
Just last October, Cadence announced the then-latest generation in its computer vision processor core roadmap, the Tensilica Vision P5. Only seven months later, the Vision P5 has been superseded by the Vision P6 (Figure 1). This rapid product development pace reflects the equally rapid expansion and evolution of embedded computer vision applications. According to Cadence’s Chief Technology Officer Chris Rowen and Director of Product Marketing Pulin Desai, the company's new vision core is the beneficiary of significant experience amassed from an abundance of customers and applications. It's especially optimized for convolutional neural networks (CNNs) and other deep learning techniques.
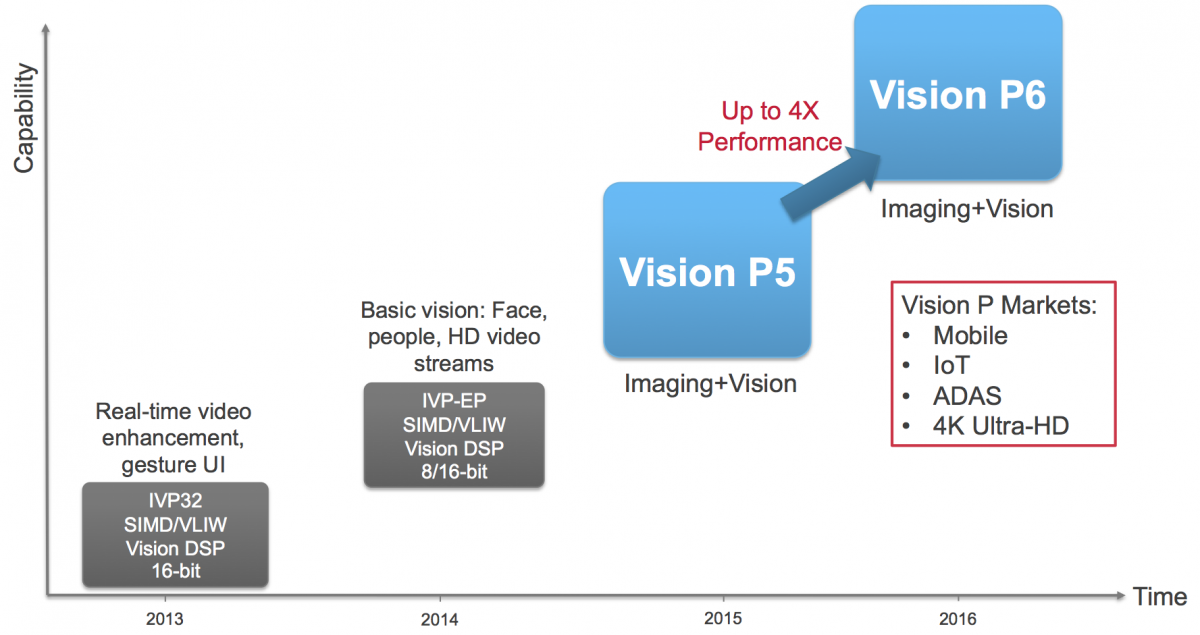
Figure 1. Only seven months after the introduction of Cadence's Tensilica Vision P5 core, the company has released the Vision P6 successor.
Cadence's analysis of its existing design wins suggested that CNNs implemented on its existing processors were often performance-limited by the amount of on-core multiplier resources. FIR filters and matrix multiplication functions, also common in computer vision applications, exhibited similar constraints. As a result, in Vision P6 the company doubled the number of 16x16 and 16x8 multiply-accumulate (MAC) operations per cycle, respectively to 64 and 128, and quadrupled the number of 8x8 MACs per cycle to 256 (Figure 2).
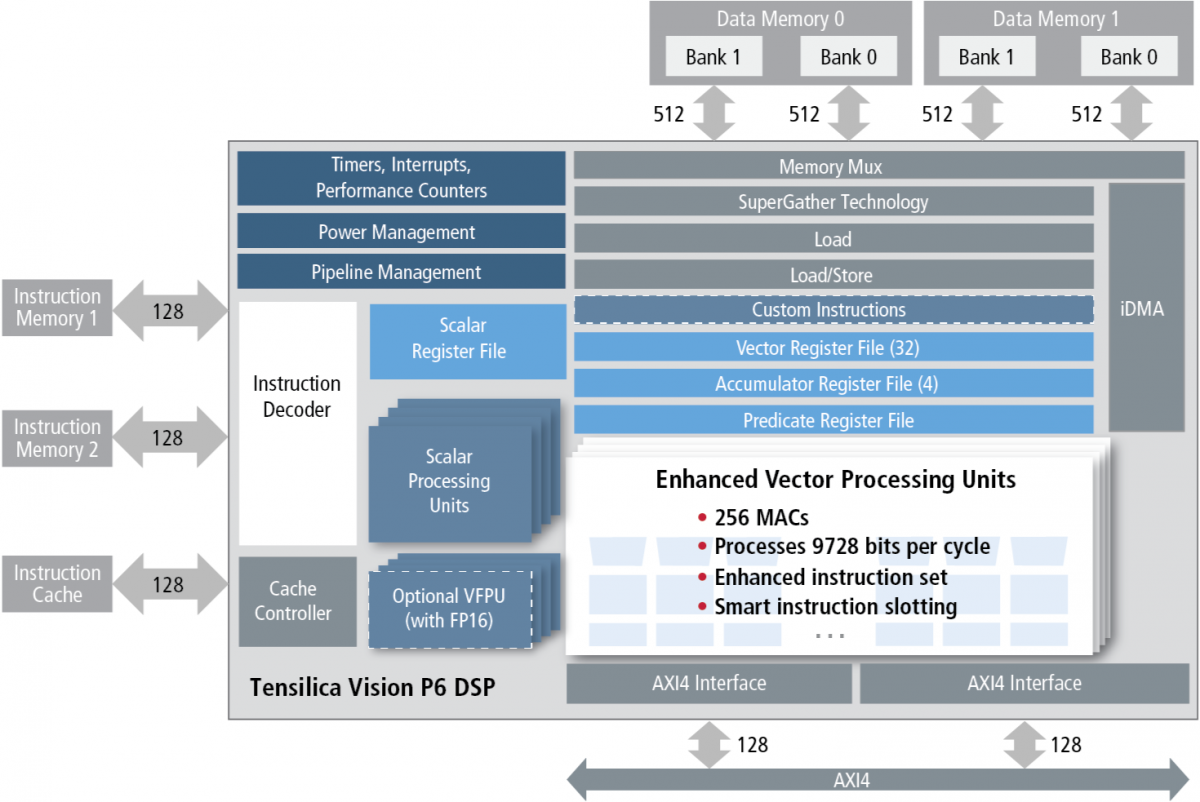
Figure 2. A significant expansion in the number of integrated multiply-accumulators is a key Vision P6 enhancement, along with increased floating-point precision flexibility.
Vision P6 retains (with comparable speed and bus width) its predecessor's then-newly-added "SuperGather" memory controller, which is performance-optimized for the non-contiguous memory access patterns commonly found in computer vision functions. Since matrix multiplication (for example) involves a high degree of operand reuse, Rowen and Desai explained, the on-core MAC resource expansion could take place without increasing the system memory bandwidth required for this operation. Increasing the number of on-core MACs also didn't, according to them, require a tangible increase in the required amount of on-core registers or routing resources. As such, the overall core size increase for Vision P6 versus Vision P5, on the same process node and with both cores otherwise identically configured, is only around 15%.
Speaking of core configuration, with Vision P6 Cadence also expands the versatility of the optional vector floating-point unit (FPU) also first seen in Vision P5. In the prior generation architecture, the FPU was 32-bit only, but the company's subsequent learning revealed that such high precision was often overkill. As such, the FPU in Vision P6 also supports 16-bit precision, leading to both a computational throughput boost and memory space savings when in FP16 mode. The FPU remains optional, because Cadence's research continues to suggest that fixed-point arithmetic is often sufficient and including the FPU in the core brings an unspecified die size impact. However, Rowen and Desai suggested that its inclusion simplified the porting of algorithms originally intended for GPUs, as well as floating point-centric OpenCV algorithms.
Courtesy of Vision P6's Xtensa flexible architectural foundation, additional instructions have been implemented in this generation reflective of added and enhanced core resources such as optional FP16 mode, as well as to reflect other common computer vision customer requests. With that said, existing Vision P5 code will run unchanged on Vision P6. However, by leveraging the various improvements in this latest-generation core, Cadence estimates that you'll achieve up to a quadrupling in peak neural network processing performance, with both core generations running at the same clock speed (1.1 GHz) and on the same process node (16 nm FinFET). The company already has multiple licensee engagements underway, and plans to finalize the core's design by the end of Q3.
Add new comment