
Imagination Technologies' new PowerVR Furian graphics microarchitecture is the company's most significant advancement since 2011's Rogue, which has formed the microarchitecture foundation of multiple subsequent product families (Figure 1). While still based on the tile-based deferred rendering (TBDR) approach that dates back to the mid-1990s, Furian is tailored for not only the increasingly demanding graphics performance requirements of modern SoCs and systems based on them but also their broader GPGPU application acceleration needs.
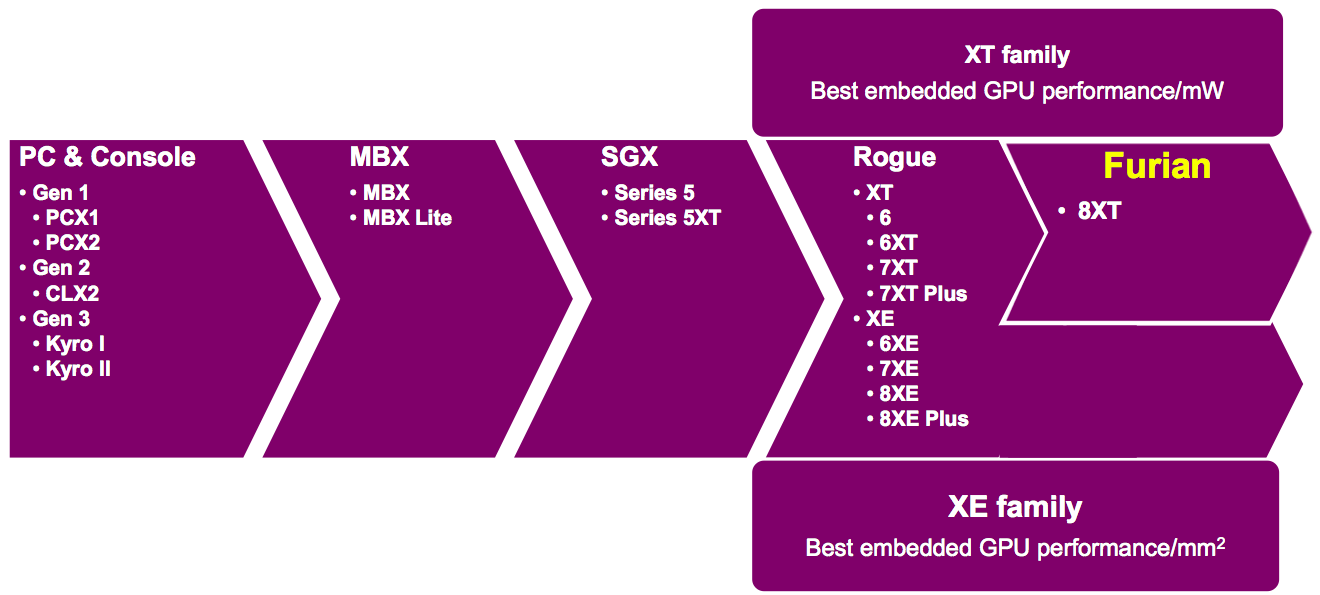
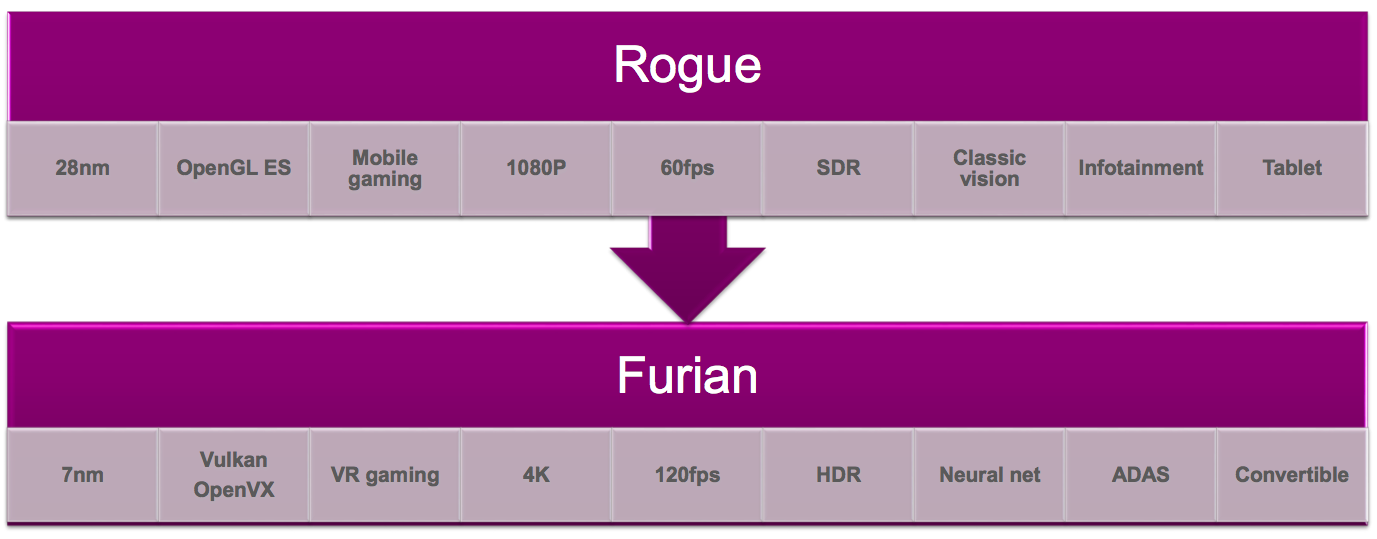
Figure 1. Imagination Technologies' new Furian microarchitecture will initially enter the company's graphics core product line at the high end (top), where it will service a significantly expanded and otherwise more demanding set of application requirements than those that existed when the Rogue microarchitecture precursor was introduced at the beginning of this decade (bottom).
According to Chris Longstaff, the company's Senior Director of Product & Technology Marketing for PowerVR, at the core (pun intended) of Furian's advancements is its more modular layout approach (Figure 2). Rogue's "hub"-focused architecture was theoretically scalable up to 16 function clusters in size; real-life to-date implementations have implemented up to 12 clusters. However, as the number of clusters increases, the resultant long routing paths with increasing levels of congestion have both bottlenecked the performance and power consumption and bloated the die size of high-end GPU core designs. Furian, in contrast, exploits the fast logic switching speeds, equally quick routing propagation delays and abundant routing metal layers of advanced process lithographies by relying on a comparatively short module-to-module routing scheme that minimizes congestion.
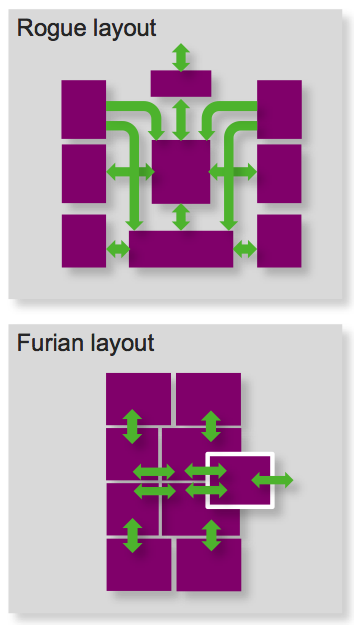
Figure 2. The transition to a more local routing-dominated layout approach will, Imagination Technologies believes, deliver benefits in silicon area efficiency, performance and power consumption, especially in more complex core configurations.
Plenty of innovation has also occurred within each function cluster; even a high-level block diagram reveals some of it (Figure 3). The various data masters along the left side of the block diagram now operate fully asynchronously to each other and can work on different tasks, thereby enabling the GPU potentially to do more total work per clock; notably, the GPU Compute data master is now an equal partner to its more graphics-focused siblings. And the texture and data caches are now distinct, versus unified with Rogue, for more efficient utilization of each. Furian-based GPU core proliferations to come will vary both the number of unified shading clusters (USCs) per shader processing unit (SPU) and the number of SPUs per GPU.
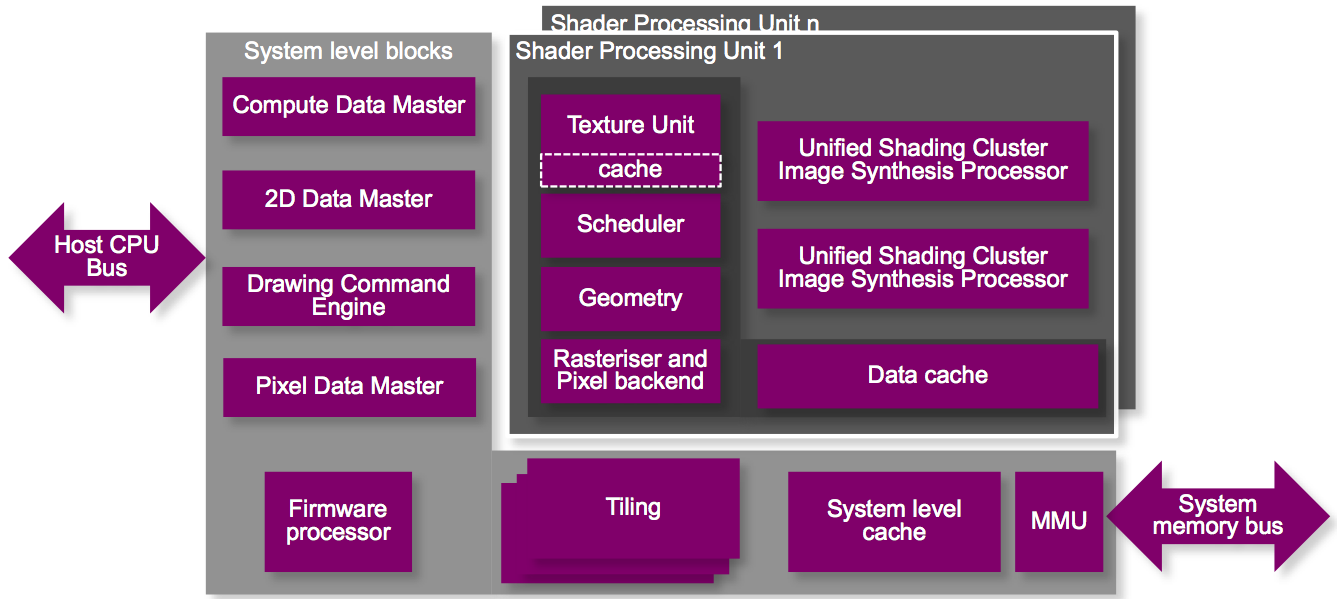
Figure 3. Expanded asynchronous parallel processing support within the core will lead, Imagination Technologies believes, to more heterogeneous work done per clock cycle, a particularly attractive attribute in GPU compute applications.
Architectural optimization also exists within each USC (Figure 4). Rogue was a 16-wide SIMD architecture; Furian conversely employs a wider 32-pipeline approach. However, whereas with Rogue each ALU pipeline contained two full multiply/add (MAD) units, Furian pipelines instead combine a single MAD with the simpler multiplier (MUL) function. Imagination Technologies found that application software inefficiently leveraged the dual-MAD processing potential in Rogue; the combination of a MAD and MUL is also more area-efficient from both routing and control logic standpoints. Reflective of this pipeline evolution, Imagination Technologies has also extended the ISA to effectively harness the MAD-plus-MUL cluster in both traditional graphics and newer GPGPU applications.
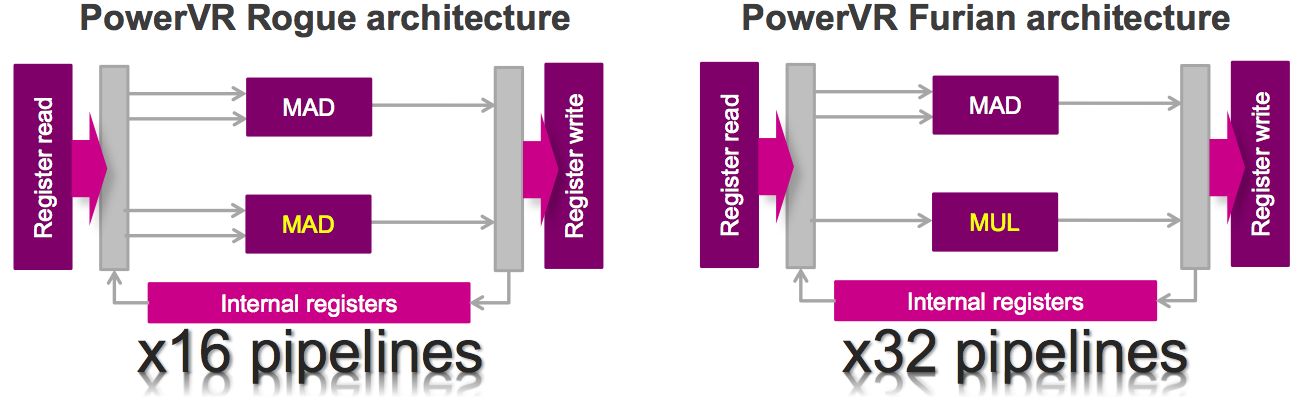
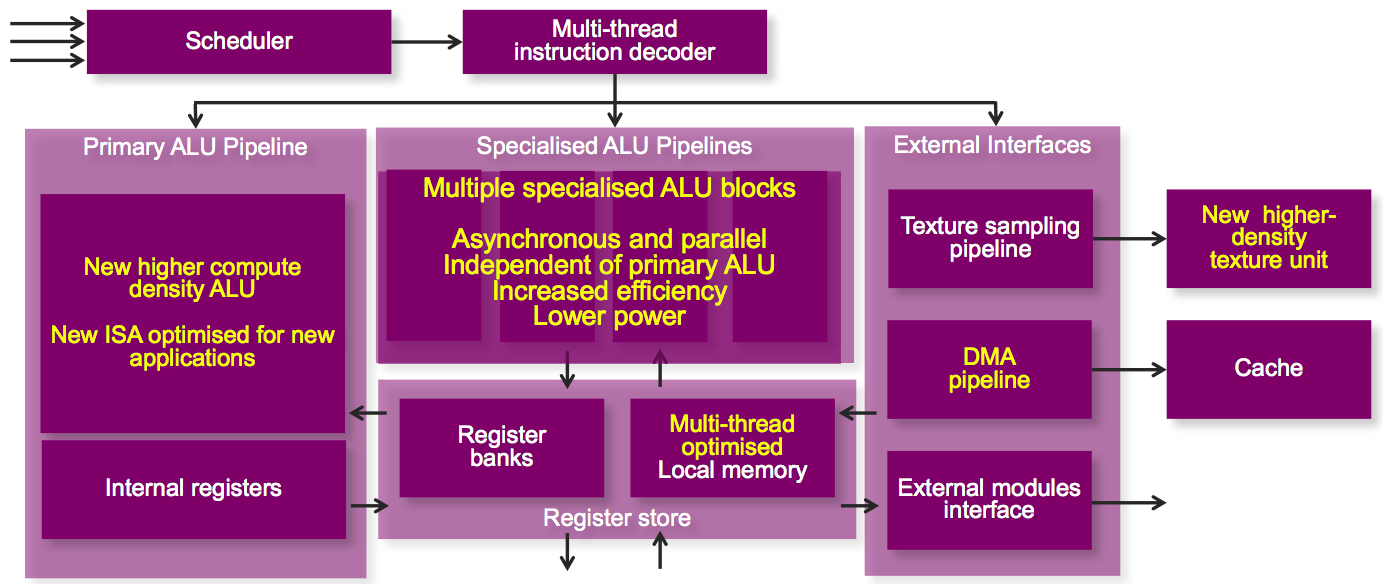
Figure 4. Furian's pipeline architecture is simultaneously wider (from a SIMD standpoint) and simpler (from an ALU standpoint) than was the case with Rogue (top); additional enhancements come from the more robust DMA controller and local memory access capablities (bottom).
Additional USC enhancements include an asynchronous DMA controller, along with multi-thread-optimized (i.e. "scatter-gather" access-capable) local memory, both advancements particularly beneficial to computer vision and other GPU compute tasks. Furian is also a more easily and efficiently extensible architecture than was Rogue; function-specific pipelines can be tightly integrated with the GPU via a combination of generalized routing fabric and a control interface bus (Figure 5). The concept was showcased on Rogue via ray tracing unit augmentation in the PowerVR Wizard product line; the implementation will be even more robust on Furian, according to Longstaff. And the same concept is equally applicable to other specialized coprocessors; the company's Raptor ISP, for example, or a licensee's custom logic.
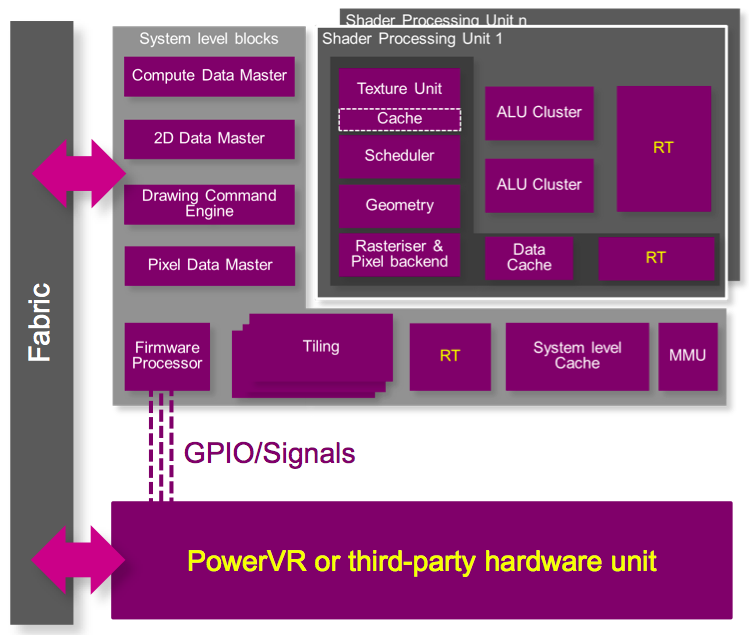
Figure 5. The GPU can be further expanded by a SoC licensee through the addition of paired co-processors for ray tracing, image processing, and other functions.
The end result of all of this optimization effort, Imagination Technologies claims, is an architecture that will deliver notable improvements in both raw performance and performance/watt metrics, versus both precursor Rogue-based core designs and those of competitors (Figure 6). This will especially be the case, Longstaff believes, at the high end of the market, where Furian's finer-grained, short routing-dominated multi-cluster scheme will scale more efficiently from both silicon area, performance and power consumption standpoints than do competitors' coarser-grained legacy approaches.
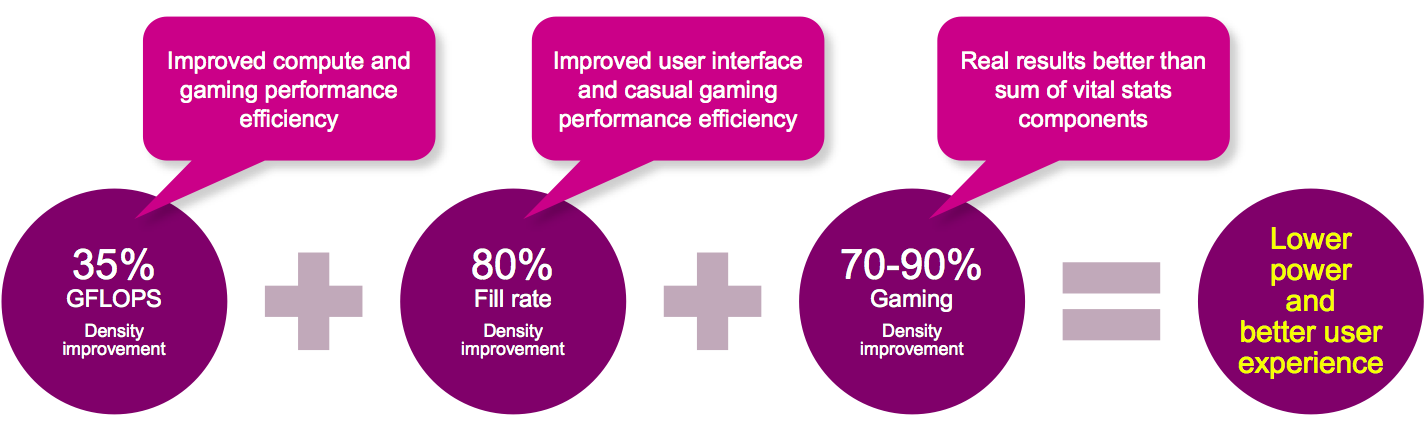
Figure 6. Imagination Technologies forecasts that Furion-based graphics cores to come beginning late this year will deliver notable performance and other improvements in comparison to Series7XT Plus (Rogue-based) predecessors, even in the same process technology, at the same clock frequency, and for cores with a similar silicon area budget.
When asked about competitors, Longstaff listed predictable names such as ARM (Mali) and VeriSilicon (Vivante), along with SoC-level competition such as Qualcomm and NVIDIA. And, as Imagination Technologies continues to broaden its GPUs' processing capabilities beyond conventional graphics, enabled by both silicon advancements and planned ongoing support for APIs such as OpenCL and OpenVX, companies like Cadence (i.e. Tensilica), CEVA and Synopsys will also more fully join the competitor list.
As for how Furian-based GPUs will stack up both against their Rogue-based predecessors and against competitive offerings, Longstaff forecasts that we won't have long to wait; beta RTL for the first Furian-derived cores is in initial licensee's hands, with SoCs expected early next year and end system products by late 2018. That licensee list may not, however, include longstanding (and largest) customer Apple, who more recently informed Imagination Technologies that "it will no longer use the Group’s intellectual property in its new products in 15 months to two years time, and as such will not be eligible for royalty payments under the current license and royalty agreement."
Add new comment