
[Editor's Note: In July, BDTI received a technology update briefing from Samplify, a start-up that has pioneered innovative approaches to, and applications of, data compression in embedded systems. Subsequently, rumors came to our attention suggesting that Samplify's investors are looking to sell the company. In response to our inquiry on this point, a Samplify representative said that it is company policy not to comment on speculation.]
Many modern embedded systems require enormous data bandwidth, and this is increasingly a central challenge in delivering sufficient performance at acceptable price and power consumption levels. For example, peruse the technical articles and tutorial videos on the Embedded Vision Alliance website and you'll repeatedly encounter references to the substantial amounts of data generated by image sensors, especially at high resolutions and frame rates, as well as the intermediate data generated by the various algorithms employed by vision systems. While processing this data through the appropriate algorithms tends to dominate discussions of vision application requirements, in fact shuttling data back and forth between main memory and the processor (along with intermediary caches) is often an equally, if not more difficult, requirement.
Other multimedia applications have similar bandwidth-taxing needs; those same rising-resolution image sensors are driving increases in the sizes of captured still images and video frame sequences, along with that of the displays that render them. As a result, smartphones and other multimedia-centric devices sport multi-core CPUs and GPUs, as well as DSPs and other special-function cores. And all of these resources are frequently contending for access to a common main external memory, connected to all of them via a common DDR bus (Figure 1).
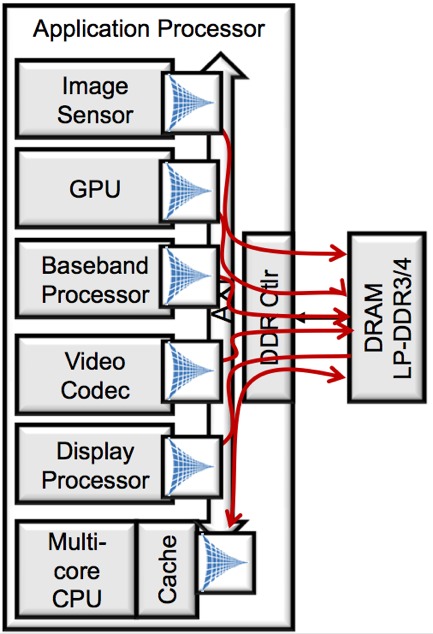
Figure 1. Increasing amounts and types of on-chip processing resources combine with increasing amounts of data to dramatically increase the required bandwidth between the common external memory and the remainder of the SoC.
Decreasing the required bus bandwidth may, in extreme cases, make the difference between a feasible and impractical system design. More generally, it can enable you to lower system power consumption, along with cost. Further cost reductions are possible if the bus speed decrease enables you to employ a multi-sourced commodity memory technology, versus a few- or sole-sourced specialized memory device. Compressing (i.e., encoding) data prior to passing it across the memory bus, then decompressing (decoding) it on the other side of the memory channel, is a potential means of accomplishing this objective.
But there's no free lunch. Encoding and decoding require computation, meaning they consume silicon area, power and time. For a compression solution to be attractive, the latency of encoding and decoding must not significantly degrade system performance, and the power cost of compression must be more than offset by the power savings enabled by the resulting lowered bandwidth requirements. Where lossy (versus lossless) compression is required to achieve a particular bandwidth reduction target, it cannot adversely impact perceived multimedia quality. And, of course, the incremental die size of the encoder and decoder circuits, along with the associated licensing fees for the compression and decompression cores, are critical cost factors, especially in high-volume, slim-margin consumer electronics and other similar product designs.
Samplify thinks it has come up with a credible solution. I first came across company founder, CTO and Chairman Al Wegener more than a decade ago while researching an article on audio compression techniques. His company was then known as Soundspace Audio, and its MUSICompress algorithm was somewhat unique in offering both lossless and user-configurable lossy compression options. As I wrote back in 2000:
Taking differencing techniques to the next step, you might choose to use a series of past sample values to predict the next value and then store the difference, or residue, between this prediction and the actual sample. Predictive, or delta, codecs differ from each other mainly in the predictive algorithm they use and the number of past samples the algorithm incorporates in its calculation. Some algorithms take prediction to multiple derivatives, predicting not only the sample but also its residue, its residue of residue, and so forth. Many lossless codecs include the option for additional lossy compression, which the codecs usually implement by dropping bits to reduce sample size in exchange for decreased dynamic range.
Soundspace Audio's MUSICompress, an all-integer algorithm provided in ANSI C source as well as object code for several CPUs and DSPs, takes advantage of the fact that most audio is oversampled and therefore contains more low-frequency components than high-frequency components. Inventor Al Wegener developed an approach that separates the original audio into subset samples (every nth—usually every second—sample) and removed samples. He then applies a simple approximation routine (a four-tap FIR filter) to the subset samples to approximate the removed samples. The error between the removed samples and their approximation is usually small, and MUSICompress therefore replaces a sampled data stream with the subset array and the error array. Subset samples then run through a first, second, and third derivative generator. The algorithm determines which derivative creates the smallest subset array.
After stints at Texas Instruments and several startups, Wegener returned to his compression roots with Samplify beginning in 2006. Initially, Samplify focused on compressing the data traversing between high-speed ADCs (analog-to-digital converters) and DSPs in cellular base stations, inspired by application trends Wegener had encountered during his time as a DSP architect and manager of the wireless radio products group at TI. Samplify's technology also found use in lossy compression of floating point data used in various supercomputer applications, achieving to a 3:1 or even 4:1 compression ratio with no significant change in results, according to Wegener.
Wegener states that while the company's compression algorithms approach hasn't fundamentally changed over the years, the implementation form has evolved; whereas MUSICompress primarily focused on a software implementation, the company's newer APAX (APplication AXceleration) offering is optionally available as Verilog RTL, along with an associated test bench (Verilog and Universal Verification Methodology) and SDK plus hardware driver (Linux, Android, iOS, and Windows) (Figure 2).
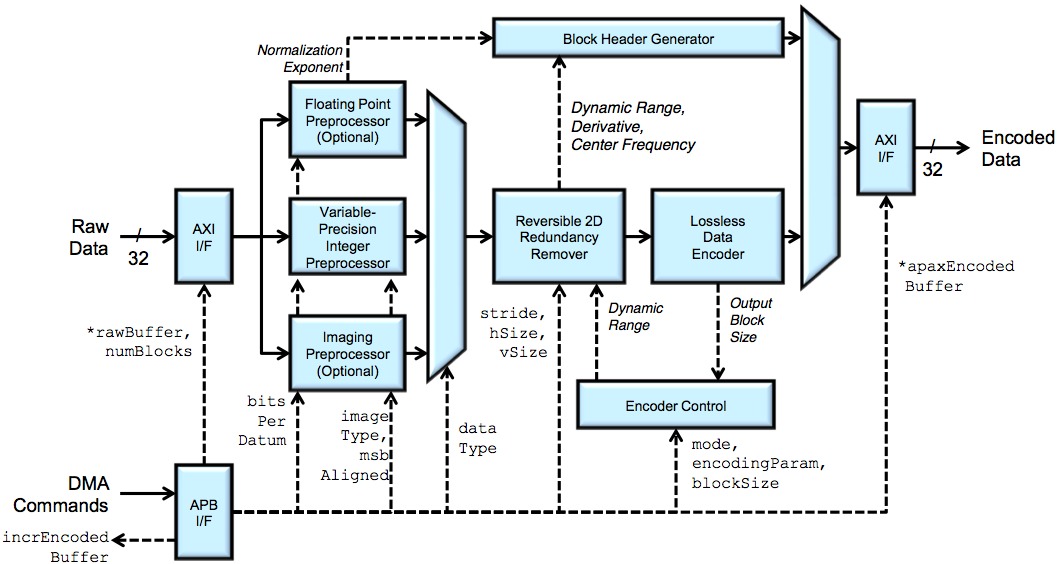
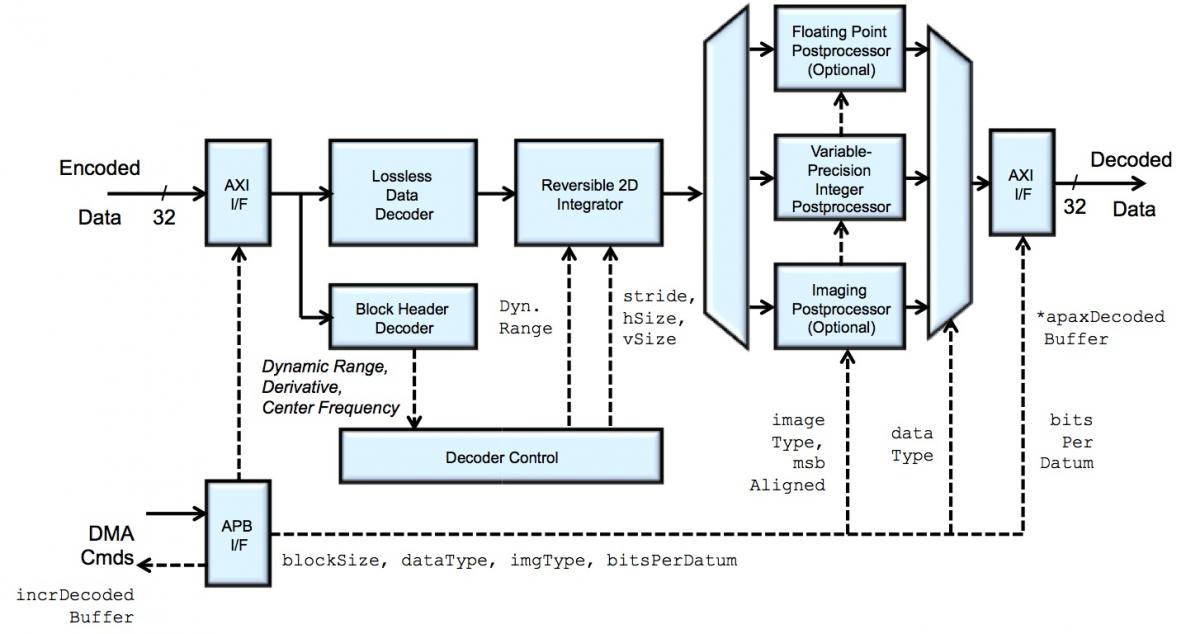
Figure 2. Samplify's APAX data compression encoder (top) and decoder (bottom) cores together "fit under a bond pad" on TSMC's 28 nm process, according to company founder, CTO and chairman Al Wegener
The 28nm process variant that Samplify uses as its APAX specification basis is TSMC's HPM (High Performance Mobile) flavor (Table 1).
|
Specification |
Value |
|
Area (encoder plus decoder, plus all required FIFOs and memories) |
0.078 mm2 |
|
Clock speed (encoder and decoder) |
600 MHz |
|
Dynamic power consumption (encoder plus decoder, plus all required FIFOs and memories) |
6.7 mW |
|
SoC interface |
32-bit ARM AMBA (Advanced Microcontroller Bus Architecture) AXI (Advanced eXtensible Interface) |
|
Encoder latency |
18 clocks |
|
Decoder latency |
18 clocks |
Table 1. APAX encoder and decoder core specifications on TSMC's 28 nm HPM process.
Encoding (compression) mode options include lossless, fixed-rate (i.e. variable quality) lossy, and fixed-quality (i.e. variable-rate) lossy. Supported data types include 8-, 16- and 32-bit integer and unsigned integer, as well as 32-bit floating point. Packed image format options include the Bayer pattern "raw" matrix from an image sensor, along with RGB, RGBA, and 4:4:4 YUV (higher compression ratios can generally be achieved with YUV versus RGB). Both 4:2:2 and 4:2:0 planar YUV options are also available, and all the supported image formats can come in 8-, 10-, 12-, 14-, and 16-bit color depth variants. Encoded data can be organized in memory in scalar, vector, matrix, raster, and macroblock modes, both multi-stream and multi-threaded encoding implementations are possible, and decoded data can be read back out of memory in either random- or sequential-access patterns.
Samplify's memory bandwidth and power consumption reduction claims for APAX working on image data are impressive (Table 2). Another case study presented in our briefing involved a gesture-recognition algorithm operating on a point cloud data set, which was initially memory bandwidth-bound at 36 fps. APAX encoding was then applied to the underlying point cloud data at a 4:1 encoding rate, resulting in a memory bandwidth decrease of 75 percent and lowered power consumption from memory transactions by 50 percent. Wegener admits that although these numbers are "typical," in some cases they may be too aggressive; they're dependent on the specific characteristics of the source material, along with the required fidelity.
|
Data and Image Type |
Memory Bandwidth Reduction |
Power Reduction |
|
2D Graphical User Interface |
86% |
82% |
|
3D Graphics, Gaming |
||
|
Textures (RGB 4:4:4 8 bit/color) |
66% |
62% |
|
HDR textures (RGB 4:4:4 16 bits/color) |
88% |
84% |
|
Wireframe/vertex coordinates (32-bit floats) |
80% |
76% |
|
Image Capture & Processing |
||
|
Bayer Matrix 14-bit |
72% |
68% |
|
Motion Estimation (YUV 4:2:2 10-bit) |
66% |
62% |
|
Mobile Video Playback of H.264 Reference Frames (YUV 4:2:0 8-bit) |
69% |
59% |
Table 2. Samplify's estimates of typical compression and power consumption savings percentages for various source material types.
Wegener also acknowledges that the system power consumption improvement garnered by the use of APAX is dependent on the percentage of total system operating time that multimedia operations such as video recording and playback are active. With respect to other notable battery life limiters such as a display backlight, he notes that the benefit of a technique such as APAX is magnified when other power management technologies such as panel self-refresh are also in active use. And as clarification, he notes that ARM's relatively new frame buffer compression scheme is lossless-only; APAX also offers various lossy-compression options.
What compression settings should you dial in for your particular source data and desired quality combination? That's where the company's APAX Profiler software comes in (Figure 3). After you provide a reference input data set and select a particular compression mode and level, APAX Profiler will output compression ratio, error ratio, and other data that enables you to quickly quantify the results and, by iteratively running various scenarios, assess which compression options are optimum for your particular application.
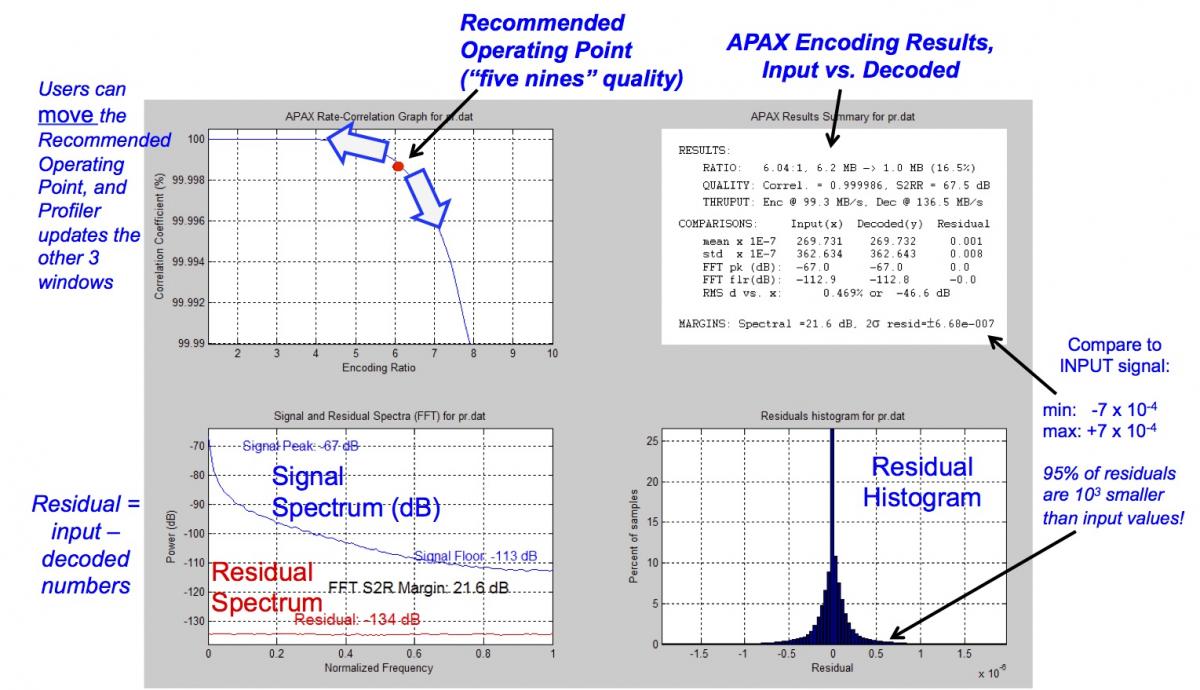
Figure 3. Samplify's APAX Profiler utility enables you to determine the encoder settings needed to achieve your compression ratio and fidelity targets.
Wegener notes that it's possible to retain robust video quality with aggressive APAX compression ratios, even when periodic reference frame-based compression algorithms are in use. As an illustration of the concept, he offers up a case study using the "Old Town Cross" reference clip, to which Samplify applied H.264 compression and further compressed to a 3.5:1 average ratio using APAX (Figure 4). The combination of APAX and a now-mainstream lossy video compression scheme such as H.264 provides an intriguing alternative to emerging next-generation compression algorithms like H.265.
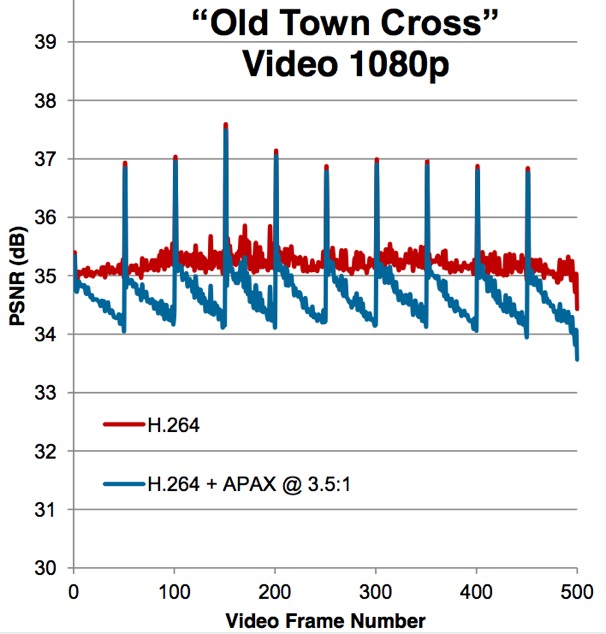
Figure 4. APAX compression at a 3.5:1 ratio retains reasonable PSNR levels even with long-sequence inter-frame GOP (group of picture) lossy-compressed source material such as H.264 video.
And why wouldn't a processor designer alternatively alleviate system memory bandwidth pressures by further increasing the amount of on-SoC cache? Wegener has a ready response, suggesting that a visual perusal of a modern SoC die plot holds the answer. A compression engine that "fits under a bond pad," in his words, is economically far preferable to enlarging cache arrays that in aggregate consume one third or more of the total die area. When pressed to quantify his economic viability claim with licensing costs, however, Wegener declined to give NRE and royalty numbers, aside from noting that "most companies don't typically like to pay" the latter and therefore a "buyout option" is also available. Finally, when asked whether beyond-ARM (specifically, Intel Atom x86 or equivalent) licensee options were possible, given the company's current seeming full reliance on the AMBA AXI interface, Wegener again demurred on a specific response, indicating only that Samplify was in regular discussions with many current and potential licensees, including "all major semiconductor suppliers."
Add new comment