
Hot on the heels of announced production availability for the Neural Compute Stick based on the Myriad 2 vision processor comes a next-generation SoC from Movidius (an Intel company), the Myriad X. With a 33% increase in the number of 128-bit VLIW processing cores, along with additional dedicated imaging and vision acceleration blocks and a brand new "neural compute engine," the new chip delivers a claimed 10x increase in floating-point performance versus its predecessor (Figure 1 and Table 1). However, Movidius' emphasis on floating-point processing is curious in a deep learning world that seemingly is increasingly focused on fixed-point data, and ever-lower-precision data at that.

Figure 1. Although the Myriad X package size is comparable to that of its Myriad 2 predecessor, a more advanced fabrication process enabled the integration of more and better capabilities.
| Myriad 2 | Myriad X | |
| Process Lithography | 28 nm (TSMC) | 16 nm (TSMC) |
| Operating Frequency | 600 MHz | 700 MHz (estimated) |
| CPU Cores | 2 LEON4 (SPARC v8 RISC) | 2 LEON4 (SPARC v8 RISC) |
| 128-bit VLIW Processor Cores | 12 SHAVE | 16 SHAVE |
| Camera Inputs | Up to 6 (12 MIPI DPHY v1.1 lanes) | Up to 8 (16 MIPI PHY v1.2 lanes) |
| Vision Processing Acceleration | Harris, median filter, edge filter, 2X scaler, etc. | All Myriad 2 functions, plus (de)warp at greater than 2 Gpixels/sec, stereo depth at up to 720p/180 fps, dense optical flow/motion estimation at up to 4K/30 fps, etc. |
| Video Encode Support | H.264 at up to 1080p/30 fps (in software) | All Myriad 2 functions, plus (de)warp at greater than 2 Gpixels/sec, stereo depth at up to 720p/180 fps, dense optical flow/motion estimation at up to 4K/30 fps, etc. |
| Neural Network Processing Capabilities | Up to 100 GFLOPS (via VLIW cores, etc.) | Up to 1 TFLOPS (via neural compute engine, etc.) |
| Overall Peak Compute Capability | >1 TOPS | >4 TOPS |
| On-die Memory | 2 MBytes (400 GBytes/sec bandwidth) | 2.5 MBytes (450 GBytes/sec bandwidth) |
| Chip Stack MCM-based SDRAM Options | None, 1 Gbit LPDDR2 (533 MHz, 32-bit), 4 Gbit LPDDR3 (933 MHz, 32-bit) Architecture supports up to 8 Gbit |
None, 4 Gbit LPDDR4 (1600 MHz, 32-bit) Architecture supports up to 16 Gbit |
| Encryption Support | AES Boot (optional, in software) | AES-256 Boot and Data (in hardware) |
| Package Options | 5mm x 5mm, 6.5mm x 6.5 mm, 8mm x 9.5 mm | 8.1mm x 8.8mm |
| Other System Interfaces | USB3, SPI, I2S, SD Card, GbE | USB 3.1, Quad SPI, I2S, 2x SD Card, 10 GbE, PCI-E Gen3 |
Table 1. Myriad 2 and Myriad X specifications.
As Gary Brown, Director of Marketing, explained in a recent briefing, Myriad X is the latest step in an architecture evolution that began with the LEON-and SHAVE-based ISAAC and SABRE test chips a decade ago (Figure 2). The first-generation Myriad 1 had no integrated ISP (image signal processor), an omission that was rectified beginning with the initial iteration of the Myriad 2, which also added vision processing acceleration support, two years later. Myriad 2 family follow-ons offered optional DRAM in a "stacked" MCM (multi-chip module) package configuration, along with optional encryption support for boot firmware access. They also made minor enhancements to the SHAVE VLIW processor architecture and instruction set, as well as expanding the scenarios in which the ISP core could complete a full pipeline without needing to access external memory.

Figure 2. The Myriad X is the latest step in a product line evolution that began with the ISAAC and SABRE ISP- and VPU-less test chips along with the first-generation production SoC, Myriad 1.
Brown noted that when the Myriad 2 was being architecturally defined, deep learning-based vision processing was in its infancy. The product focus was therefore primarily on classical vision algorithms, although the SHAVE cores and other on-chip processing resources are also capable of handling many deep learning inference tasks, as exemplified by ongoing design wins at DJI (multiple drone families), Google (Clips lifelogging camera), etc. By the time the Myriad X entered development, however, deep learning had entered the mainstream, and not only from an R&D standpoint but in numerous (and growing) production deployments. Hence, in addition to increasing the number of SHAVE cores from 12 to 16, Movidius took advantage of the increased transistor budget of the new chip's 16 nm fabrication process to add a dedicated neural network inference acceleration core (Figure 3).
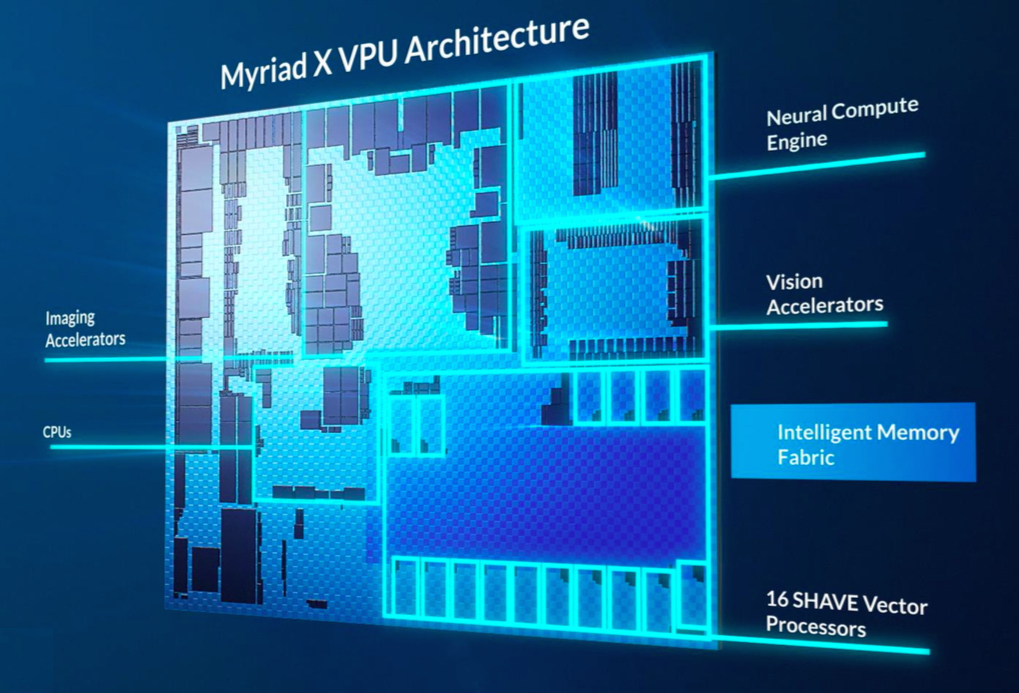
Figure 3. A new dedicated neural network accelerator core, along with expanded support for classical vision algorithm acceleration and additional camera inputs, are among the notable Myriad X enhancements.
The resultant claimed improvement is impressive: a 10x increase in floating-point performance on deep neural networks, a 4x increase in overall compute capacity, and 6x faster stereo depth processing capabilities along with 3x higher resolution stereo support. Brown was quick to acknowledge that real-world improvements will vary across various applications. He was equally quick to point out, however, that the performance enhancements any particular customer will see will come at little to no increase in energy consumption. Reflective of Movidius' focus on "inference at the edge," Myriad X features only a modest clock speed increase over Myriad 2, and the newer chip's more power-frugal lithography foundation will further improve its energy efficiency.
Brown also noted that while the new chip's published performance claims are floating point-focused, the "neural compute engine" supports not only 16-bit floating-point but also both 8- and 16-bit fixed-point data types. However, to date Movidius has not disclosed the neural network accelerator's performance when operating in these fixed-point modes. While deep learning was clearly emphasized in the new chip's definition, classical vision algorithms weren’t ignored; as Table 1 shows, a number of common functions are now hardware accelerated, as is video encode for MJPEG (as well as JPEG still image encoding), H.264 and H.265. And Myriad X also supports up to eight camera inputs, two more than Myriad 2, translating into 700 million pixels/sec of peak aggregate image data in-flow.
Movidius will offer Caffe deep learning framework support for Myriad X out of the chute, with TensorFlow support following in short order. Brown was not willing to commit to a specific TensorFlow support date for Myriad X, although as a potential point of comparison, the Neural Compute Stick entered volume production in mid-July in Caffe-only form, adding TensorFlow support one quarter later. Myriad X support for other frameworks is currently under evaluation. Initial customers are already receiving Myriad X samples; once in production, the various new memory-less and SDRAM-inclusive chip flavors will coexist with their Myriad 2 predecessors.
Add new comment