
Implementing real-time video processing functions in software is a challenging task. In this article we explore the particularly difficult challenges presented by video compression algorithms. Although we focus on video compression algorithms, the ideas and techniques in this article also apply to other types of video processing software.
What’s Unique about Video Software?
Software development for video applications presents many of the same challenges as those found in other embedded signal processing applications. High computational demands coupled with a need to keep costs low in consumer products often mean that aggressive software optimization is required. Non-deterministic timing of processor features such as caches can make it difficult to guarantee that software will meet strict real-time constraints. Developing efficient implementations of signal processing algorithms on today’s complex processors requires in-depth understanding of both the algorithms and the processor architecture, so engineers often face a tough learning curve when working with new algorithms or processors.
But video applications compound these challenges. For example, requirements for large amounts of memory and high memory bandwidth in video applications often present additional optimization constraints and software development challenges. And video applications and algorithms tend to be particularly complex.
Video Product Software Anatomy
Figure 1 illustrates the anatomy of software in a typical video product. A real-time operating system schedules application tasks, manages I/O device drivers, and maintains file systems on the mass storage devices. A player/recorder application interprets user commands and manages signal processing modules such as audio and video encoders and decoders, image scaling, color conversion, and audio equalization.
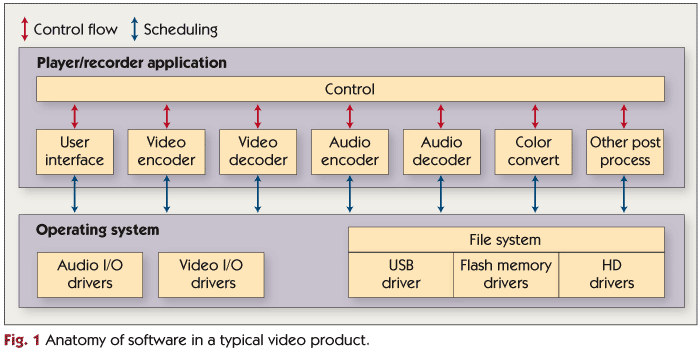
In many video applications a single processor is not capable of performing all of the desired signal processing tasks. In such cases, one or more signal processing modules are often implemented using additional processors and/or fixed-function hardware. For example, the video decoder task shown in Figure 1 might manage communication and synchronization with a video decoder running on a separate DSP processor instead of actually performing the decoding on the host processor. Alternatively, the video decoder task may perform some of the decoding, and utilize additional hardware such as a DSP or fixed-function accelerator to offload some of the most computationally demanding portions of the video decoding algorithm. See “Processors for Video: Know Your Options” for more information on processors used in these applications.
Putting the Pieces Together
Ideally, all of the software components required for the application are available as licensable off-the-shelf modules. Operating systems, video and audio encoders and decoders, and many common pre- and post-processing functions are available as off-the-shelf modules targeting a variety of processors. However, application software often must be written from scratch. Occasionally a suitable reference design may serve as a reasonable starting point.
Even when most of the needed software components are available in off-the-shelf form, integrating these components can be a significant undertaking. For example, maintaining synchronization of audio and video codecs during recording or playback can be tricky. To maintain synchronization, application software must read and write timestamps embedded in the multimedia stream. This can sometimes require compensation for delays introduced by pre- or post-processing modules.
Starting from Scratch
Implementing a complex signal processing module such as a video decoder or encoder is probably the most challenging software development task in video applications. (See “Squeeze Play: How Video Compression Works” in the March 2004 edition of Inside DSP for an introduction to video compression algorithms. Also see “H.264: The Video Codec to Watch” for details on the popular new H.264 algorithm.) Aggressive optimization is typically required in order to get video applications to meet cost and power targets. When the desired module isn’t available from the processor vendor or a third party and must be developed from scratch, knowing where to start is often the first hurdle.
The complexity of today’s video compression algorithms can make standards specifications difficult to understand, so implementing an encoder or decoder from scratch is a daunting proposition. Reference source code is available for most standards-based encoders and decoders. However, such reference code is typically written to illustrate the standard specification rather than to implement the algorithm efficiently. In addition to being inefficient, reference code may include superfluous code such as unneeded debugging modes. Therefore, such reference source code is awkward to use as a basis for an efficient implementation of the encoder or decoder.
Most video standards precisely specify the compressed bit stream format and the behavior of the decoder, but do not specify the behavior of the encoder. This allows developers to use their own proprietary algorithms for critical encoding steps such as motion estimation. Encoder implementations can thus compete for highest video quality or lowest bit rate, or make tradeoffs between quality, bit rate, and computational demands. Reference source code merely illustrates one possible encoding algorithm, and developers should carefully consider other approaches—such as alternative motion estimation search heuristics—if they have the requisite algorithm design expertise.
In contrast, video pre- or post-processing algorithms are typically simple compared to an encoder or a decoder. Some algorithms such as color conversion are well known, while others such as video deinterlacing are proprietary. Often reference source code is unavailable, and in some cases algorithm design is required.
Whether starting from scratch or electing to rework reference source code, it generally makes good sense to first create an “implementation reference.” This version of the code includes only the features of the standard that are relevant to the application at hand. It is designed with efficient implementation in mind, but omits any platform-specific optimizations. This allows high-level optimizations and design choices such as selection of a motion estimation algorithm independently of any platform-specific implementation steps. The implementation reference should be written in a high-level language so that it can easily be compiled and run on a workstation for ease of coding, testing, and debugging.
Once the implementation reference conforms to the standard specification, the implementation reference can be ported to and optimized for the target platform. During this step, the implementation reference provides an additional advantage: The data structures and control flow of the final optimized implementation will closely match those of the implementation reference. The implementation reference running on a workstation can therefore serve as a valuable tool in debugging the optimized implementation. For example, the reference implementation can readily be instrumented to provide test vectors for individual functions or to observe the correct contents of data structures at a specific point in time, in order to track down elusive bugs.
Make It Quick
Speed optimization is a critical part of implementing demanding embedded signal processing software. Traditionally, programmers have relied on the “80/20 rule:” in most signal processing applications, roughly 80 percent of the processor cycles are spent executing about 20 percent of the code. Therefore, programmers are generally able to profile the algorithm reference code to identify key portions—the 20 percent of the code where the processor spends the bulk of its cycles—and then focus their optimization efforts on these small algorithm kernels. However, this rule may not apply for the latest video compression standards. Emerging video compression standards such as H.264 are more complex than their predecessors, since they employ a greater number of signal processing techniques and modes of operation in an effort to increase coding efficiency. For example, the H.264 standard allows the encoder to select from 19 different modes of intra-prediction on a per-macroblock basis (refer to “H.264: The Video Codec to Watch” for an explanation of intra-prediction). Each of these modes typically must be implemented independently from the others for optimal performance, requiring its own block of code. Due to the rising complexity of compression algorithms, processors are spending a smaller percentage of their time in any single block of code, and a higher percentage of those cycles in decision-making control code. When implementing these new standards in software, programmers will therefore have to optimize larger portions of code compared to older standards.
Additionally, determining which portions of the code to optimize most aggressively can be tricky for video encoding and decoding algorithms. In most video compression standards, each encoded frame in a video sequence falls into one of three categories: I-frame, P-frame, or B-frame (see “Squeeze Play: How Video Compression Works” in the March 2004 edition of Inside DSP for an explanation of these frame types). B-frames and P-frames are much more common than I-frames. Therefore, encoding or decoding tasks that execute frequently when processing an I-frame but infrequently for a P-frame or a B-frame will constitute only a small portion of the algorithm’s computational demands on average. Such tasks are likely to appear insignificant in an execution time profile. However, these tasks can represent a significant portion of the computational demands of encoding or decoding a single I-frame. In some cases, it may be necessary to optimize these seemingly insignificant tasks in order to guarantee that the encoder and/or decoder will always meet its real-time deadlines for any frame. For example, Figure 2 shows execution time profiles of an MPEG-4 video decoder operating on an I-frame, a P-frame, and a mix of I-frames and P-frames. Note that the AC/DC prediction task takes up about 26% of the execution time of an I-frame. But because P-frames do not perform AC/DC prediction, this task appears insignificant when a typical mix of I-frames and P-frames is profiled.

The large number of options specified in standards such as H.264 for encoding each image block can further confuse matters. The frequency with which each option (such as the 19 intra-prediction modes mentioned above) is selected depends heavily on the content of the video clip being processed, and on the particular encoding algorithm used. To ensure that an execution time profile of a video encoder or decoder is realistic, profiling must be performed using a wide variety of video content. If a video product must be capable of playing video compressed by a variety of different encoders, profiling of the video decoder must be based on a combination of video streams created with a variety of encoders, in addition to utilizing diverse video content.
In addition to individually optimizing critical algorithm kernels, intelligent arrangement of data in memory can yield significant speed improvement on processors with caches or processors that utilize multiple memory banks with differing bandwidths. In particular, reference frames in video encoders and decoders are invariably much larger than a processor’s level-one data cache, often resulting in poor performance on motion estimation and motion compensation. Therefore, on processors with caches, reference frames are typically divided into rectangular tiles that are small enough to fit in the processor’s data cache. During motion estimation and motion compensation, most of the accesses to the reference frame are likely to fall within the same tile as the block being encoded or decoded, so cache performance is greatly improved with this arrangement. Tiling the reference frames in this fashion increases the work required to compute the addresses of pixels in the reference frame, especially in the rare cases where consecutive accesses must cross tile boundaries. However, the benefits of this optimization are significant, including increased speed and lower demands on main memory bandwidth, which can also reduce power consumption.
Sharing the Load
The intense computational demands of many video encoders, decoders, and post-processing modules can exceed the capabilities of a single programmable processor. In such cases, dedicated coprocessors are often used to offload some of the demanding algorithm kernels from the main processor. Alternatively, entire algorithms may be assigned to different processors in a multi-processor system. When partitioning algorithms or portions of algorithms among multiple processors and/or coprocessors, care must be taken to avoid bottlenecks due to inter-processor communication and synchronization.
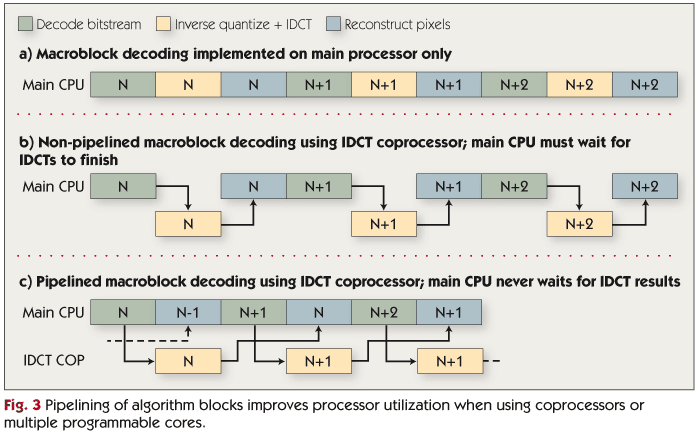
Software should be designed so that the most heavily used processor in the system spends as few cycles as possible waiting for tasks to complete on other processors or coprocessors. This generally requires pipelining the sequence of algorithm kernels used in the application, as illustrated in Figure 3. For example, a straightforward, non-pipelined video decoder implementation might decode a macroblock, then perform dequantization and the IDCT, and finally perform the steps needed to reconstruct the pixels for the macroblock. These steps are shown in Figure 3a. If the IDCT is offloaded to a coprocessor, the main processor may have to wait for the IDCT to complete before it can finish reconstructing the macroblock, as shown in Figure 3b. In a pipelined implementation, however, the main processor works in parallel with the IDCT coprocessor. In the example shown in Figure 3c, the IDCT coprocessor operates on macroblock N while the main CPU reconstructs the pixels for macroblock N-1, so the main processor never has to wait for the IDCT coprocessor. Such pipelining may necessitate significant restructuring of the application’s control code.
Does It Work Yet?
Embedded applications require thorough, rigorous testing. To rigorously test a video processing algorithm, its output must be captured and compared against known-good reference output data. The high bandwidth of video signals makes this task difficult. The end product often does not provide digital I/O ports with sufficient bandwidth to output a video signal. While an LCD screen is able to display video and an analog video output is often available, only a high-bandwidth digital output enables capturing of exact pixel values in real time.
An alternative to capturing the application’s output via a digital I/O port is to store uncompressed reference output on the target hardware, allowing the application to test itself by performing the comparisons internally. However, the product hardware often cannot hold much uncompressed reference data. In such cases only short video sequences can be tested using this technique, and this limits the developer’s confidence that the product is working properly.
One way to overcome this bandwidth problem is to compute a checksum for every frame of video output. The checksum acts as a signature for the frame, and is compared with a checksum computed for the corresponding frame of reference output data. The probability that multiple errors in the output frame cancel each other and yield the correct checksum is very low, so this method provides very high confidence that the video output exactly matches the reference output. Since the checksum comprises only a few bytes per video frame, it is feasible to capture the output checksums via a low-bandwidth I/O port or to store a long sequence of reference checksums on the target platform.
This method enables testing video output for bit-exact equivalence to the reference data, but doesn’t indicate the magnitude of errors or the location of errors within a frame. If a frame is detected that is not equal to the corresponding reference frame, the application can be halted and the individual output frame can be examined to determine the nature of the errors.
Sometimes it isn’t practical to test video software by checking for bit-exact equivalence to reference data. In some applications, reference code uses certain arithmetic operations—such as saturation or rounding—that are not well supported by the target processor. Modifying these arithmetic steps slightly to better match the processor architecture can greatly improve the efficiency of the implementation. Such modifications also mean that the implementation output will be slightly different than the reference output. These small output differences are acceptable in some applications. In such cases the designer must be able to rigorously test an implementation that doesn’t produce bit-exact results.
With a little work, the checksum method described above can be applied to an implementation that doesn’t produce bit-exact results. First, a new version of the reference code is created. This new version uses the same slightly modified arithmetic as the target implementation. Thus, the new reference is a model of the target implementation, and the output of the target implementation should be bit-exact compared to this model.
Note that comprehensive and rigorous objective testing is often not sufficient to ensure a quality product. Many issues such as bugs in an LCD display driver implementation or poor synchronization of audio and video can only be detected through many hours of subjective tests using a wide variety of video content, and by testing every feature and mode of operation of the product.
Bigger, Better, More
Processors are increasingly capable of handling video application workloads. Real-time video processing tasks that once required dedicated hardware can now be implemented in software. Today many software developers are tackling real-time video processing for the first time, but in the coming years we can expect software implementations of video functions to become commonplace.
The newfound ability to process video in software will also change the very nature of emerging video processing algorithms. Dedicated hardware has traditionally provided the processing power to handle real-time video applications. While dedicated hardware is well suited for implementing simple, repetitive computations, it is often impractical for algorithms that require complex control and decision making. But programmable processors handle complex decision making with ease. New video processing algorithms are likely to become more sophisticated and complex than their predecessors as they take advantage of the decision-making prowess of programmable processors. Today this is most apparent in the realm of video compression, where standards and algorithms are already increasing in complexity in order to squeeze the highest possible quality into as few bits as they can.
In the coming years, we can expect other types of video algorithms to follow the same trend. For example, software implementations of sophisticated motion-compensated deinterlacing and frame rate conversion algorithms are likely to find their way into consumer devices such as TV sets and DVD players as the cost of implementing these complex and demanding algorithms drops.
For software developers eager to meet the many challenges of implementing, optimizing, and testing these sophisticated algorithms, this is good news!
Add new comment