
At January's CES (Consumer Electronics Show), Cadence showed that has picked up the baton and continued the pace of acquired company Tensilica by announcing the eleventh generation of the Xtensa configurable processor architecture. First unveiled in 1999, Xtensa has received evolutionary advancements on a roughly two year cycle since that time; in late 2013, for example, InsideDSP covered the Xtensa 10 product release. At the time, Cadence had also unveiled the fifth generation of its LX processor core, which first appeared in 2004 and builds on a base Xtensa foundation with VLIW and other advanced capabilities. Similarly, Cadence used the 2015 CES to also announce the latest-generation LX6, a functional superset of Xtensa 11. And application-specific variants of LX6, announced at CES too, further expand the Cadence product line
Xtensa 10 and LX5 had been released only a few months after Cadence announced its intention to acquire Tensilica; not surprisingly, therefore, the bulk of their development had occurred prior to the acquisition. Chris Jones, former product marketing director at Tensilica and now product marketing director of the broader IP Group at Cadence, notes that Xtensa 11 and LX6 are the first core generations developed fully under the Cadence "banner." And although Jones acknowledges that the advancements this time around are more modest than with past generational jumps, they're still noteworthy, as are the additional financial and manpower resources now available to the Tensilica development teams by virtue of the Cadence purchase, boding well for the architecture's future.
Xtensa 11 and LX6's cache "way" control, for example, enables a programmer to dynamically adjust the cache mode while the processor is running, in order to optimize performance versus power consumption based on changing application requirements. One-through-four way set-associative cache options are supported, along with complete cache disable for direct processor access to external RAM and/or ROM. Related new instructions cast out write-back data when turning off a cache way, and initialize new data when turning it on.
Another latest-generation cache enhancement involves block mode, an extension of the architecture's existing optional L1 cache hardware prefetch module. Newly added instructions operate in the background on a series of data cache lines; using these instructions, a range of addresses can be prefetched into the cache, or cast out of the cache, or invalidated within the cache. Jones claims that block prefetch mode enables the memcpy function to run up to 6.5x faster and use up to 23% fewer bus cycles than before (Figure 1).
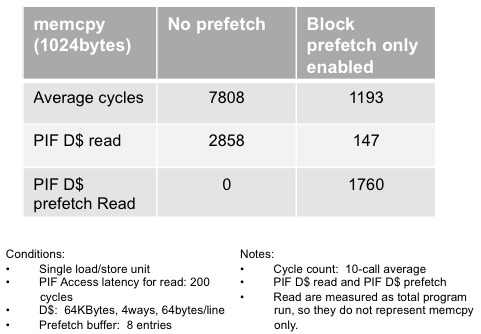
Figure 1. Depending on the specific characteristics of a particular memcpy operation, the performance increase and bus cycle count reduction resulting from the use of the new cache block mode hardware module can be substantial.
Speaking of memory, 32-bit parity and ECC options are now supported for both data cache and local memory; parity enables single-bit error detection, while ECC allows for multi-bit error detection and single-bit correction. While 32-bit ECC was possible in the past via four iterations of byte-wide ECC mode, it required 20 bits of incremental code memory per 32-bit word. Native 32-bit ECC support conversely requires only seven bits of code memory per 32-bit word, a 65% reduction.
Other architecture enhancements are development-centric versus processing-centric in nature. Xtensa 11 finally ("only twenty years late," Jones joked during the briefing) supports the XMON debug monitor library via a UART or TCP/IP interface to the processor, as an alternative to either on-chip debug hardware or a JTAG debug interface. DebugStall is a feature that enables synchronously stopping, debugging and resuming a multiprocessor system. After asserting the RunStall mode to freeze the target processors, DebugStall allows for system state probing via a JTAG debugger (de-assertion of RunStall restores normal operation).
And some of the generational enhancements are specific to the more advanced LX6 architecture variant. The FLIX (flexible length instruction encoding) options, for example, are even further expanded from their LX5 enhancements, for optimized code density and potentially improved parallelism. They're now available in any size from 4 to 16 bytes; FLIX instruction bundles can also now include CALL, RETURN and LOOP operations.
In addition to foundation Xtensa and LX processor core offerings, Cadence also offers DSP-focused ISA configuration variants such as BBE (BaseBand Engine, for communications applications), HiFi (for audio), and IVP (for image, video and vision processing) (Figure 2). InsideDSP covered the first-generation IVP two years ago; Cadence announced the Enhanced Performance successor one year later. IVP-EP delivers, according to the company, up to 4X the performance of the first-generation IVP via its support for additional imaging-specific operations to accelerate 8-, 16- and 32-bit pixel data types and video operation patterns. Originally scheduled for release in May 2014, IVP-EP is now available as an implementation option for LX6.
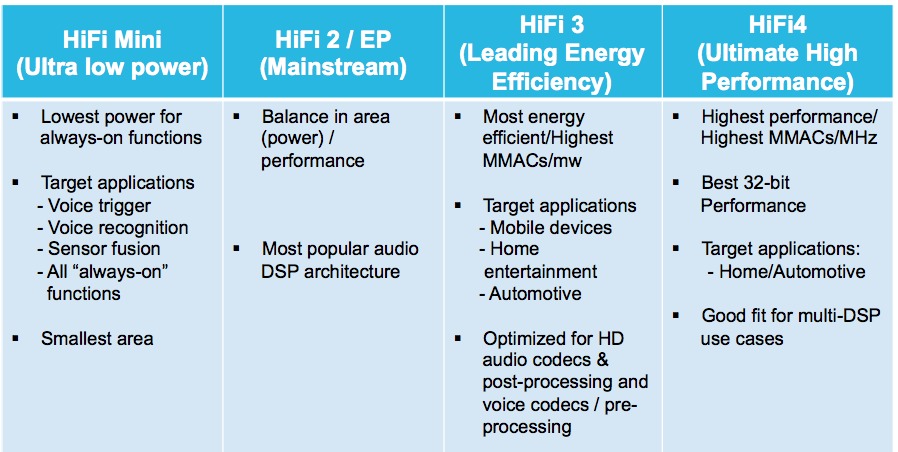
Figure 2. Instruction set variants of a foundation Xtensa core generation, such as the multiple members of Cadence's Tensilica HiFi family, focus on particular applications with various digital signal processing optimizations.
Another upgraded ISA variant, HiFi 4, was the primary focus of Cadence's January 2015 CES press release. InsideDSP discussed the HiFi 3 precursor in early 2012; HiFi 4 further builds on the architecture by migrating from a dual- to quad-32x32 bit MAC structure (Figure 3). HiFi 4 also implements a quad-issue instruction pipeline versus HiFi 3's three-issue approach, as well as doubling the load/store memory bandwidth of its predecessor. The four 32x32 MACs can alternatively support eight simultaneous 16x16 or (limited) 32x16 MAC operations. And beginning next month (with math library optimizations also in progress), HiFi 4 will also optionally support four-way single-precision vector floating point capabilities with only a "modest" silicon area penalty, according to Larry Przywara, the company's director of audio and voice IP marketing.
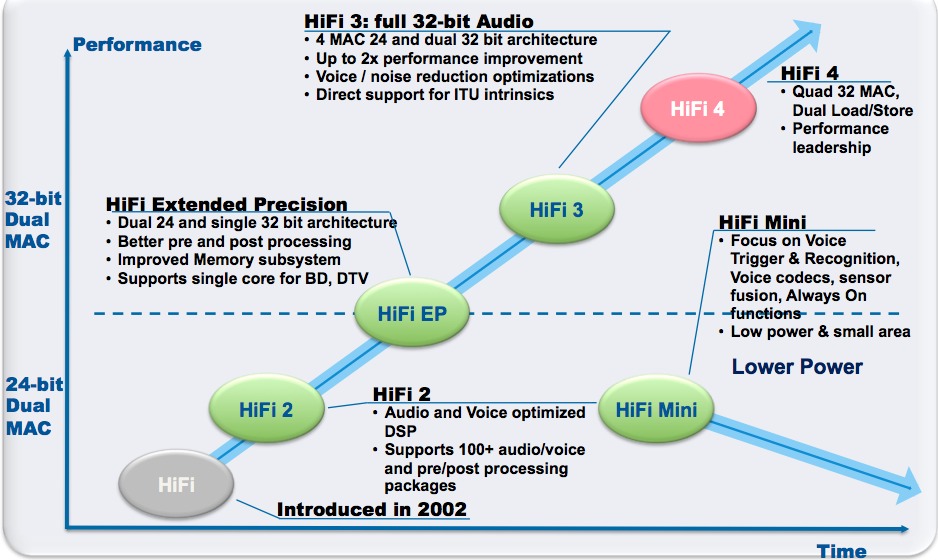
Figure 3. HiFi 4 doubles the on-core MAC resources of the precursor core, along with offering a four-way single-precision vector floating point option.
How will developers exploit the increased computational potential of HiFi 4 DSP cores, which target modest 28 nm process implementations (due to the need for mixed-signal function support in many SoCs)? Przywara suggests that emerging object-based audio technology, such as that implemented in Dolby's Atmos and Digital Theater System's DTS:X, is one key target application. Unlike conventional discrete surround sound schemes like Dolby Digital and DTS, in which the audio is pre-rendered into multiple channels during mastering for a particular assumed speaker orientation-and-location arrangement, object-based audio rendering is more flexibly done "on the fly" during playback based on the number, characteristics, and placement of available speakers.
Przywara notes that object-based audio technology, previously only offered in movie theaters (Walt Disney/Pixar's June 2012 film Brave marked Dolby Atmos' public unveiling), is now expanding into high-end home theaters and, like its surround sound predecessors, will eventually expand to mainstream home setups as well as automobiles and other listening environments. Speaking of vehicles, active cancellation of environmental noise via multi-microphone audio capture processing is another key application on Cadence'sradar screen, as are the beam-forming, recognition and other voice processing algorithms tackled by emerging consumer electronics products such as Amazon's Echo.
While the Xtensa 11 and LX6 enhancements over prior-generation cores are moderate, IVP-EP makes more notable improvements, with HiFi 4 being an even more aggressive advancement. And Cadence promises even more substantial architecture progression in the future; Jones made a point of noting during the recent briefing that the Tensilica core development team consists of 20% more engineers than was the case just 18 months ago.
*Kudos to those of you who picked up on the classic movie reference.
Add new comment