
With the MM3101, launched at the January 2012 Consumer Electronics Show, silicon IP supplier CEVA for the first time provided a processor core with instructions and other features specifically tailored for computer vision algorithms. (The precursor MM2000 and MM3000 were focused predominantly on encoding and decoding images and video). Later, the company released a super-resolution algorithm for computational photography, along with a software framework that enables Android applications to efficiently tap the MM3101 to accelerate multimedia functions (Figure 1).
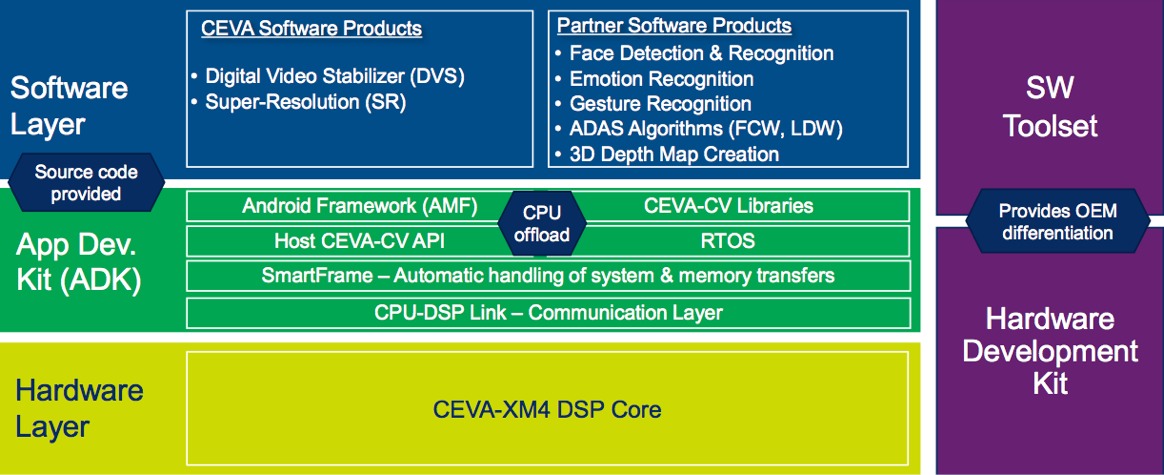
Figure 1. Various software layers, running on a CEVA vision processor core silicon foundation, enable offloading diverse computer vision operations under Android and other operating systems.
Over the past several years, the company has licensed the MM3101 to a number of customers and learned a great deal about various computer vision applications. See below, for example, for some of the MM3101 demonstration videos from the Embedded Vision Alliance:
The outcome of CEVA's vision application education is the recently released next-generation CEVA-XM4. Like the MM3101, the XM4 is targeted for implementation in 28 nm-based SoCs. However, CEVA believes that the function-dependent improvements over the MM3101 are significant (Table 1):
- Up to an 8x overall performance gain
- A 20% higher peak clock frequency (1.2 GHz vs 1 GHz, due to a 14-vs-10 stage pipeline)
- 2.5x the performance per square mm of silicon area, and
- 35% better average performance per mW
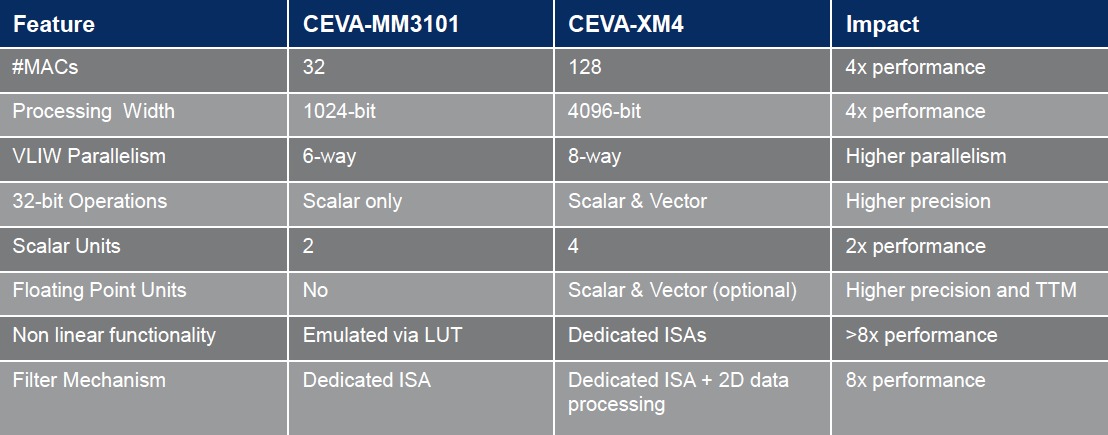

Table 1. Architecture (top) and memory and system (bottom) feature set comparisons highlight the CEVA-XM4 improvements versus the MM3101 precursor.
Some of the XM4 improvements are fairly predictable, considering both the company's past evolutions of other processor core families (communications and audio, for example), as well as the generational advancements of the company's competitors (Figure 2). The number of integrated MACs has quadrupled (from 32 to 128), as has the commensurate aggregate processing width (from 1,024 to 4,096 bits); the architecture's VLIW parallelism has also increased from six-way to eight-way. 32-bit operations, previously supported only by the scalar processing units, are now also handled by the vector processor units. The number of scalar units has doubled, from two to four. And both processor unit types now also implement not only fixed-point but also (optionally) single- and double-precision floating point arithmetic.
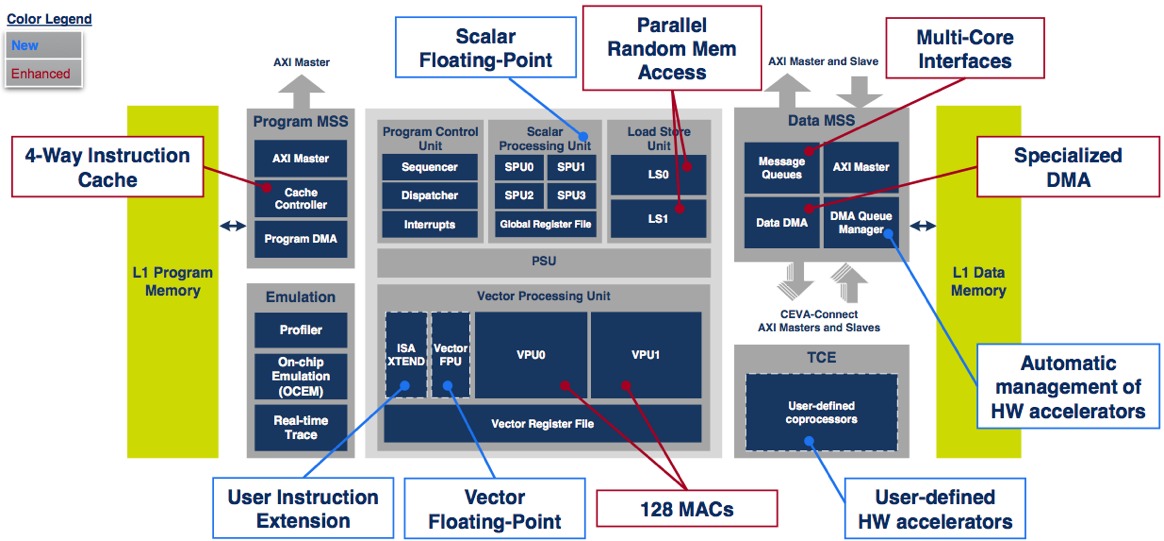
Figure 2. Floating point-capable scalar and vector processors, user customization capabilities and additional arithmetic resources are among the XM4 enhancements, developed after implementing various vision algorithms on the MM3101.
Other improvements are more subtle although, says CEVA, no less impactful. Like the XC4000 communications processor core and TeakLite-4 audio processor core that preceded it, the XM4 imaging and vision processor core now supports optional user instruction extensions, as well as user-defined hardware accelerators (TCEs, for tightly coupled extensions). And nonlinear functions, previously emulated via lookup tables (LUTs), are now directly supported via CEVA-supplied, hardware-accelerated instructions.
Memory has also received CEVA's attention. The integrated cache controller, formerly implementing a two-way set associative function, is now four-way set associative and non-blocking (i.e. transactional) in nature. The MM3101 had two memory buses, one for vector operations and the other for scalar, 256- and 128-bits in width. XM4 migrates to a unified memory approach, among other things enabling more straightforward data interchange between the two processing subsystems. And several enhanced memory access mechanisms optimize the bus's bandwidth efficiency and power consumption, as well as the overall XM4 processing efficiency.
The first, parallel random memory access, was developed after analyzing the access profiles of common vision algorithms (Figure 3). The XM4's "scatter-gather" capability enables loads or stores of vector elements into non-consecutive memory locations in a single cycle. An image histogram operation, for example, requires random accesses to memory on a per-pixel basis, according to CEVA. Although the operation is very simple, involving incrementing a set of counters, it cannot be efficiently vectorized without appropriate memory access support. The second, two-dimension data processing, takes advantage of pixel overlap in filtering and other image processing operations, by reusing the same data to produce multiple outputs without reloading it from memory multiple times.
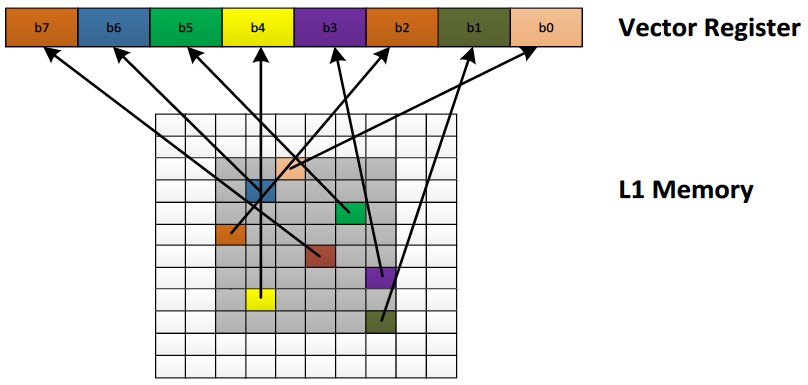
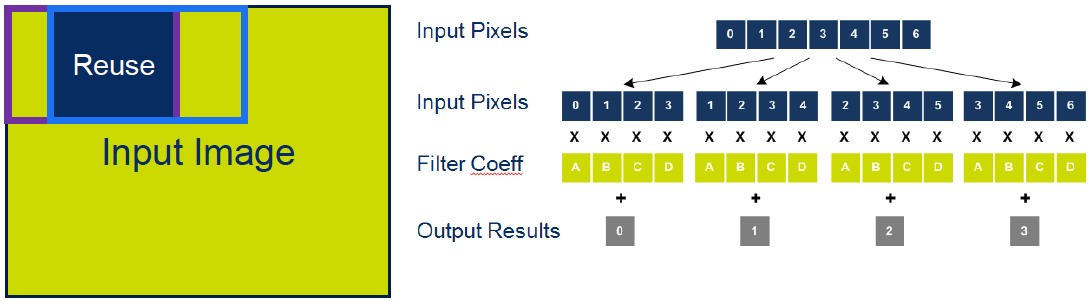
Figure 3. Parallel random memory access (top) and 2D data processing support are two of the features intended to optimize memory bus bandwidth, power consumption, and performance.
CEVA reports performance improvement results for some common computer vision algorithms, supporting the earlier-mentioned "up to 8x overall performance gain" claim (Figure 4). The boosted performance of the XM4 will enable processing of higher resolution or higher frame rate video streams, or concurrently running multiple functions or algorithms. The algorithms shown in Figure 4, along with other conceptually similar ones, form the foundations of applications in the target markets that CEVA is pursuing with the XM4: smartphones and tablets, other consumer electronics devices (computational photography, etc.), security and surveillance, and automotive safety (ADAS). All are experiencing explosive growth, leaving CEVA and its vision processor competitors well positioned to benefit from the booming demand.
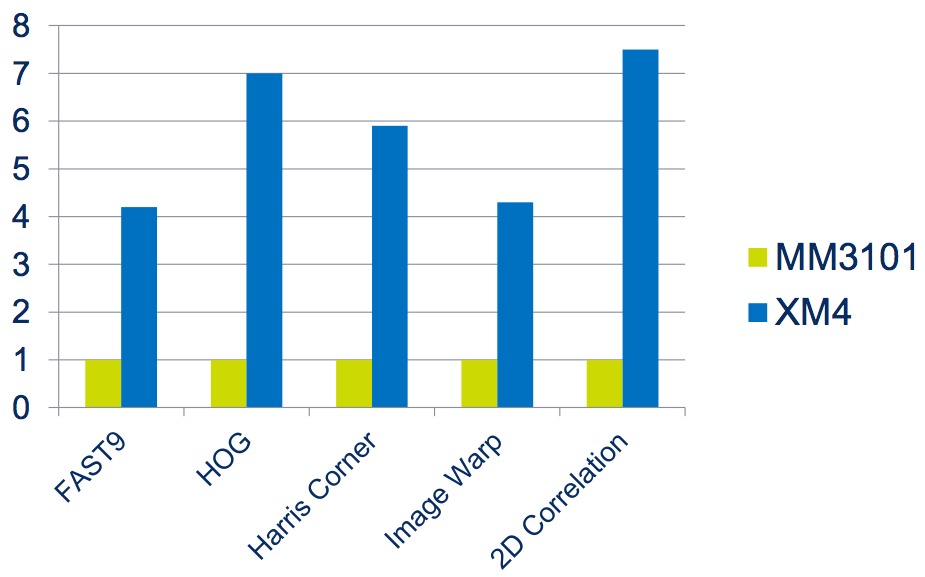
Figure 4. Common computer vision functions, used by high-growth target applications and markets, see significant performance boosts on the XM4, according to CEVA.
Add new comment