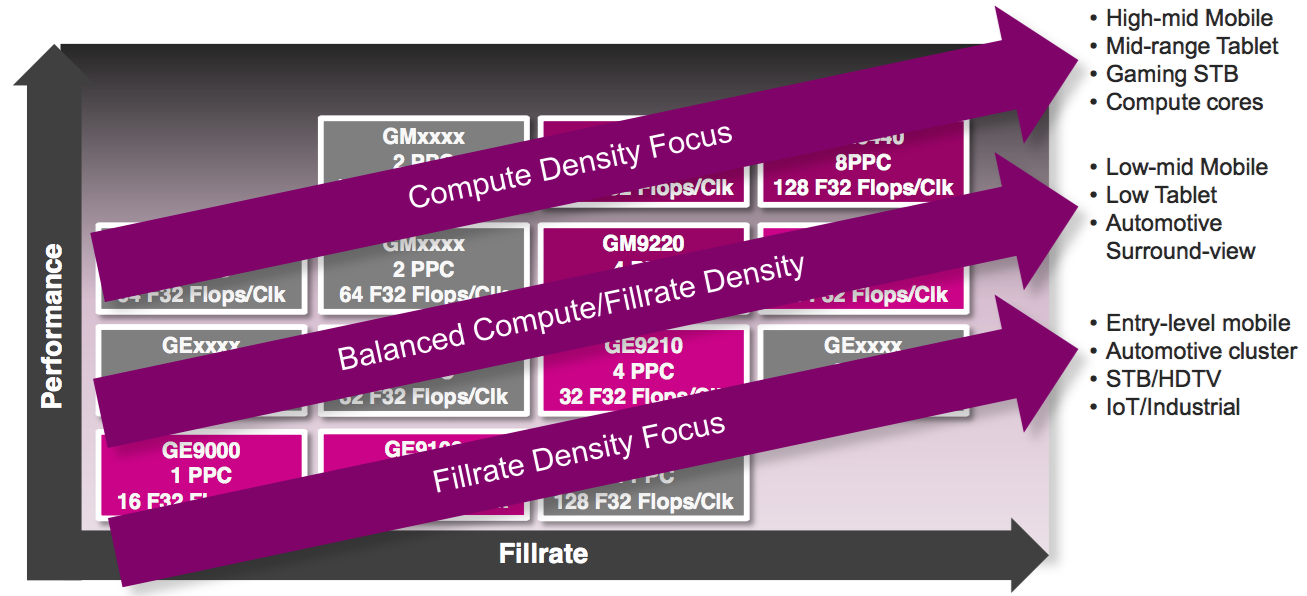
Figure 3. Key to the new graphics cores' architectures (top) is their scalability, enabling the company to rapidly iterate new variants with particular capabilities (middle) to address licensees' specific needs (bottom).
Leveraging a GPU for deep learning inference is beneficial in several respects: a graphics processor is already included in many SoC designs, so there's no need to add an incremental core or chip, plus GPUs are natively capable of handling floating-point operations so there's little to no need to convert a deep learning model developed on a high-end GPU in the process of porting it to an embedded implementation (Figure 4). However, time-sharing a GPU between graphics and inference tasks ends up performance-limiting both tasks from a throughput standpoint, versus dedicating a processor to each task. And since fixed-point deep learning models can deliver comparable inference accuracy with much lower required processing performance, power consumption and silicon area versus floating-point alternatives, a graphics-tailored GPU isn't necessarily the optimum solution for handling them, anyway.
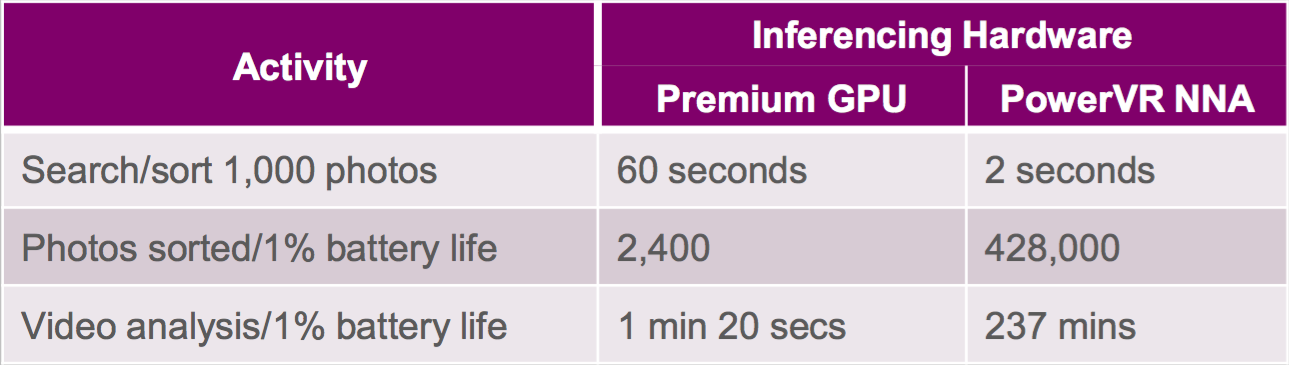
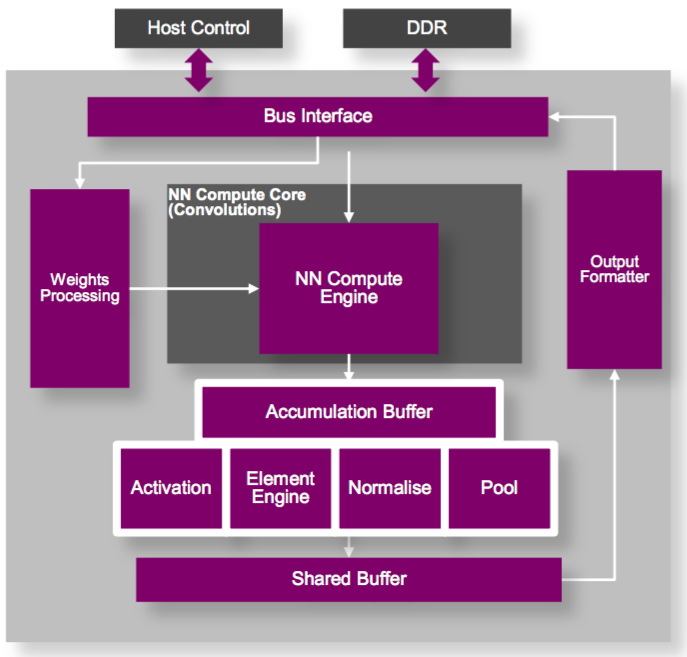
Figure 4. Leveraging an embedded GPU core for deep learning inference acceleration has benefits, but raw performance isn't usually one of them (top), compelling Imagination Technologies' development of a dedicated neural network accelerator line for more demanding application needs (bottom).
IP competitors such as AImotive, Cadence, CEVA, and Synopsys have targeting this opportunity by delivering dedicated neural network processing cores to the market, and now Imagination Technologies has responded with its PowerVR 2NX NNA (neural network accelerator) family. Available NNA core family members offer between 128 and 1,024 16-bit MACs; each 16-bit MAC can also be alternatively configured as two 8-bit MACs, and multi-core parallel processing is also possible. Unique aspects of Imagination Technologies' architecture approach, according to Longstaff and Kristof Beets, Senior Director of Business Development for PowerVR, include an optional MMU (memory management unit), a key requirement with full-featured operating systems such as Android. Longstaff also claims that PowerVR 2NX will deliver 20% more MACs/mm2 of silicon area versus competitors on similar process lithographies, and that low-end PowerVR 2NX variants will require less than 1 mm2 of real estate when fabricated on a 16 nm process node.
Much of the PowerVR 2NX advantage, Longstaff says, comes from the accompanying development tool and API software stacks (Figure 5). As with competitors' approaches, floating- to fixed-point neural network algorithm conversion is a key aspect of the PowerVR 2NX development tool suite. The toolset's integrated simulation capabilities also enable evaluation and selection of specific data and weight precisions that balance memory usage and compute requirements against accuracy. Developers not only can vary the input source precision but also the calculation precision at various model layers through the 32-bit (max) internal pipeline, to further optimize memory bandwidth and size versus accuracy.
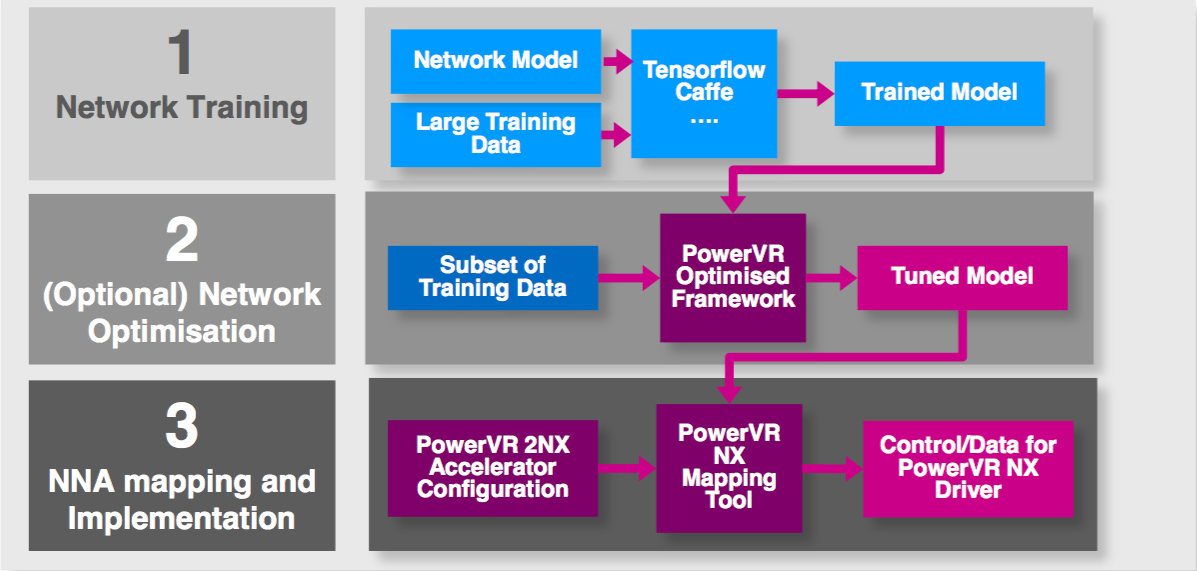
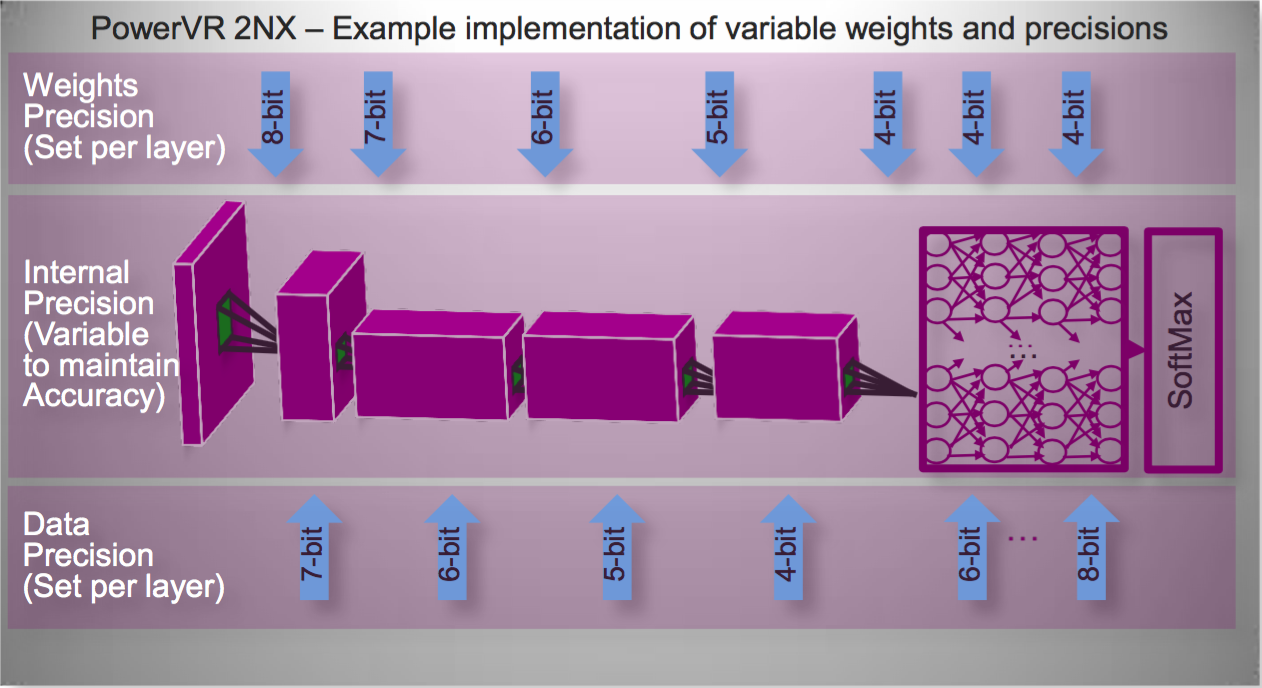
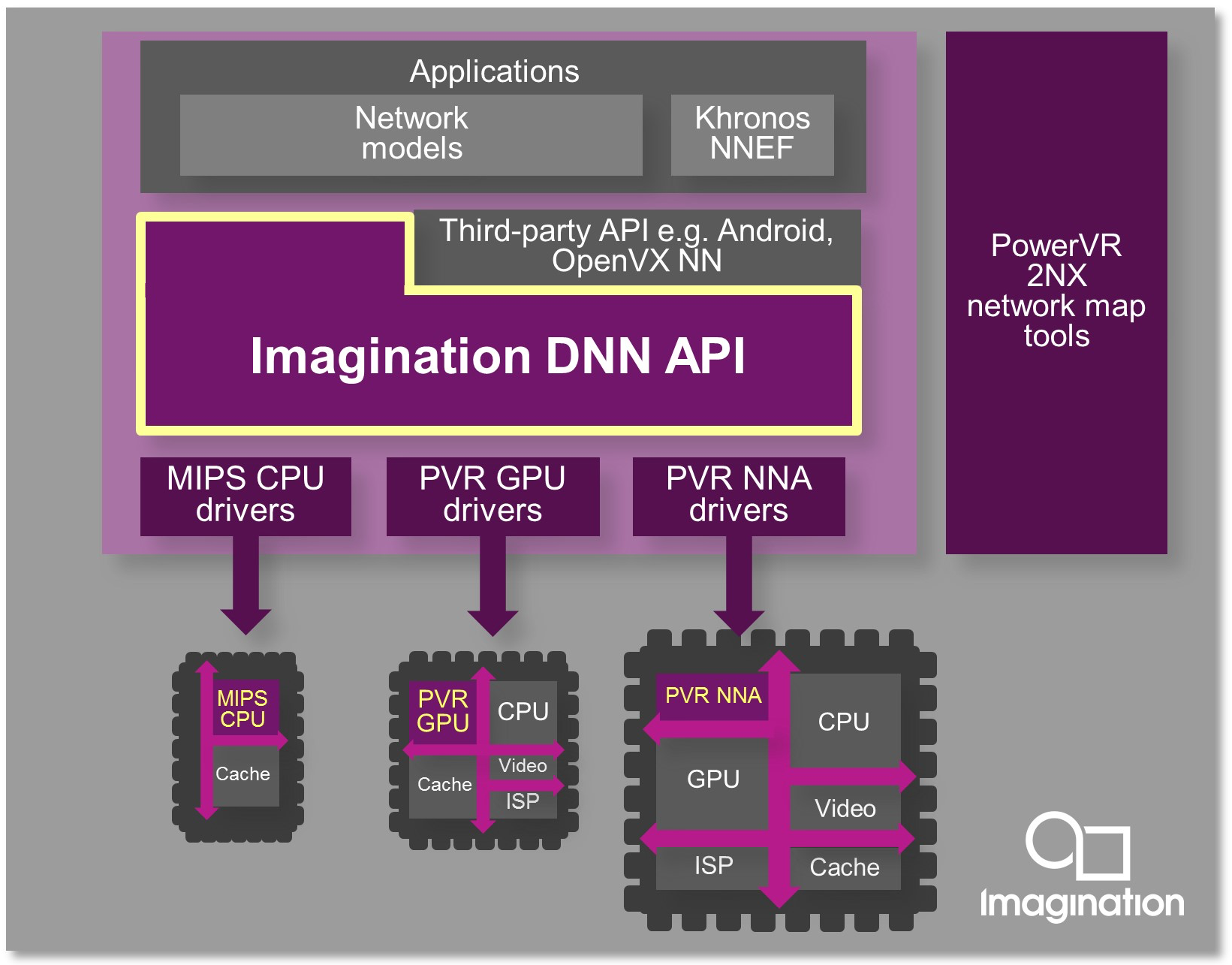
Figure 5. The PowerVR 2NX development tool suite supports floating- to fixed-point conversion, along with accuracy simulation and evaluation of precision alternatives and optional partial retraining for accuracy improvement (top). Calculation precision control extends throughout the inference pipeline, along with potentially merging multiple layers into one (middle). And a run-time API spreads the total inference workload across multiple processing resources in a SoC (bottom).
The PowerVR 2NX tool suite supports developer evaluation of potential collapse of multiple neural network layers into one. The toolset also provides for optional retraining on a subset of the original model data for further accuracy improvement, as described by Imagination's Principal Research Engineer Paul Brasnett in a recent Embedded Vision Summit presentation focused specifically on GPUs but also applicable to neural network accelerators. And at runtime, the company's DNN (deep neural network) API dynamically partitions the total inference workload across available GPU, NNA and (MIPS) CPU core resources.
The PowerVR 2NX NNA core is now running as a pre-beta prototype in a Xilinx FPGA (Video 1):
Video 1. A pre-beta version of Imagination Technologies neural network accelerator core is already tackling inference tasks inside a Xilinx FPGA.
Imagination Technologies is targeting an 800 MHz (nominal)/1 GHz (max) clock speed when the core is implemented in a 16 nm ASIC. Initially supporting the Caffe deep learning framework, the development tool suite will shortly expand to include support for Google's TensorFlow (both full and Lite); other frameworks such as the Facebook-championed Caffe2, the Amazon-backed MXNet and Microsoft's Cognitive Toolkit are also under consideration. Available for licensing now, the core family design is forecasted to be finalized by the end of this year with initial SoC implementations targeted for the second half of 2018. Similarly, various PowerVR 9XE and 9XM graphics cores (now in internal beta) will roll out throughout the fourth quarter, with the majority of the initial planned family members scheduled to be available by the end of this year.
Overshadowing all of these product announcements is the company's pending subdivision and takeover. Back in June, Imagination Technologies put itself up for sale, after having announced one month earlier that it planned to spin off its MIPS CPU and Ensigma communications IP businesses. And just last weekend, the planned purchasers were revealed; the MIPS CPU division is being sold to Tallwood Venture Capital, while the remainder of the company (including the various PowerVR product lines) is being acquired by Canyon Bridge. For its part, Canyon Bridge has pledged to continue investing in Imagination’s various research and development activities, and currently plans no job cuts.
Add new comment