
"General-purpose GPU" (or "GPGPU") refers to the use of graphics processors for a variety of non-graphics tasks, and is a frequently discussed topic here at InsideDSP. GPUs are massively parallel processors, originally designed to only handle vertex and pixel operations. However, with the emergence of programmable shader-based architectures beginning with NVIDIA's mainstream GeForce 3 line in 2001 and joined by ATI Technologies' (now AMD's) Radeon 9700 and derivatives unveiled the following year, increased function flexibility significantly increased interest in GPGPU's potential. Support for floating-point arithmetic, program looping and other CPU-like capabilities have made robust programming of GPUs feasible, and over time GPU architectures have grown increasingly robust in their processing, local memory, interconnect and other resource capabilities.
Silicon potential means little, of course, without software development tool support to unlock that potential. Initially, GPGPU enthusiasts leveraged conventional graphics APIs such as DirectX (and associated DirectX Compute) and OpenGL to program GPUs for non-graphics tasks. This was an essential (in the absence of alternatives) but limiting approach to solving the problem; data structures, memory management schemes and other API-exposed techniques intended for graphics operations weren't necessarily optimal (or, for that matter, relevant at all) for general-purpose processing. More recently, GPGPU-tailored APIs, libraries and other toolset elements have emerged, both industry-standard (OpenCL and HSA, for example) and vendor-specific (NVIDIA's CUDA, along with ATI's now-deprecated Stream).
NVIDIA's proprietary tools remain in common use, a reflection of the company's comparatively early and robust pursuit of GPGPU application opportunities. NVIDIA's latest toolset announcements at (and shortly after) the recent International Machine Learning Conference reflect this continued popularity, highlighting NVIDIA”s efforts to both simplify and performance-optimize the use of GPUs for non-graphics tasks and to cultivate a preference for NVIDIA GPUs in particular. They also reflect the increasing popularity of deep learning, aka neural networks, an emerging technique to distinguish objects of interest in speech, computer vision and other data analysis applications.
NVIDIA unveiled the initial version of its DIGITS Deep Learning GPU Training System in March, at the company's GPU Technology Conference. According to Ian Buck, the company's intent with DIGITS is to broaden access to GPU-accelerated deep learning techniques for data scientists and researchers who don't necessarily need (or even want) to know about the technology fundamentals. Most deep learning software today, according to Buck, remains script-implemented and otherwise crude to learn and use, reflective of its academia-developed and -tailored nature. DIGITS, in contrast, is web- and GUI-based, intended to assist this broader audience in quickly designing the best deep neural network (DNN) for their data, along with visually monitoring DNN training quality in real time (Figure 1).
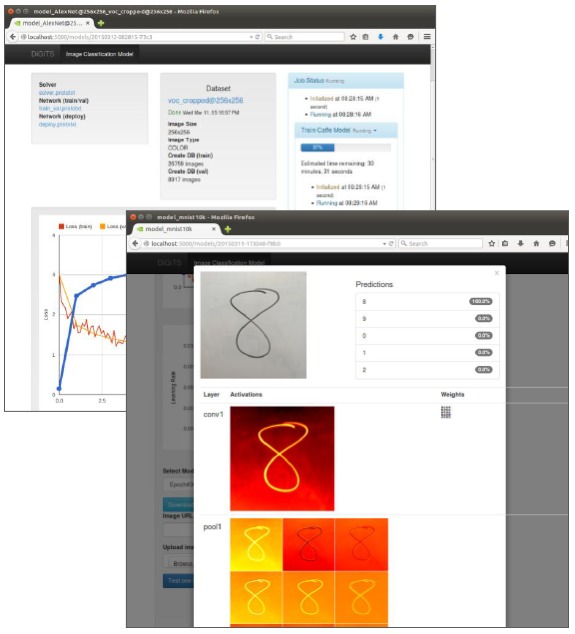
Figure 1. NVIDIA's DIGITS neural network design software strives to one-up the interface and other attributes of script-based alternatives.
The primary enhancement of the just-introduced DIGITS 2 is its support for automatic multi-GPU (up to four) scaling of training algorithms. In his briefing with BDTI, Ian shared internally measured results comparing the DIGITS 2 training performance versus DIGITS 1 on an Ubuntu Linux-based NVIDIA DevBox system running an unspecified deep learning code algorithm. DevBox is based on an Intel Core i7-5930K 3.5 GHz processor and contains up to four TITAN X GPU boards, each capable of 7 TFlops of peak single-precision arithmetic processing, delivering 336.5 GB/s of memory bandwidth, and containing 12 GB of memory, according to NVIDIA. While there isn't a 1:1 correlation between number of GPUs and the resultant training acceleration factor, a greater-than-2x boost with a four-GPU system is still notable (Figure 2).
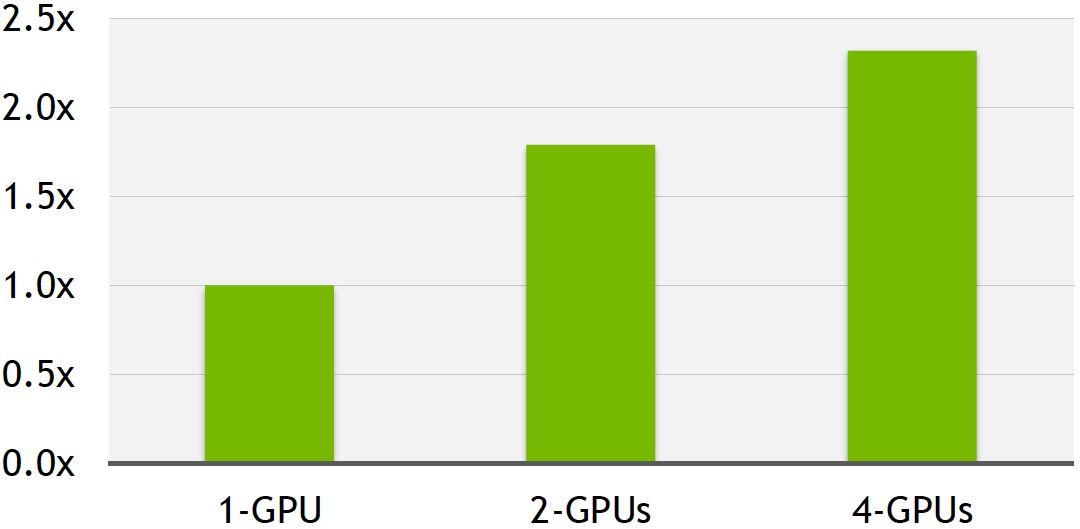
Figure 2. Latest DIGITS 2 supports multi-GPU scaling; it also automatically prioritizes workload assignments to the fastest available GPU(s) in a system.
Also updated is NVIDIA's cuDNN (CUDA Deep Neural Network) algorithm library, which was launched last November and upgraded to version 2 in March. Now at version 3, cuDNN represents NVIDIA's attempt to codify the basic mathematical and data operations at the core of deep learning training. Newly added in this version are various FFT-based convolution routines, as well as GPU architecture-optimized 2D convolutions. And perhaps even more notable, NVIDIA has expanded the data format support in cuDNN 3, as well as in the related CUDA 7.5.
To date, cuDNN has handled each deep learning "neuron" data set solely in 32-bit floating-point format ("FP32"). FP32 delivers high accuracy but consumes a significant amount of the GPU's associated memory (i.e. frame buffer, in graphics terminology). And increasingly, large neural networks' storage requirements are exceeding the amount of memory available on a graphics board. The newly added FP16 option decreases per-iteration training precision but doubles the possible neural network size for a given amount of memory. In many cases, according to Buck, 16-bit floating point delivers higher aggregate performance, by statistically trading off accuracy versus model complexity.
As examples of the potential training speed boost delivered by the FP16 option and other cuDNN 3 enhancements, Buck shared internally measured training results across three common deep learning benchmarks related to image classification (Figure 3). As with the earlier DIGITS 2 example, the reference system was Ubuntu Linux-based. This time, however, it included a single GeForce TITAN X GPU, along with an Intel Core i7-4930K CPU running at 3.40 GHz. More generally, NVIDIA has also published on its website examples of FFT convolution acceleration results derived from the more optimized library code in cuDNN 3.
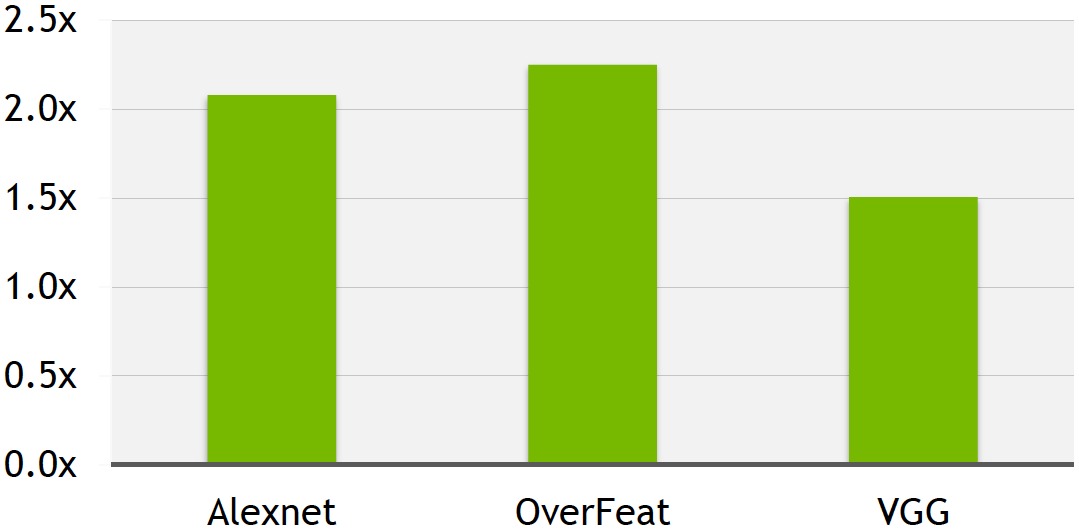
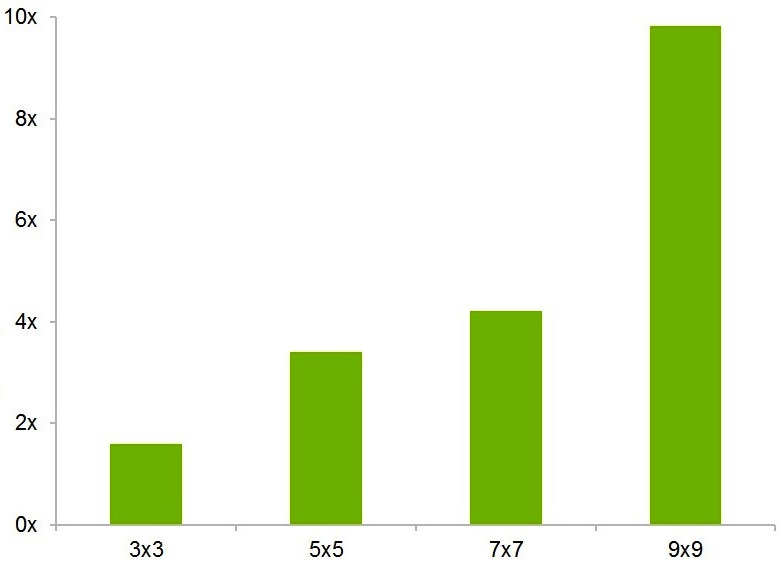
Figure 3. Reference deep learning training benchmarks for image classification can be significantly accelerated, suggests NVIDIA-supplied data, when cuDNN 3's new FP16 data format is employed versus with the legacy FP32 approach (top). The library also now includes optimized routines that speed up FFT convolutions beyond what was possible in prior cuDNN versions (bottom).
NVIDIA's most recent announcement concerns OpenACC, a means of parallelizing source code for acceleration on GPUs via compiler-directive annotations. Unlike approaches such as that one advocated by Texas Multicore Technologies with SequenceL, OpenACC leverages industry-standard C and Fortran instead of requiring that you learn a new proprietary language. However, it's "open" only in that NVIDIA has developed it in partnership with high-performance computing (HPC, i.e. supercomputer) compiler companies CAPS and The Portland Group (PGI), along with systems supplier Cray. AMD, for example, is notably absent from the OpenACC advocate list. And to that point, OpenACC is conceptually a competitor to both Khronos' OpenCL and to OpenMP, both of which have a larger consortiums supporting them . With that said, some effort has been made to merge the OpenMP specification with OpenACC.
In his presentation, Buck shared comparative benchmark results for an AMD Opteron 6274 16-core CPU and a NIVIDIA Tesla K20X CPU, both installed in a Cray Titan supercomputer at Oak Ridge National Laboratory. The common algorithm was LSDalton, a large-scale program for calculating high-accuracy molecular energies. As implemented by the qLEAP Center for Theoretical Chemistry at Aarhus University, less than 100 lines of code originally intended to run on the CPU required modification for potential GPU acceleration, translating into less than 1 man-week worth of work, and the resultant software could run unchanged on either the CPU or GPU. However, the GPU speedups when modeling three different variants of the alanine amino acid were significant (Figure 4).
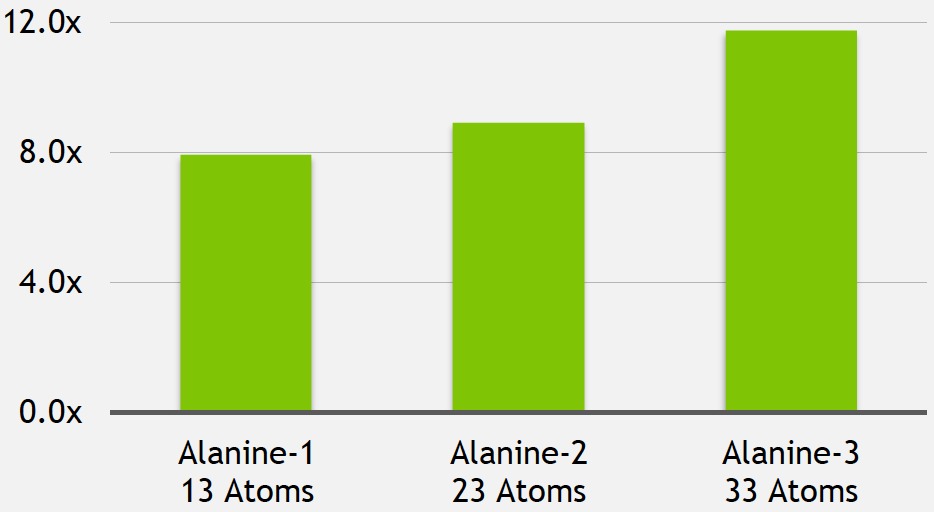
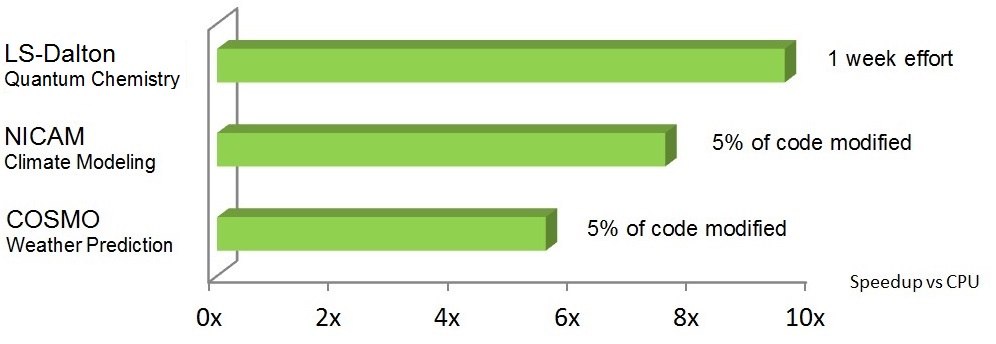
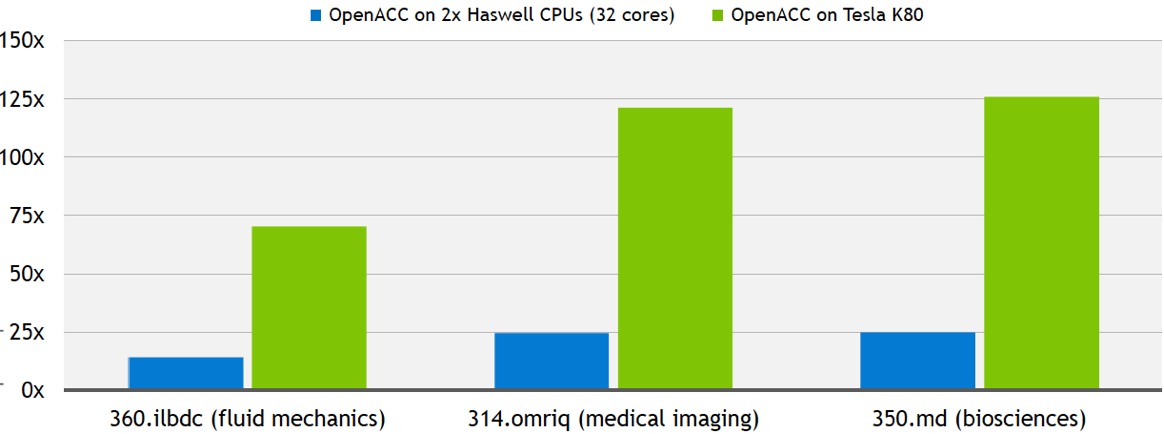
Figure 4. The molecular analysis of various alanine amino acid structures was greatly sped up, after little incremental coding effort was invested, when the OpenACC-annotated LSDalton algorithms ran on the GPU in Oak Ridge National Laboratory's supercomputer versus on its CPU (top). Similar acceleration factors, according to NVIDIA, have also been seen with climate modeling and weather prediction applications (middle). But comparative CPU-vs-GPU SPEC benchmark results currently need to be qualified by their single-CPU-core execution limitation, which is in the process of being resolved by the compiler vendor (bottom).
The OpenACC area of Nvidia's website documents two other conceptually similar case studies, one based on the NICAM climate modeling algorithm (PDF) and the other on COSMO weather prediction code (PDF). Both claim similarly dramatic GPU-accelerated results after minimal incremental code development effort. And Buck also shared three comparative SPEC benchmark results with BDTI. Note, however, that these latter cases document the speedup measured on a Tesla K80 GPU versus on only one of the 32 total CPU cores available in the dual Intel Xeon E5-2698 v3 ("Haswell") processors also present in the Supermicro SYS-2028GR-TRT rack server.
NVIDIA's partner PGI is in the process of adding compiler support not only for GPU acceleration but also for multi-core x86 CPUs, thereby addressing this comparative SPEC benchmark results shortcoming. In NVIDIA's own words, "When you don’t have a system with GPUs, the compiler will parallelize the code on x86 CPU cores for performance boost. When a GPU is present, the compiler will parallelize the code for the GPU. This x86 CPU portability feature is in beta today with key customers. And we’re planning to make it widely available in the fourth quarter of this year."
OpenACC is nearing the four-year anniversary of its public unveiling. What's new this month is that NVIDIA has developed the OpenACC Toolkit, a free (for academia; commercial users can sign up for a free 90-day trial) suite of OpenACC parallel programming tools. Specifically, the OpenACC Toolkit includes:
- PGI's Accelerator Fortran/C Workstation Compiler Suite for Linux
- The NVProf Profiler, which gives guidance on where to add OpenACC directives
- "Real-world" code samples, and
- Documentation
The OpenACC Toolkit, currently without the earlier-mentioned multi-core CPU compiler enhancements, is now available for download. Also available as a free download for NVIDIA registered developers is the preview version of DIGITS 2, along with a release candidate of CUDA 7.5. And as for the cuDNN 3 library, NVIDIA states that it "is expected to be available in major deep learning frameworks in the coming months."
NVIDIA is to be commended for its visionary and vigorous embrace of HPC and other GPGPU applications, and for its ongoing support of them with both focused silicon and software products. While industry-standard toolsets may be preferable because they promise to provide vendor selection flexibility, engineers and researchers also need to develop their GPGPU-accelerated products in a rapid and robust manner. Until industry-standard offerings offer comparable (if not superior) capabilities as their proprietary peers, therefore, vendor-specific software such as NVIDIA's will continue to play an important role.
Add new comment