
Modern SoCs increasingly contain a variety of processing resources: one or more CPU cores and a GPU, often with a DSP, programmable logic, or one or multiple special-purpose co-processors for tasks such as computer vision. Properly harnessed, such heterogeneous processors often deliver impressive performance at low cost and low power consumption. But mapping applications onto heterogeneous processors is challenging. OpenCL, a specification standard language and runtime from the Khronos Group, enables the development of code that utilizes processing elements within a heterogeneous single- or multi-chip system. However, any processing efficiency gains derived from specialized computing elements can easily be negated by the added latency (not to mention incremental power consumption) incurred by copying data between computing elements.
Memory coherency among these diverse processing elements enables them to more efficiently share data via pointer-passing and queue-updating operations, versus bundling data and moving it via clumsy I/O operations through complex device drivers. Memory coherency has been common for some time in multi-CPU implementations; expanding the concept to GPUs, DSPs and other dissimilar architectures, however, is more challenging. OpenCL and other heterogeneous programming standards such as OpenMP and C++ AMP don't make any attempt to standardize memory coherency, which requires the implementation of specific hardware features in each processing element. That mission has been taken up by the HSA (Heterogeneous System Architecture) Foundation, an industry group that has its origins in AMD's proprietary Fusion System Architecture program (Figure 1).

Figure 1. The HSA Foundation boasts a sizeable, diverse membership list, but so far only AMD has chips implementing the organization’s standards.
Founded in mid-2012, the HSA Foundation released v1.0 of its specification suite in the spring of last year. And with newly announced, backward-compatible v1.1, according to foundation president Dr. John Glossner (who is also CEO of General Processor Technologies), the specification further expands beyond its AMD-centric foundations, supporting additional types of processor elements, as well as adding a number of requested features such as more flexible coherent memory access (Figure 2). SoC compatibility with the hardware aspects of the HSA specifications is becoming increasingly common, according to Glossner, and ARM for one agrees. In a recent briefing with Lead Mobile Strategist James Bruce and GPU Developer Tools Product Manager Anand Patel, the two ARM representatives noted that not only the latest Cortex-A73 and Mali-G71 but also the last several generations of ARM CPUs and GPUs are, in combination with newer CoreLink variants of ARM's AMBA (Advanced Microcontroller Bus Architecture) interconnect, fully compatible with HSA's memory coherency standards.


Figure 2. The initial v1.0 HSA specification was CPU- and GPU- specific, reflective of the AMD SoC platforms on which it was based (top), but the newer v1.1 spec is more vendor- and processor-agnostic, not to mention more flexible (bottom).
Hardware compatibility alone isn’t sufficient for full compliance with the HSA standards, however, which explains the current dearth of HSA-compliant SoCs in spite of significant industry backing for the HSA concept. At the core of HSA's software scheme is HSAIL (the HSA Intermediate Language), an intermediate virtualized code abstraction created by HSA-cognizant compilers, which is then dynamically translated to a particular processor's instruction set by a chip-vendor-supplied HSA Runtime layer. HSAIL-generating compilers are beginning to appear: AMD's CLOC and the TUT (Tampere University of Technology) POCL both generate HSAIL from OpenCL source code, for example, while General Processor Technologies and Parmance have developed gccBrig, a BRIG (binary format) language front-end to GCC (the GNU Compiler Collection) that is a binary representation of HSAIL. Also, Continuum Analytics sponsors Numba, an open-source Python compiler with direct HSA support, specifically targeting GPU acceleration.
However, to date HSA Foundation creator AMD is the only member company to have developed an HSA Runtime, and then only for its latest Carrizo APU (accelerated processing unit, a CPU-GPU combo), which entered volume production at the end of last year. Even in AMD's case, direct compilation to the end CPU and GPU instruction sets (versus to a HSAIL intermediate representation) is the preferred approach in AMD's ROCm (Radeon Open Compute Platform). While we expect to see increased adoption of the HSA standards by AMD and other HSA Foundation member companies, some major chip suppliers are pursuing different approaches. Intel, for example, seems to prefer the Cilk scheme it's championed, while NVIDIA continues to rely on its proprietary CUDA approach.
Researchers at Northeastern University recently validated that HSA, by removing the need for repeated data copy operations between heterogeneous processing elements, can dramatically improve algorithm performance– at least for a couple of algorithm examples (Figure 3). Three different memory access scenarios were considered: CL12 employs per-element buffers, while CL20 leverages a common albeit small shared virtual memory buffer; both employ only OpenCL. The full OpenCL-plus-HSA implementation, conversely, implements a unified memory space with fine-grained synchronization support, leverages regular pointers and doesn't require copy operations. The evaluated FIR (finite impulse response) filter algorithm represents a memory-intensive streaming workload; AES (Advanced Encryption Standard) symmetric encryption and decryption conversely is a compute-intensive streaming workload. Glossner was also careful to point out that these results were measured on AMD's Kaveri APU, which being a pre-HSA 1.0 device supports only limited coherent memory throughput.
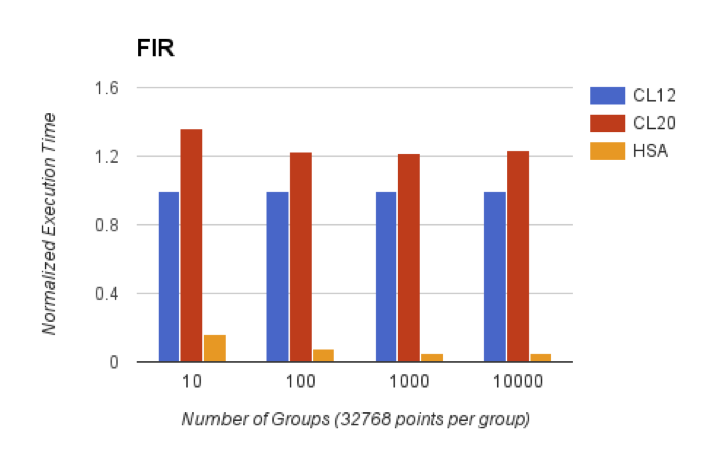
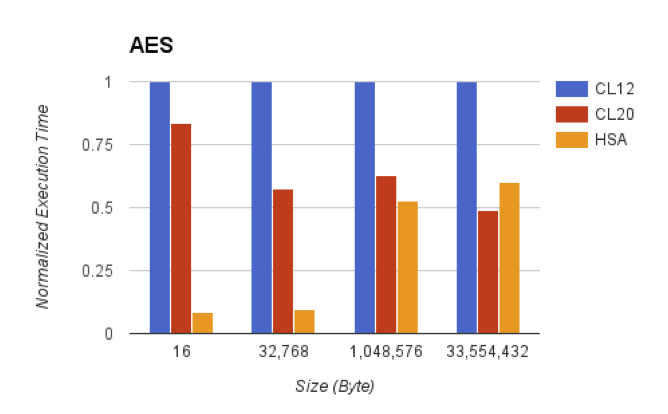
Figure 3. Recent evaluations conducted by Northeastern University researchers highlight HSA's performance-boosting potential in both memory-intensive (top) and compute-intensive (bottom) workloads, even with SoCs that aren't fully HSA-optimized (A Comprehensive Performance Analysis of HSA and OpenCL 2.0, Proceedings of the 2016 International Symposium on Program Analysis and System Software, April 2016).
Any performance loss due to the HSAIL-plus-HSA Runtime multi-layer abstraction will, Glossner feels, be more than counterbalanced by the significant performance boost delivered by HSA's support for full memory coherency between heterogeneous processing elements. AMD Carrizo APU-based systems are now shipping from PC OEMs such as ASUS, Dell and Lenovo, and Glossner anticipates additional HSA support announcements to arrive shortly from other SoC and IP core providers. Until then, though, HSA will remain an approach with industry-wide potential but limited deployment.
For more information on the HSA Foundation, see the following two videos from the May 2016 Embedded Vision Summit (Video 1 and 2).
Video 1. HSA Foundation Demonstration of OpenVX-based Harris Corner Detection and Optical Flow
Video 2. HSA Foundation Demonstration of OpenVX-based Skin Tone and Edge Detection
Add new comment