
As Jeff Bier has mentioned in several of his recent columns, deep learning algorithms have gained prominence in computer vision and other fields where there's a need to extract insights from ambiguous data. Convolutional neural networks (CNNs) – massively parallel algorithms made up of layers of computation nodes – have shown particularly impressive results on challenging problems that thwart traditional feature-based techniques; when attempting to identify non-uniform objects, for example, or in sub-optimal viewing conditions. However, as with many emerging technologies, much of the R&D work on CNNs is being undertaken on resource-rich PC platforms. CEVA's just-introduced Deep Neural Network (CDNN) software framework aspires to optimize CNN code and data for more modestly equipped embedded systems, specifically those based on the company's latest XM4 vision processor core.
CDNN consists of two primary sets of software. First is the CEVA Network Generator, a utility that transforms existing pre-trained networks and weight data sets, generated by deep learning frameworks such as the popular Caffe, into embedded-ready equivalents (Figure 1). Floating-point to fixed-point data conversion is a key aspect of this embedded adaptation, a fact that won't likely be a surprise to anyone who's undertaken embedded optimizations of floating point-based digital signal processing code. Yair Siegel, CEVA's Director of Marketing for Imaging and Vision, reminded BDTI during a recent briefing that the XM4 vision processor core optionally supports single- and double-precision floating-point arithmetic. However, he suggested, incorporating such support in the core would have die size, performance and power consumption implications.
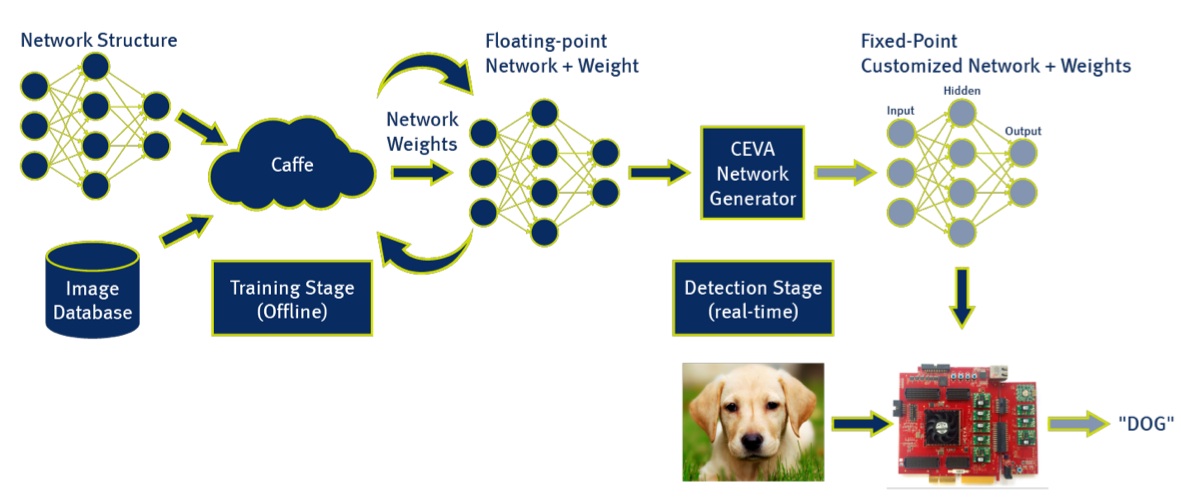
Figure 1. Floating-point to fixed-point conversion of neural networks is one key capability of CEVA's Network Generator utility for embedded system optimization.
Alternatively, CEVA offers Network Generator-automated fixed-point conversion, whose resultant optimized network and weight files deliver near-identical object classification results, according to the company (Figure 2). As a case study example, CEVA ran the entire 1,000-image-category AlexNet network model on a NVIDIA Jetson TK1 development board and a CEVA XM4 evaluation board. The latter employed a CEVA Network Generator-transformed version of AlexNet, retaining the original network's 24-layer and 224x224 input size characteristics. CEVA claims that its implementation is more than 3x faster than the NVIDIA Tegra K1-based approach, delivering 10 ms per-image inference versus 35 ms on the NVIDIA GPU-accelerated alternative.
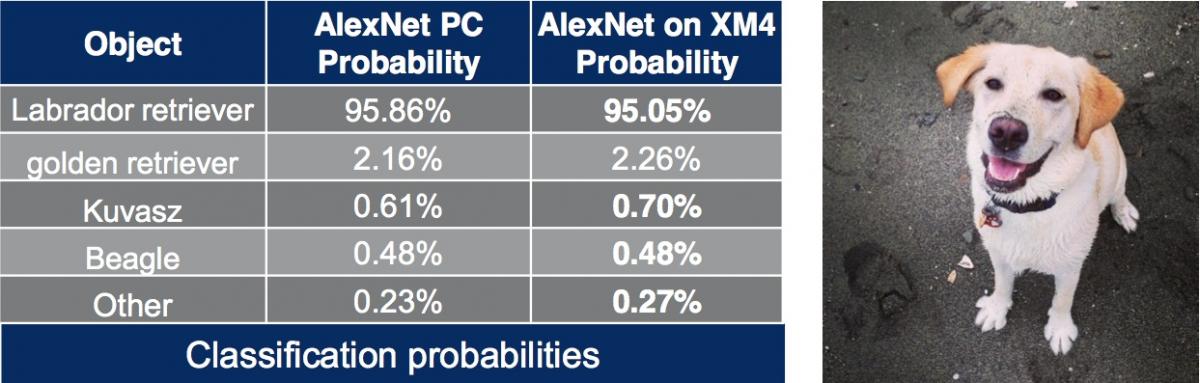
Figure 2. CEVA's AlexNet study suggests that the networks created by its Network Generator Utility deliver near-identical object classification results to the original networks from which they are derived.
Further, CEVA promotes its XM4 vision processor as requiring 15x lower memory bandwidth than that needed by GPUs, due to the combination of its scatter-gather random memory access-optimized controller and its aggressive use of on-core data caching for vision application-optimized reuse purposes. CEVA also claims that the XM4 is significantly more energy efficient than GPUs when running CNNs. However, this claim is based on comparing the CEVA XM4 processor core versus a full GPU-based SoC and other components on a development board – meaning that it is not an apples-to-apples comparison.
More generally, any comparison of pre- and post-conversion results is inherently an apples-to-oranges analysis, since the purpose of the Network Generator is to modify the network and weights. Note, too, that GPUs are more general-purpose in nature than is a specialty vision processor; any disadvantage that the GPU may have from a power consumption standpoint is counterbalanced by its enhanced flexibility to also support conventional 2D and 3D graphics, along with other GPGPU tasks.
The other key piece of CEVA's Deep Neural Network software suite is its set of real-time neural network libraries, which enable fast execution of neural networks on the XM4. These libraries can be used either in part or in their entirety by developers, since a corresponding API accompanies each library layer (Figure 3). The library elements support multiple neural network frameworks, including not only the previously mentioned Caffe but also Torch and Theano. CEVA's Siegel indicates that the company intends to maintain the library to support additional networks as the deep learning market matures and evolves. Accompanying application software layers come from companies such as Phi Algorithm Solutions, CEVA's first CDNN solutions partner, with its Universal Object Detector.
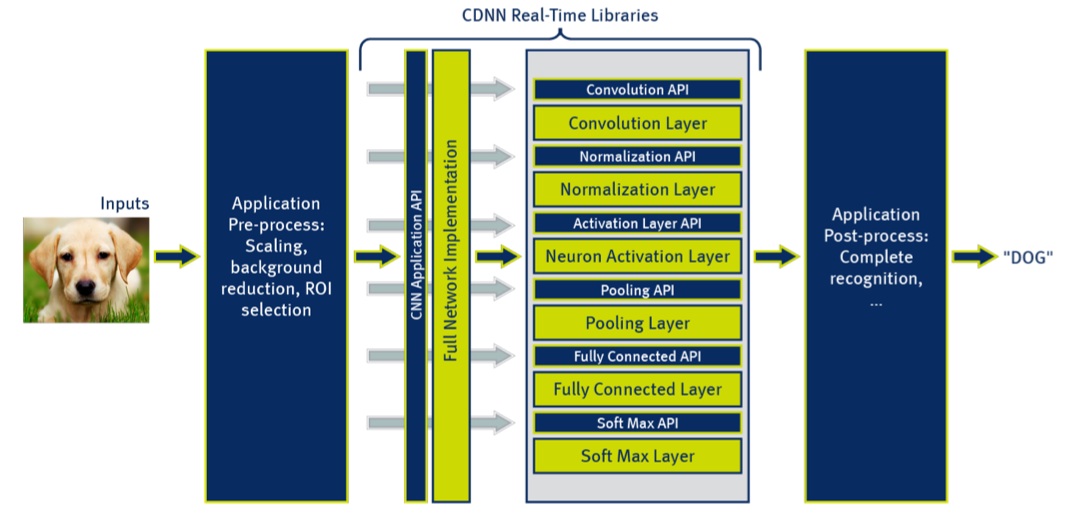
Figure 3. APIs enable selective use of any or all of the software layers in CEVA's neural network library suite, while partnerships with companies like Phi Algorithm Solutions deliver complete applications.
When asked about alternative approaches that utilize hardware architectures specialized for neural network execution, Siegel suggested that at this early stage in deep learning's evolution, a highly hard-wired processing approach would be a mistake, given the technology's immaturity and the resulting need for flexibility. Siegel feels that the approach taken by his company, combining a general-purpose processing core with "hooks" for integration of optional hardware accelerators and other heterogeneous computing resources, along with corresponding software optimization tools, is optimal at this stage in the market's evolution. And on that note, while he acknowledges that few high-volume deep learning implementations exist today, he believes that neural network support is a key decision factor for next-generation SoC designs currently in definition and due to enter production in the next year or so.
CEVA's Deep Neural Network software framework is currently available; contact the company for additional details. Specifics of the Phi Algorithm Solutions partnership and associated Universal Object Detector pricing and availability are still to be determined. For more information about CEVA's silicon and software solutions, consider attending the company's free webinar "Deep Learning – Bringing the Benefits into Low-Power Embedded Systems," taking place Thursday, November 12, 2015 from 10:00-11:00 AM Pacific Time.
Add new comment