
Microsoft's Cognitive Toolkit (formerly CNTK) is a relatively recent entrant to the open-source deep learning framework market. And, as the company's Principal Researcher Cha Zhang acknowledged in a recent briefing, it has a ways to go before it can catch up with the population of developers enjoyed by well-known alternatives such as Caffe and Google's TensorFlow. Last year's transition from Microsoft's own CodePlex open source hosting site to the more widely known GitHub repository, along with loosening of license terms, have helped to attract developers, according to Zhang, as have a series of successes in audio and image analysis benchmarks. And the newly released Cognitive Toolkit v2 makes notable improvements in optimizations for embedded deployment, along with other enhancements.
According to Zhang, the Cognitive Toolkit originated in 2011 as a speech analysis research project at the company, although its focus has more recently broadened to include computer vision and other applications. In the fall of 2016, Microsoft announced that the conversational accuracy of the company's deep learning-based speech recognition algorithms, at a 5.9% error rate, had for the first time reached parity with that of professional transcriptionists on the industry standard Switchboard benchmark. Such algorithms also, for example, find use in Skype's real-time language translation feature, which currently supports eight voice languages and more than 50 text languages (the latter for instant message translation).
In 2012, just one year after beginning its audio analysis work, Microsoft Research publicly expanded into visual intelligence by participating for the first time in the yearly ISLVRC (ImageNet Large Scale Visual Recognition Challenge) (Figure 1). Just three years later, Microsoft's ResNet classification, localization and detection algorithms won ILSVRC first-place awards; in 2015, Microsoft also came out on top in the company-sponsored COCO (Common Objects in Context) detection and segmentation competitions. Microsoft's 3.5% error rate result at ISLVRC 2015 was, Zheng suggests, the first time an algorithm had exceeded human accuracy (humans achieve an error rate of 4.9-5.1%, depending on the study).

Figure 1. Three years after first participating in ILSVRC, Microsoft deep learning-based algorithms scored first place in the competition's classification, localization and detection categories, where they were superior to human perception capabilities.
One key reason why Microsoft developed its own deep learning framework, according to Zhang, is that existing alternatives weren't robustly scalable to multiple processors and multiple servers (Figure 2). Reflective of this expandability, researchers at Microsoft, Cray and the Swiss National Supercomputing Center announced in December 2016 that they had scaled Cognitive Toolkit, which they deemed production-ready, to run efficiently on the more than 1,000 NVIDIA Tesla P100 accelerators contained in Cray's XC50 supercomputer. And even with single-processor configurations, Microsoft's researchers saw opportunities for performance improvement at equivalent or better accuracy than that delivered by existing frameworks and the algorithms leveraged by them; the "clean slate" opportunity afforded by being a more recent market entrant is one key advantage of Microsoft's approach with the Cognitive Toolkit, Zhang stressed.
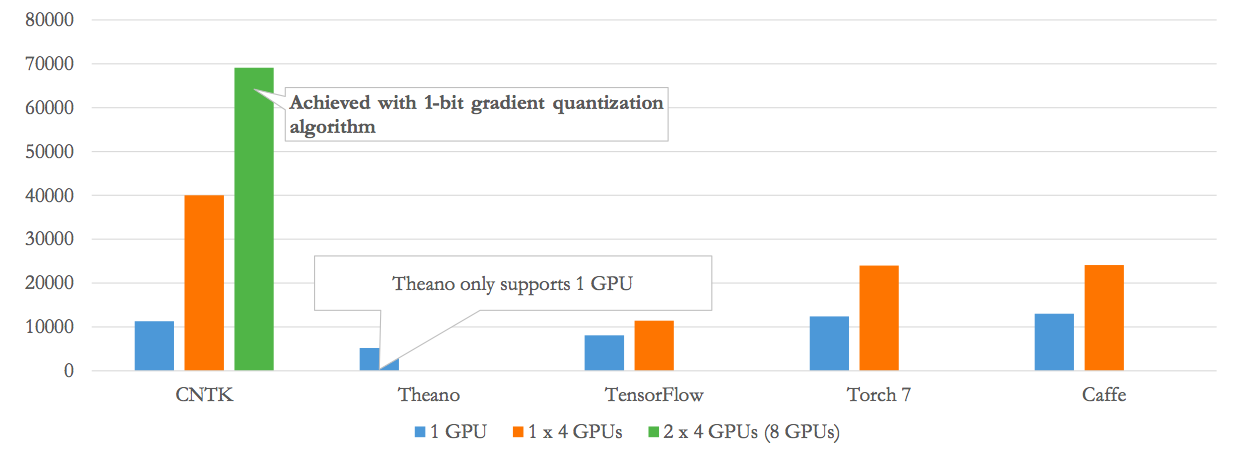
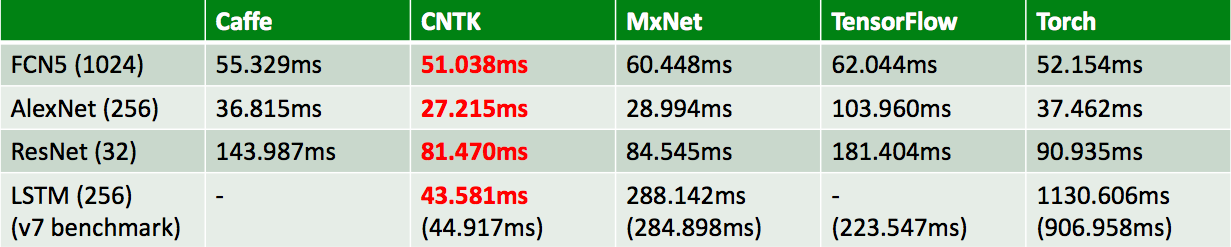
Figure 2. Scalability to multiple servers and multiple GPUs per server was a key requirement that drove Microsoft to develop Cognitive Toolkit versus leveraging an established framework (top, vertical axis is samples/sec), while the company's framework compares well against alternatives even in single-processor configurations (bottom, testing done on a NVIDIA Tesla K80 GPU, full results at http://dlbench.comp.hkbu.edu.hk/).
The Cognitive Toolkit supports Java (in beta), C#/.NET and C++ sources for inference (evaluation) purposes, along with Python and C++ as training input options. Language flexibility is one key advantage Zhang stressed for the Cognitive Toolkit over TensorFlow, along with speed, scalability and other touted strengths, each of which he admitted are to at least some degree deep learning network-dependent and are also "moving targets" as Google evolves both its competitive software toolset and its TPU (TensorFlow Processing Unit) processing platforms. Zhang also stressed that more than 80% of Microsoft's internal deep learning projects leverage the Cognitive Toolkit, and that the internal and external versions of the framework are identical.
In comparing the Cognitive Toolkit against Caffe, Zhang suggested that Caffe is first and foremost a computer vision-focused framework, therefore not easily expandable for audio analysis and other deep learning domains. However, when pressed he acknowledged that the Cognitive Toolkit's origins were in speech analysis, with visual intelligence a more recent addition. And to that point, Zhang also complimented the Caffe team on the extensive suite of both published papers and framework-based models already available to academic and industry researchers alike. The Cognitive Toolkit today is comparatively weak on image analysis, he admitted, but Microsoft has made great efforts to catch up in the last year. Microsoft has a long way to go, he acknowledged, but is making progress.
The latest-generation Cognitive Toolkit v2, which entered public beta earlier this year and was released at the beginning of June, makes three key advancements. First off is preliminary back-end support for the Keras high-level neural network API. This support is still in beta, Zhang stressed; it is not yet fully implemented or performance-optimized. Specific operations not yet supported in the beta Keras release include:
- Gradient as symbolic ops
- Stateful recurrent layer
- Masking on recurrent layer
- Padding with non-specified shape
- Convolution with dilation
- Randomness op across batch axis
- A few backend APIs such as reverse, top_k, ctc, map, foldl, foldr
Qualifiers aside, Zhang claims that Keras compatibility allows a user to easily switch from other toolkits to the Cognitive Toolkit:
Using the Cognitive Toolkit with Keras
Make this simple change in keras.json:
"backend": "tensorflow" => "backend": "cntk"
Now you are using the Cognitive Toolkit.
The next main improvement in the Cognitive Toolkit v2 is support of the Halide programming language for image processing and computational photography applications. CPUs with Halide-optimized instruction sets and compilers run such operations much faster than when they're conventionally coded; for example, Intel's AVX instruction set-supportive quad-core CPUs achieve 7x acceleration on Cognitive Toolkit using Halide, Microsoft claims.
The third notable enhancement in the Cognitive Toolkit v2 is its support for "binarized" convolution and compression (PDF): converting a model previously trained in floating point to an integer equivalent (potentially all the way down to a 1-bit gradient) for use in embedded implementations. Among other things, this conversion involves the replacement of multiplication operations with XOR counterparts, which Zheng suggests are both much faster and more parallelizable. The tradeoff here involves accuracy; Zheng notes, for example, that an AlexNet model currently suffers an approximately 10% accuracy loss when "binarized", although the accuracy impact is model-dependent and can be offset to some degree in other ways.
As previously mentioned, Java support in Cognitive Toolkit is also in beta at present. Microsoft is also working on an ARM version of the Cognitive Toolkit, specifically targeting the Raspberry Pi platform.
Add new comment