
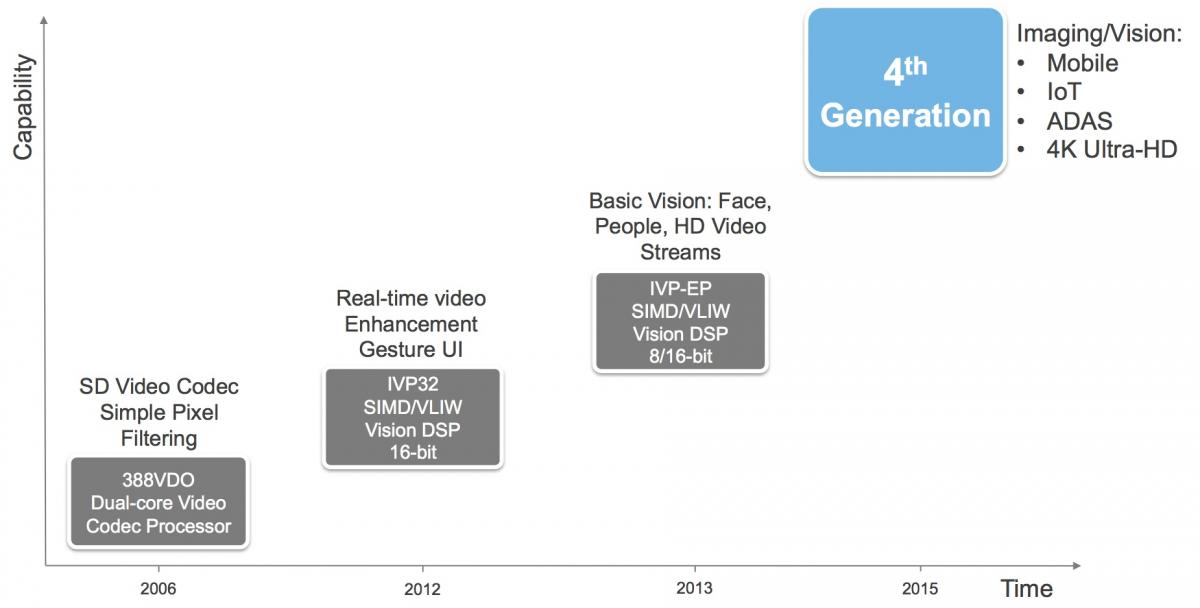
In 2013, Tensilica (subsequently acquired by Cadence) released its second-generation image processing IP core, the IVP, which also supported modest computer vision capabilities (Figure 1). One year later came the IVP-EP, which supported increased data precision flexibility, boosting overall performance in many applications and therefore further expanding the core's vision processing function reach. And in October of this year, Cadence further extended the product line, unveiling its latest Tensilica Vision P5 DSP.
INSERT CadenceBlockDiagram.jpg
Figure 1. Vision P5 is Cadence's latest-generation core for imaging, video and vision processing (top). Enhancements include an improved memory controller, an optional floating-point unit, and increased parallelism (bottom).
The Vision P5's memory interface represents one of the more notable architecture upgrades compared to its predecessors. While its 1,024-bit bus width is unchanged, its effective bandwidth is significantly increased, according to product line director Dennis Crespo. This is because of its new “SuperGather” memory controller technology, conceptually similar to the "scatter-gather" support built into competitor CEVA's XM4 vision processor core released early this year. The underlying motivation for both companies' advancements is the same: algorithms with non-contiguous memory access patterns, such as image warping, edge tracing, and non-rectilinear patch access are common in computer vision, and the ability to efficiently read and write such addresses in parallel is therefore highly advantageous (Figure 2). Specifically, Crespo noted in a recent briefing that historically, between 50% and 60% of the clock cycles of Cadence’s imaging and vision cores had been devoted to rotates, shifts, and other software-based data alignment operations; Vision P5's hardware-accelerated support for these relatively rudimentary alignment tasks frees up the processor core for higher-value vision tasks (now with greater than 90% utilization on average, according to Crespo).
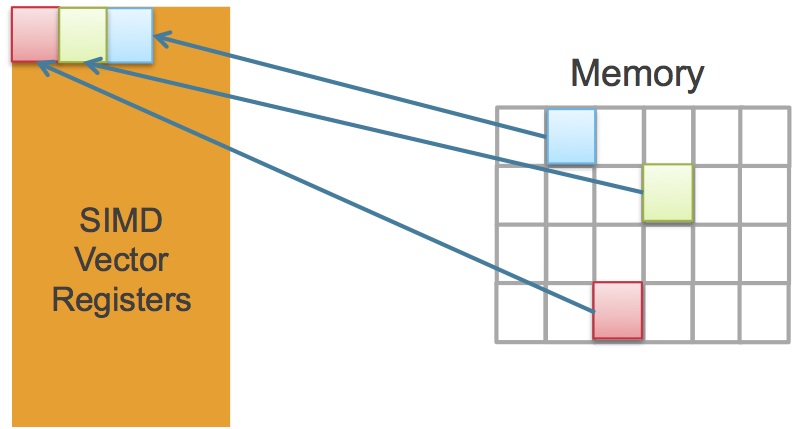
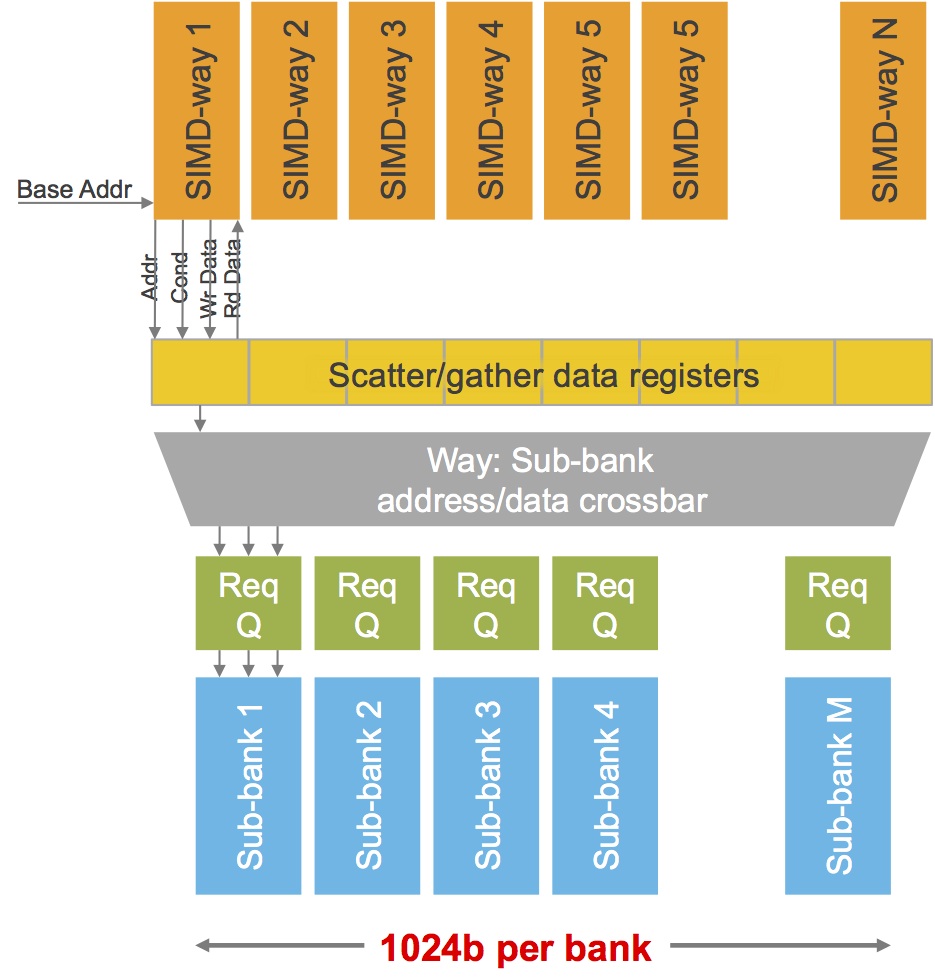
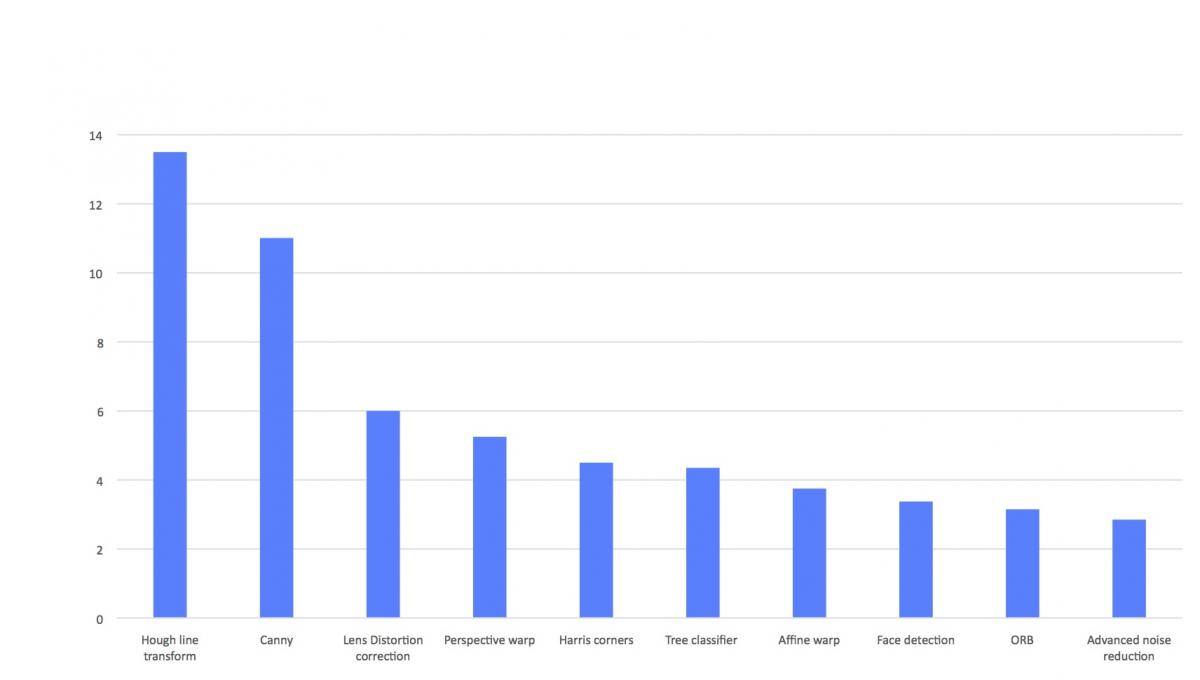
Figure 2. Many computer vision functions access memory in a non-sequential manner (top), which Cadence's new "SuperGather" memory controller strives to manage with minimal software overhead (middle), one of the key factors in the core's claimed performance advantage over the prior-generation offering (bottom).
The other notable addition is actually a feature set option: a 32-bit vector floating-point unit (FPU) that runs in parallel with the processor's primary scalar and vector arithmetic resources. Crespo noted that a large percentage of the functions in OpenCV (the open-source computer vision library) and OpenCL (a heterogeneous processing language standard managed by the Khronos Group) are inherently floating point in nature, befitting their PC heritage. While fixed-point conversion is possible, doing so often incurs project schedule delays and other impacts; Crespo indicated that approximately 80% of the initial Vision P5 customers were therefore choosing to include the single-precision FPU, which Cadence says is capable of 1 GHz operation in a 16 nm process, achieving a peak of 32 GFLOPS/second.
In other respects, the upgrades the IVPEP to the P5 are more modest in nature. The processing pipelines are deeper this time around, although Cadence declined to give specific before-or-after stage counts. The upside (albeit with unknown average instruction-per-clock impacts) is speed; on 16 nm, the Vision P5 pipeline runs at 1.1 GHz, versus 600 MHz for the IVP-EP on the same process foundation, according to Cadence. The architecture is also increasingly parallel, migrating from 96 to 256 peak ALU operations per cycle, for example, and also now capable of simultaneously executing a scalar instruction and up to four vector instructions (each with up to 64-way SIMD parallelism) per cycle. Many operations now require fewer cycle counts to complete, and DMA throughput has also been enhanced.
All-important power consumption wasn't forgotten in the push for higher computer vision performance. Clock gating is now more comprehensive throughout the core, for example, and data gating is now implemented throughout the data path. This combination of improved performance and lower power consumption delivers, Cadence believes, a reduction of up to 5x in average energy consumption for common computer vision functions, versus the IVP-EP (Figure 3).
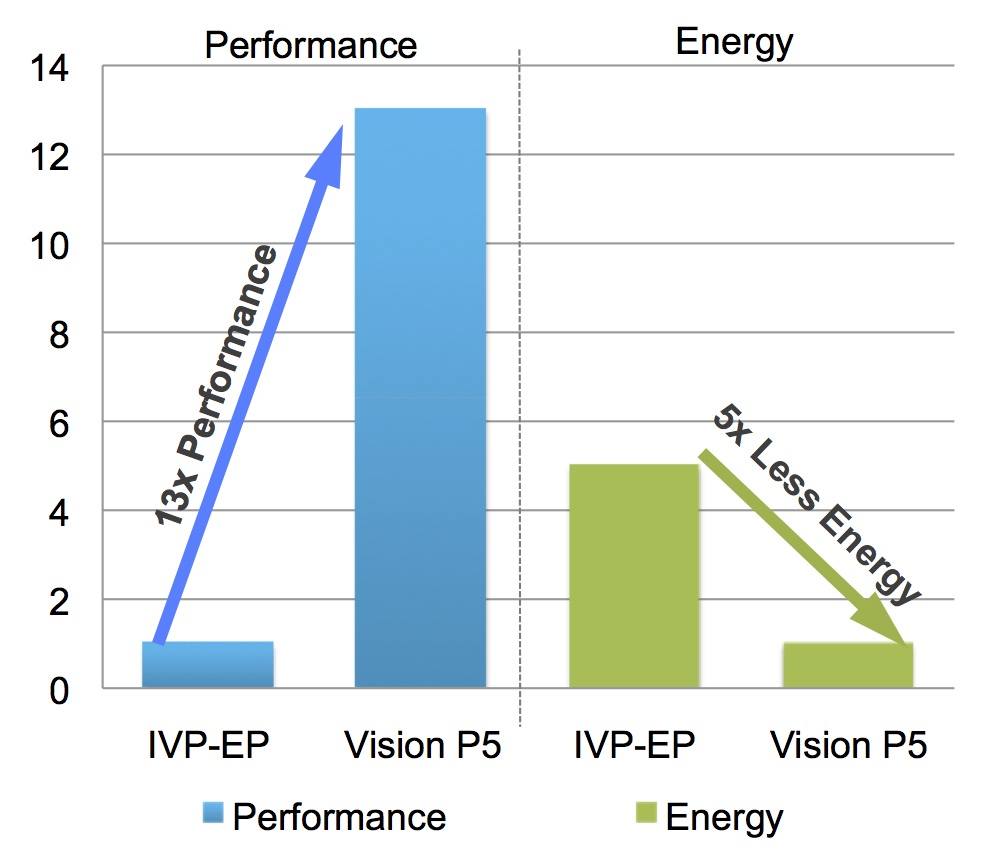
Figure 3. Higher clock speeds, improved operation-per-clock efficiency, and lower average power consumption also combine to translate into enhanced generation-to-generation energy efficiency, according to Cadence.
According to Crespo, the base P5 core is less than 2 mm2 in size in a 16 nm process, with minor additional area increments for the optional FPU and cache and instruction memories. Customers with high-end processing requirements are incorporating multiple Vision P5 cores, Crespo claims (Figure 4).
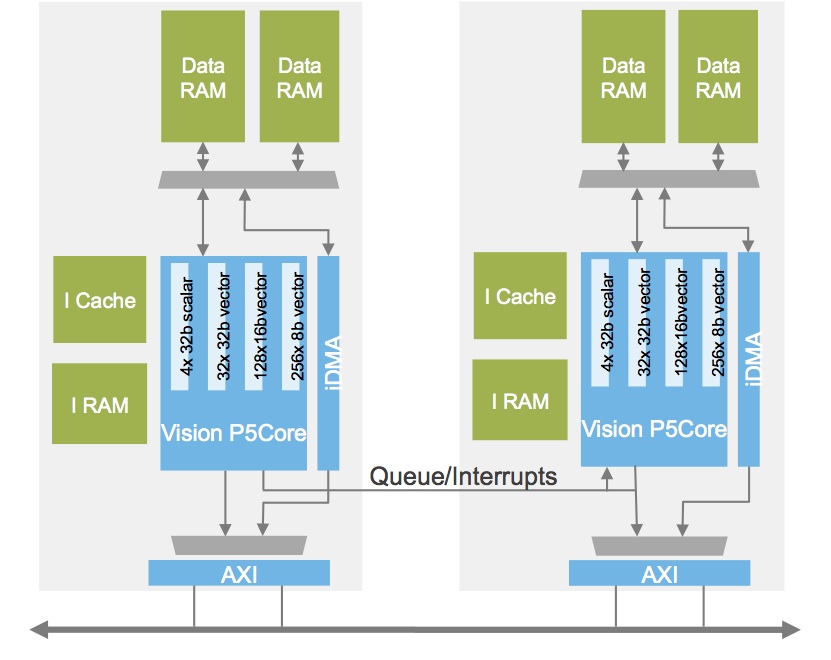
Figure 4. Svelte silicon area requirements at leading-edge process lithographies compel some customers to design multiple Vision P5 cores into their SoCs.
And don't forget about the custom instruction set flexibility that's been inherent to the Xtensa architecture from the beginning. Upwards of 95% of the company's existing computer vision SoC customers harness Tensilica Instruction Extension (TIE) core customization, Crespo reports. Such "soft ISP" core augmentation comprehends various image sensor technologies and filter array arrangements, for example, along with other examples of implementation uniqueness and variability (Figure 5).
Figure 5. Xtensa custom instruction support further bolsters the core's (or cores') potential.
Lead customers have been evaluating and designing in Vision P5 for several months, and the core is now available for general licensing. Between the new entrants entering this application space and the steady generational improvements of existing core and processor suppliers, the embedded vision market remains vibrant. And, as new techniques such as deep learning convolutional neural networks (which Crespo reports remains "mostly experimental" at this point with only a few production customer deployments underway) become more mainstream, processors will inevitably evolve beyond supporting them passably (as Vision P5 reportedly already does) to doing so more fundamentally and optimally.
Add new comment