
At last year's Embedded Vision Summit, Cadence unveiled the Tensilica Vision P6 DSP, which augmented the imaging and vision processing capabilities of its predecessors with the ability to efficiently execute deep neural network (DNN) inference functions. Cadence returned to the Summit this year with a new IP offering, the Vision C5 DSP core, focused exclusively on deep neural networks. Vision C5 is intended for use alongside another core, such as the Vision P6, which will handle image signal processing and non-deep-learning-based computer vision algorithms. However, the company hopes that the burgeoning popularity of deep neural networks, along with their ever-increasing computation demands, will translate into robust demand for a DNN-specific processing engine (Figure 1).

Figure 1. Expanding use of deep neural networks for vision and other machine perception tasks, along with the increasing computation demands of these algorithms, combine to create a compelling opportunity for neural network-focused processing engines such as Cadence's new Vision C5.
At first glance, this year's Vision C5 and last year's Vision P6 might seem indistinguishable (Figure 2). However, according to Pulin Desai, the company's Director of Product Marketing, key differences exist, tailored for target workloads. Vision C5 contains 1,024 8x8 multiply-accumulate units (MACs), for example, versus 256 8x8 MACs on Vision P6. (These can be configured as 512 16x16 MACs on Vision C5, versus 256 16x16 MACs on Vision P6). Thanks in part to this increase in MACs, Cadence estimates a 5x increase in peak computation, from 200 GMAC/sec on Vision P6 to 1 TMAC/sec on Vision C5. Vision C5 also provides 4x the number of accumulator register files as Vision C6, along with being a 4-way VLIW, 128-way 8-bit SIMD architecture (versus 64-way SIMD on Vision P6).
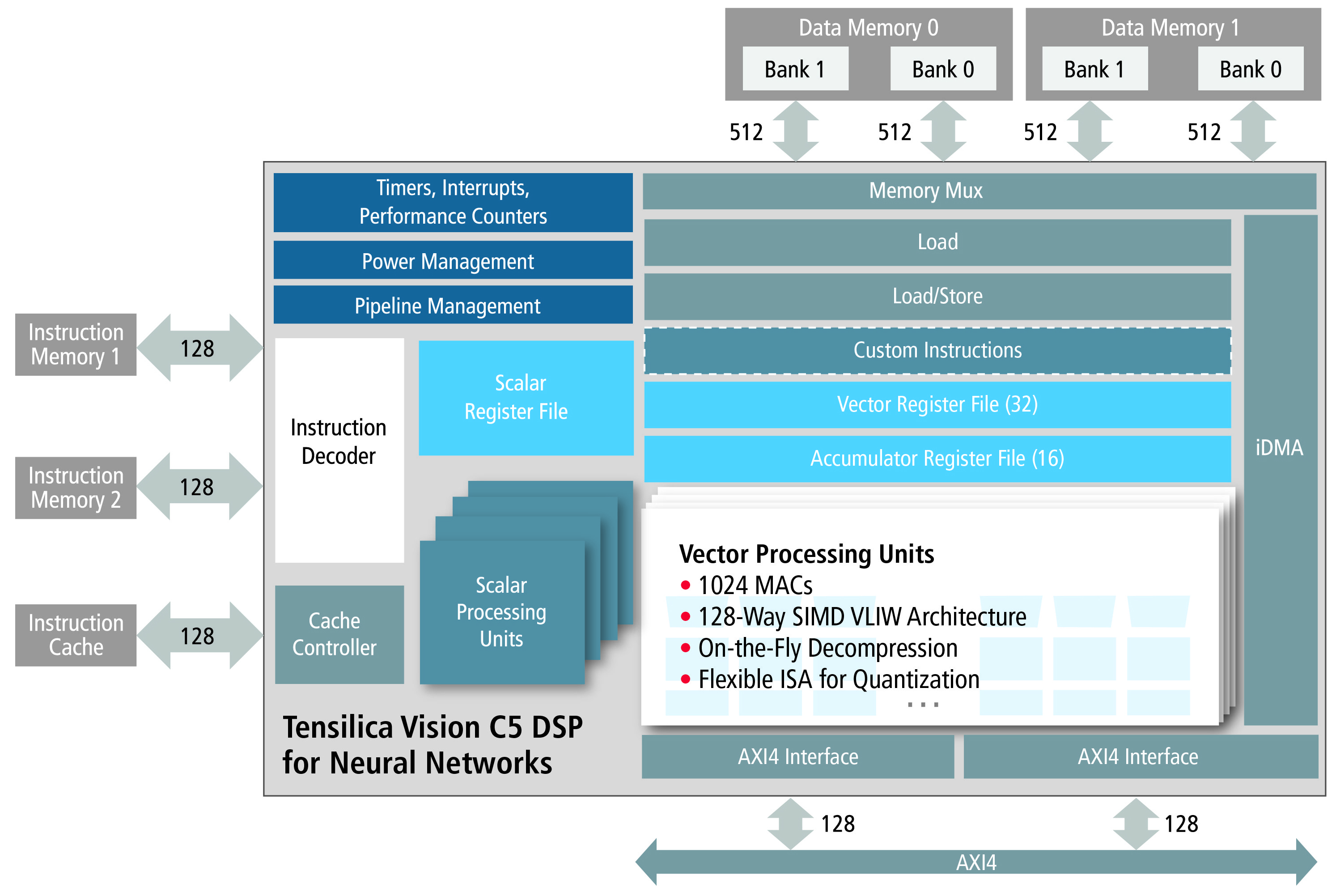
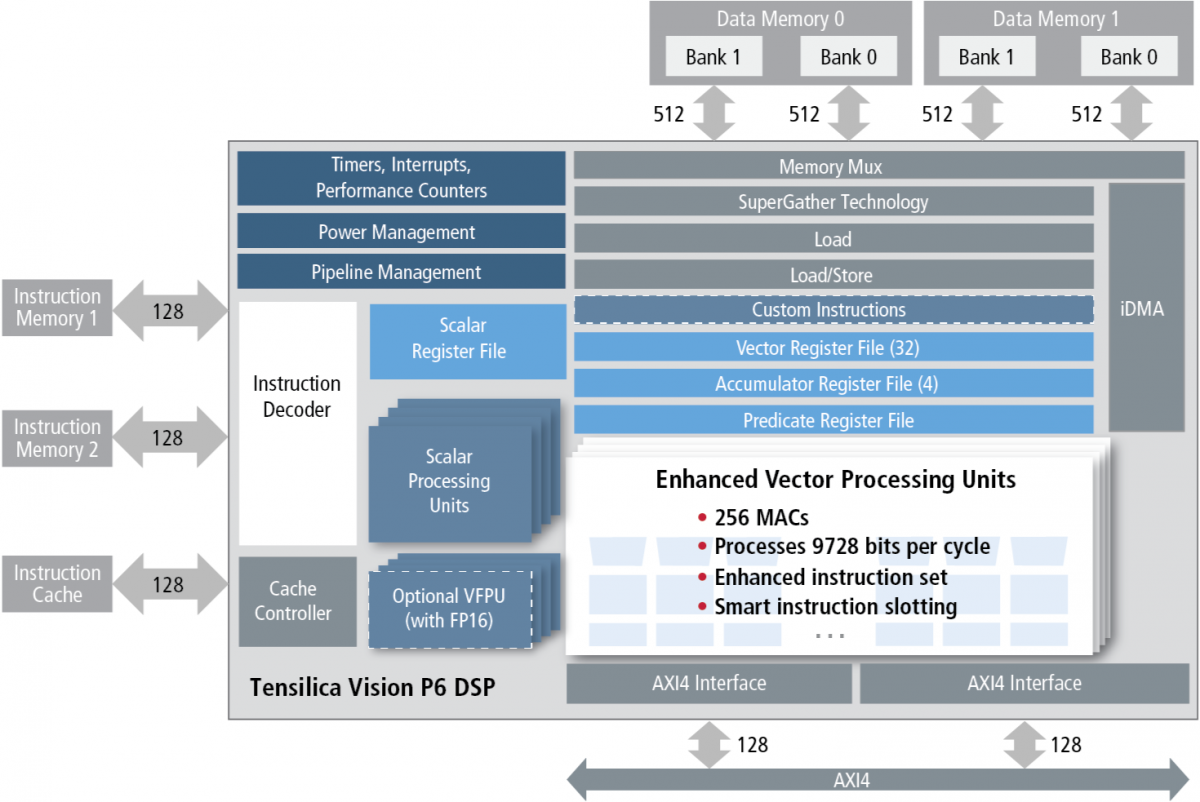
Figure 2. Cadence has tailored Vision C5 (top) for deep neural network inference by expanding its MAC resources and removing functions deemed unnecessary in comparison with the Vision P6 (bottom).
Absent from Vision C5 is its Vision P6 predecessor's SuperGather enhanced memory controller as well as optional vector floating-point unit (FPU), which Desai claims are unnecessary in the new core's deep learning-focused target applications. To the latter point, Desai grants that the company is turning its back on legacy CPU- and GPU-based floating-point deep neural network code from OpenCV and other libraries, but he points out that Google's TPU inference processor (for example) is similarly integer-only. As a result of this feature set slimming, Vision C5 is estimated to consume less than 1 mm2 of silicon area on a 16 nm process (Desai declined to provide a comparative size estimate for Vision P6 on the same process).
In a recent briefing, Cadence's Desai took pains to point out that a deep neural network-augmented imaging and vision DSP such as his company's Vision P6 or CEVA's XM-6 remains an acceptable solution for applications that leverage both classical computer vision techniques and deep neural network algorithms or make limited use of deep neural networks. However, these more general-purpose DSPs, along with hard-wired deep neural network "accelerators," as he refers to them, are only capable of handling the convolution and fully connected layers of a neural network; normalization and pooling layers remain the responsibility of a separate engine, typically a CPU or GPU (Figure 3). Repetitive data movement between the two processing engines is performance-limiting and power-consuming, he suggests, and consumes CPU and GPU resources that might otherwise find use elsewhere. In contrast, Desai says that Vision C5 is capable of single-handedly processing all neural network layers.

Figure 3. Deep neural network accelerators that are only capable of processing some neural network layers generate performance- and power-sapping data traffic to and from a companion CPU or GPU, according to Cadence.
Vision C5 is perhaps more directly comparable to the standalone (and optional) deep learning coprocessor in Synopsys' DesignWare EV6x IP family. Here, one primary distinction comes from comparative MAC counts. If 8-bit precision will suffice, Cadence provides 1,024 MACs, while Synopsys' CNN engine is configurable with no less than 12-bit precision and outfitted with up to 880 MACs. The silicon area taken up by Synopys' CNN engine on a 16 nm process such as that specified by Cadence is unknown.
Reminiscent of CEVA's CDNN2 toolset, Cadence also offers an automated software flow intended to convert a neural network algorithm description into a Vision C5-optimized implementation (Figure 4). Unsurprisingly, the popular Caffe and TensorFlow frameworks have gained Cadence's initial attention; other frameworks (such as just-announced Caffe2) are under consideration. Vision C5 is now available for evaluation and licensing; Desai reports that early customer engagements are underway.
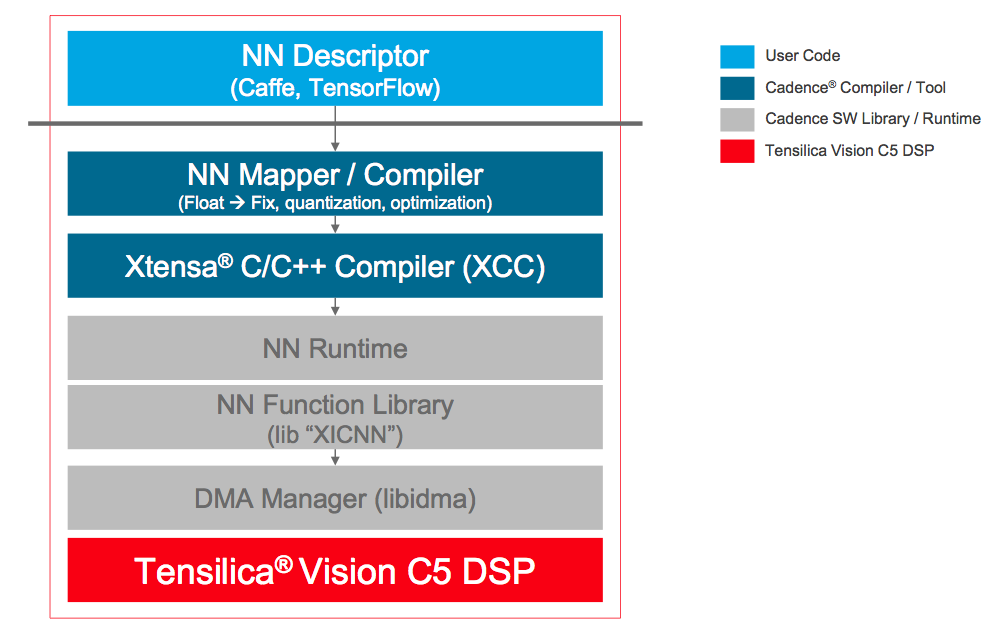
Figure 4. Vision C5's automated software optimization flow currently prioritizes the Caffe and TensorFlow frameworks; other frameworks are under consideration.
Add new comment