
Hard on the heels of the public release of CEVA's second-generation convolutional neural network toolset, CDNN2, the company is putting the final touches on its fifth-generation processor core, the CEVA-XM6, designed to run software generated by that toolset. Liran Bar, the company's Director of Product Marketing, acknowledged in a recent briefing that the new core represents an evolutionary step, versus revolutionary break, from its predecessors: the CEVA-MM3101 (introduced in 2012) and the CEVA-XM4 (which debuted in 2015). However, particularly if your deep learning-based or otherwise computationally demanding application would benefit from an expansion in available MAC (multiply-accumulate operation) throughput, the CEVA-XM6 will likely be a welcome addition to the product family.
Before diving into architecture details, however, the first question BDTI asked Bar in a recent briefing was what happened to the CEVA-XM5? Bar admitted that the product naming transition from the CEVA-XM4 directly to the CEVA-XM6 was a bit odd, although he declined to share any specifics on the background behind the decision. Bar hinted that a CEVA-XM5 might still appear at some point in the future. And at first glance, a high-level block diagram comparison between the CEVA-XM4 and CEVA-XM6 suggests few changes (Figure 1):
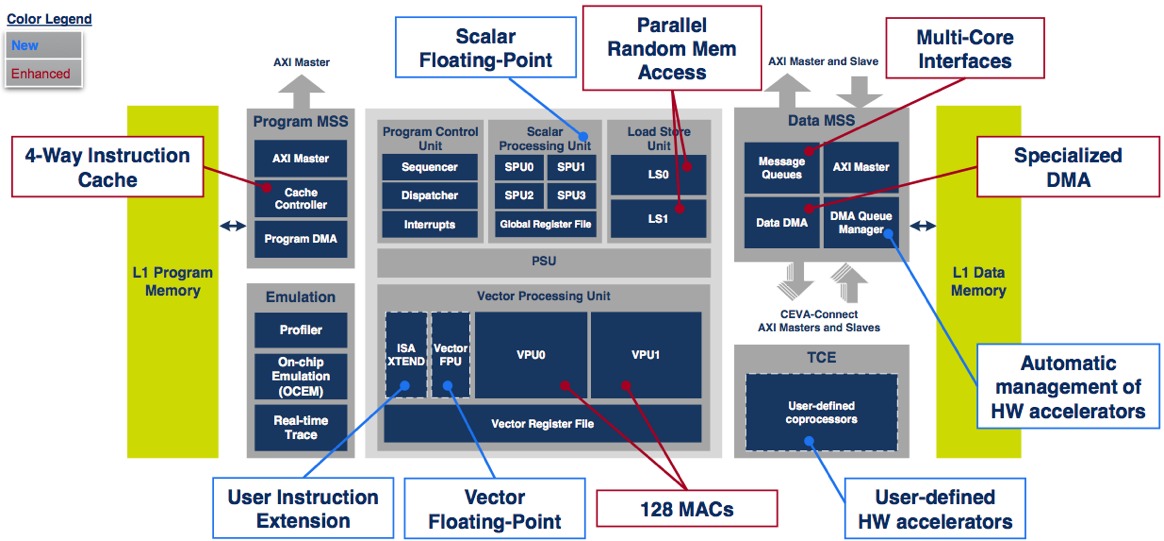
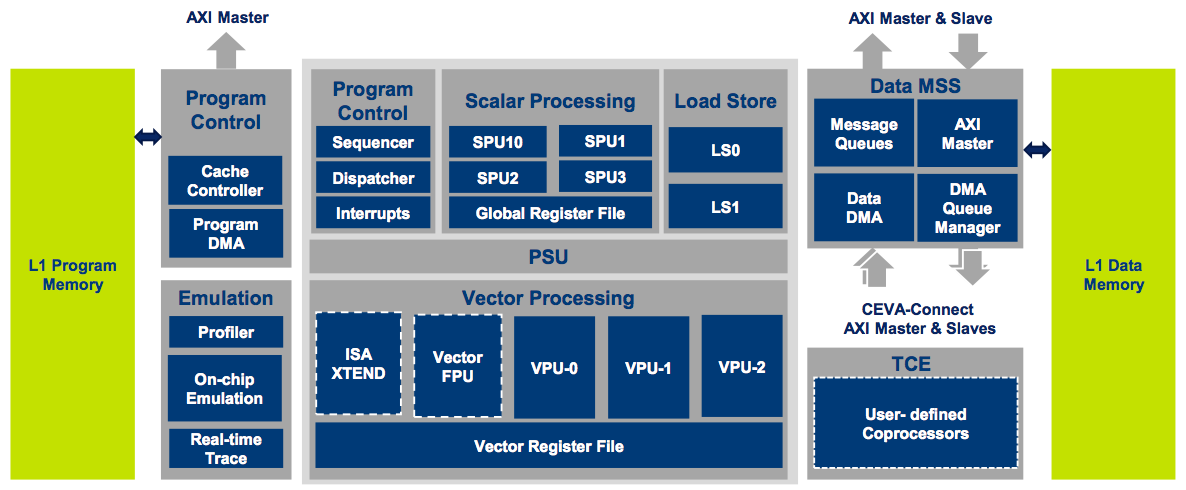
Figure 1. The CEVA-XM4 (top) and newer CEVA-XM6 (bottom) may look quite similar at first glance, but the block diagram overview omits key enhancements.
Note, however, the newer core's inclusion of a third vector floating point unit. Bar was also quick to point out improvements not visible in the block diagram, such as the improved scatter-gather and sliding-window access schemes supported in the enhanced integrated memory controller. And equally if not more notable is a doubling of the number of MAC resources in the CEVA-XM6 beyond those available in the CEVA-XM4, which themselves were quadrupled versus with the CEVA-MM3101 predecessor (Table 1):
|
MACs (multiply-accululate operations) per cycle |
8x16 |
16x16 |
|
CEVA-MM3101 |
32 |
16 |
|
CEVA-XM4 |
128 |
64 |
|
CEVA-XM6 |
256 |
128 |
Table 1. Integrated MAC resources in the last three generations of CEVA vision processing cores.
Note that the columns in above table are either/or, not cumulative; i.e., each 16x16 MAC unit can alternatively be configured to perform two 8x16 MACs. And to that point, if even more 16x16 MACs would be beneficial to you, CEVA now also offers a separate hardware acceleration co-processor supplying 512 additional 16x16 MAC units (Figure 2). CEVA selected this particular number, according to Bar, after conducting thorough analysis of the convolution layers included in its customers' deep learning models both now and they're forecasted to evolve in the near future. Fewer than 512 additional MACs would, according to Bar, deliver an insufficient return on the additional silicon area investment, while even more than 512 would result in insufficient utilization across the range of customer designs.

Figure 2. An optional hardware coprocessor augments the primary core's resources with 512 additional 16x16 MACs.
The hardware accelerator's presence (if included in a particular SoC implementation) and capabilities are comprehended and leveraged by the CDNN2 toolset. It's intended only for convolution layers, with all other deep learning processing, such as normalization and pooling, handled by the CEVA-XM6. The 512-MAC coprocessor interfaces to the primary processor core over an AXI bus-based CEVA-Connect scheme, as would a customer-specific TCE (tightly coupled extension) per Figure 1. To that point, it's managed by the primary processor, and also does not have a standalone channel to main memory; all data movement relies on the primary processor as an intermediary. Note, too, that although the MAC coprocessor is AXI-cognizant, it cannot be separately licensed by a customer. It must be used in conjunction with a primary CEVA processor core, although it's compatible with both the CEVA-XM6 and the CEVA-XM4.
Bar was unwilling to provide either absolute or relative silicon area metrics for either the XM6 or the coprocessor, aside from suggesting that the new core is not "significantly bigger" than the XM4 on the same process, particularly when its disproportionally increased performance (estimated to be up to 3x for vector-heavy kernels, 2x on average, along with a 50% improvement in control code performance) is considered. CEVA-XM6 targets the same 16 nm and 28 nm processes as its predecessor, along with the same clock speed range (1.2 GHz peak, 500-800 MHz typical). Bar also declined to provide CEVA-XM6 power consumption estimates.
Wrapping up, the conversation turned to support for data types smaller than 16 bits. Bar acknowledged that Google and others have recently published compelling research results on this subject, but suggested that these techniques aren't yet ready for implementation in real-life production designs due to lingering concerns about degraded accuracy. When these concerns are addressed, Bar stated, CEVA would be ready with requisite silicon support. But for now, the company is confident in its 16-bit focus.
CEVA-XM6 will be available for lead customer licensing later this quarter, with broader availability slated for 2017. For more information, check out the following promotional video from the company (Video 1):
Video 1. The CEVA-XM6 fifth-generation vision processing core
Add new comment