
After some five years of architecture definition work and several years of development, Freescale's new StarCore SC3900 DSP core will see its first silicon implementation next quarter in the QorIQ Qonverge B4860 processor for macrocell base station designs, unveiled last month at the Mobile World Congress conference. As mentioned last August in InsideDSP (see "Next-Generation Power Architecture-Based SoCs Embrace Advanced Lithography, Core Virtualization, SIMD Instruction Set"), Freescale launched its first-generation QorIQ Qonverge devices in February 2011, derived by combining StarCore SC3850 DSP cores and Power e500mc 32-bit CPU cores on a single sliver of silicon.
The B4860, in comparison, beefs up both the on-chip DSP (to the aforementioned SC3900, with six DSP cores) and CPU resources (to four instances of the 64-bit and AltiVec-enhanced e6500, the same core found in the QorIQ AMP family) (Figure 1). The increased transistor budget afforded by an unnamed foundry partner's process migration from 45 nm to 28 nm is at the foundation of this QorIQ Qonverge family evolution. However, although you might expect the lithography shrink to also lead to clock speed increases, they have remained at SC3850-compatible 1.2 GHz for the fastest B4860 member. As such, notable benchmarked performance gains for the SC3900 are entirely the result of DSP core re-architecting.
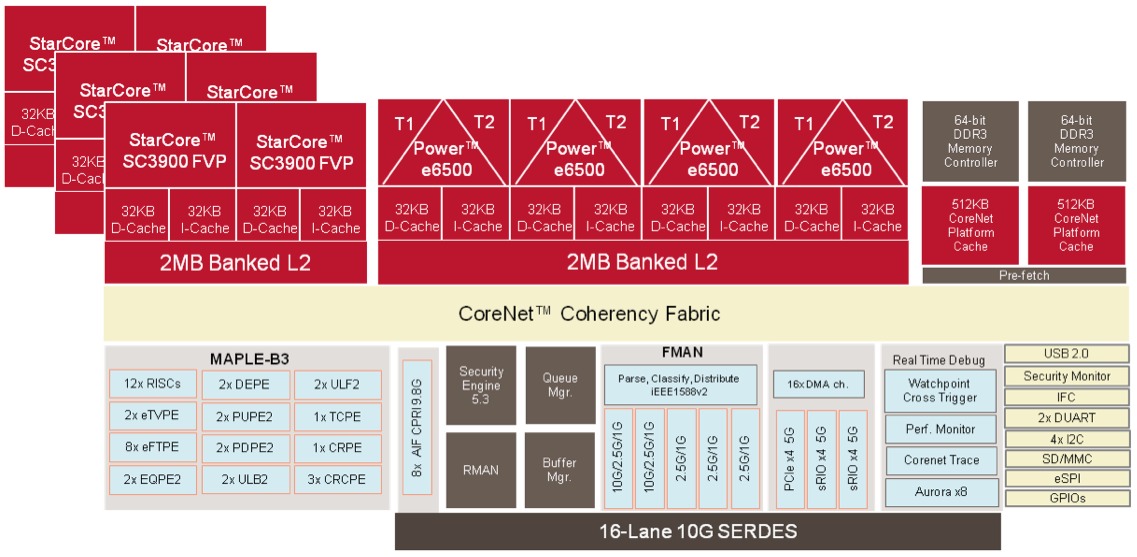
Figure 1. Freescale's QorIQ Qonverge B4860 SoC marks the first silicon implementation of the company's latest SC3900 DSP core.
Since the e6500 has been previously discussed in detail in InsideDSP, this writeup will only hit the highlights. Each CPU core is frequently capable of executing two concurrent threads, although since some core resources are shared between the threads (as with Intel's HyperThreading architecture), the e6500 is capable of only 1.7x (on average) the performance of a single thread. The four e6500 cores share a 2 MByte 16-way, four-bank L2 cache. After being omitted from several generations of Power architecture, the 128-bit AltiVec SIMD engine returns to the e6500. And the multi-core function block communicates with the remainder of the SoC via the CoreNet coherent interconnect fabric.
Now to the SC3900, the primary focus of this article. Note that, as with the e6500, each DSP core contains 32 KByte L1 instruction and 32 KByte L1 data caches. And, as with the e6500, the L2 cache is 2 MByte in size, 16-way set associative, and four-bank in arrangement. However, each L2 cache allocation is, in this case, only shared between two DSP cores, translating to 6 MBytes of total L2 cache in the B4860 DSP core subsystem. Dedicated hardware ensures memory coherency between the L1 caches, L2 caches and main memory.
After developing the prior-generation QorIQ Qonverge devices, Freescale ascertained that the SC3850 DSP had reached the end of its successful 10-year lifetime. Improvements in the SC3900 successor would require not only a higher transistor budget, but also sacrificing backwards-compatibility at the binary level. Ten years ago, such a decision would have been fairly problematic, according to Freescale, because the bulk of its customers were using assembly language.
Although re-assembling source code for a new DSP architecture is feasible, it can be problematic. And existing binaries in a function library, for example, of course won't run on the new architecture. However, today Freescale finds that more than 95% of customers’ software relies on high-level C code, sometimes also with intrinsics. Freescale claims that although the SC3900 compiler is still early in its evolution, the code it generates suffers only a 10-20% performance degradation on optimized C code with intrinsics when compared against the hand-coded, optimized assembly code.
Freescale architected the SC3900 to efficiently handle baseband Layer 1 processing, which subdivides into three primary categories (with relative importance dependent on the application):
- Computation-intensive (mainly MAC-intensive) DSP code
- Data manipulation DSP code, and
- Control code
For computation-intensive code, the SC3900 enhances the vector processing capabilities of the SC3850 by improving the execution blocks and the data path connecting them to the remainder of the core (and bigger-picture SoC). 32 peak MACs per cycle is 4x the capability of the SC3850, and combines with 64 dedicated 40-bit registers (4x the register count of the SC3850). And 1,024 bits of peak per-cycle bandwidth between the core and L1 cache, 8x that of the SC3850, translates into high MAC utilization. The combination of these enhancements, Freescale claims, leads to SC3900 performance 3.5 to 4x higher than the SC3850 in computation-intensive DSP code.
In baseband Layer 1 operations, according to Freescale, the term "data manipulation" encompasses multiple functions. For example, it can involve data preparation before and after computation-intensive kernels. It also includes less regular kernels, and serial or cyclic kernels with low parallelism. The SC3900 addresses these functions' needs via several enhancements, which the company estimates leads to performance 2-3x higher than the SC3850 for data manipulation tasks (Figure 2):
- Four independent execution units, each capable of eight-way SIMD and able to run different, independent instructions from the others
- Scalar (versus vector) registers which any execution unit can read or write
- A large, efficient instruction set which supports a diversity of data types and sizes, and
- New data manipulation-specific instructions

Figure 2. Unlike a traditional vector processing approach, in which each execution unit can only access a subset of registers, the SC3900's scalar implementation delivers full register read/write flexibility.
Finally, the SC3900 focuses on improving control code efficiency, since Layer 1 control-intensive scheduling functions tend to be tightly integrated with arithmetic-intensive software. Control code performance is primarily affected by two factors, according to Freescale's analysis of application software: core-plus-compiler efficiency, and memory system efficiency. The company has addressed these issues via a diversity of improvements, such as:
- The ability to flatten decision trees using multiple predicates
- A third address generation unit with multiply and shift support for address calculation
- Full support for non-aligned memory accesses without penalty, and
- A larger, clustered L2 cache to keep the code close to the core
As a result, Freescale believes, the SC3900 is up to 1.5x faster than the SC3850 in control processing operations. Freescale has also focused significant attention on power consumption beyond the inherent improvements delivered by the 45-to-28 nm lithography shrink, via techniques such as micro-architecture optimizations and fine-grained clock- and power-gating techniques. As a result, the company believes that it has reduced static power by up to 80% and dynamic power by up to 70%.
How do the SC3850 and SC3900 stack up against each other when run through BDTI's BDTImark2000 suite? BDTI published its fixed-point benchmarking results last month (PDF), which indicated that at an equivalent 1.2 GHz operating frequency, the SC3900's score of 37,460 is 2x that of the SC3850, at 18,500. Unknown at this point is the degree (if any) to which the advanced 28 nm process will enable Freescale to boost the SC3900 clock speed beyond its current 1.2 GHz foundation level in the future.
On that same chart, you can also compare the SC3900 against alternative DSP architectures from Texas Instruments (such as the TMS320C66x) and other competitors. Keep in mind as you correlate the SC3900 against other cores that they may run at differing frequencies; normalization to a common clock speed will enable you to isolate architecture-versus-architecture disparities. Note, too, that the SC3900 results are of the BDTIsimMark2000 variety, since the B4860 SoC won't begin sampling until next quarter.
Regarding Freescale's estimate of a 3.5 to 4x SC3900 performance improvement over the SC3850 in computation-intensive DSP code, BDTI's engineers referenced the SC3900's 2x-higher overall BDTImark2000 score, while also noting that some of the benchmark suite's kernels reported a larger 3 to 4x improvement. Regarding control processing improvements, Freescale's 1.5x performance boost estimate for the SC3900 is consistent with BDTI’s findings. However, BDTI's engineers also pointed out the SC3900's comparatively higher memory consumption as measured by the BDTImemMark2000 benchmark (PDF); the SC3900 achieved a score of 52, with the SC3850 at 68 and TI-C66x (fixed-point) at 62 (a higher score translates to lower memory usage when running the various benchmark kernels).
Note the "fixed-point" qualifier: as with the SC3850 and unlike (for example) the TI-C66x, Freescale's SC3900 omits general-purpose floating-point support. When asked about the lack of floating-point support, Freescale engineers responded that in the B4860's target markets, floating-point capabilities are predominantly required when implementing MIMO functions, and the B4860 includes a dedicated MIMO equalization accelerator core that includes floating-point support. However, Freescale indicated that it may yet implement general-purpose floating-point support in the future, either in a derivative of the SC3900 or in a successor core.
To that point, the company anticipates that the SC3900 will have at least a 5-6 year design-in life. Although the B4860 marks the first implementation of Freescale's new core, past-history trends with the SC3850 suggest that the SC3900 will expand throughout the company's DSP-inclusive SoC product line, including into QorIQ Qonverge follow-ons with varying core counts. Evolving the cellular network beyond a few large base stations each servicing a large area to a hierarchical approach dominated by more numerous, albeit smaller-footprint cells is a forecasted trend that numerous companies are investing heavily in. With the new SC3900 DSP core, Freescale is clearly placing its bets that this particular prediction will pan out.
Add new comment