
Cost- and power consumption-sensitive digital signal processing applications tend to leverage fixed point processors, for a common fundamental reason: fixed-point processor cores are substantially less complex than their floating-point counterparts, leading to reductions in transistor count and silicon area. Yet fixed-point processing comes with trade-offs of its own; code development, for example, is complicated by the need to comprehend the potential for overflow, underflow and round-off errors. And floating-point processors also tend to support wider data words and are therefore inherently capable of higher dynamic range.
A floating-point digital signal processor is often preferable to its fixed-point counterpart, therefore, in traditional markets such as high-end audio and image processing and various medical and military/aeronautics systems. And were a floating-point processor to ever achieve fixed point-like cost and power consumption metrics, it might also be of interest in consumer electronics' embedded vision and multimedia processing and other mainstream high-volume applications. Adapteva, with the company's Epiphany platform, believes that its floating point DSP architecture is optimized for such tasks, and the recent combination of a cash infusion and a successful 28 nm lithography shrink bolster the company's confidence. Adapteva does not intend for Epiphany to be a standalone processor; instead, it will act as a high-performance floating point co-processor, either integrated on the same die as an ARM, MIPS, x86 or other processor core, or alongside the primary CPU as a standalone chip.
Adapteva was founded in 2008 by Andreas Olofsson, formerly a lead designer on Analog Devices' TigerSHARC DSP product line. Olofsson and his peers pursued a clean-slate approach to both architecture and instruction set development, targeting a mesh-interconnected "many-core" implementation that is fully C++ programmable (Figure 1). The per-core dual-issue RISC processor, capable of simultaneously executing one integer arithmetic operation (or floating-point load or store operation) and one floating-point arithmetic operation per clock, is intentionally elementary. It contains no cache, relying instead on 32 KBytes of SRAM, and it eschews a memory management unit for a flat 32-bit memory map. There are no hardware- instruction reordering capabilities; the compiler is responsible for code optimization. Although Epiphany supports single-precision add, subtract and multiply operations, there's no hardware support for higher-complexity arithmetic such as division and square root, nor for double-precision math. Epiphany is also not fully IEEE 754–compliant.
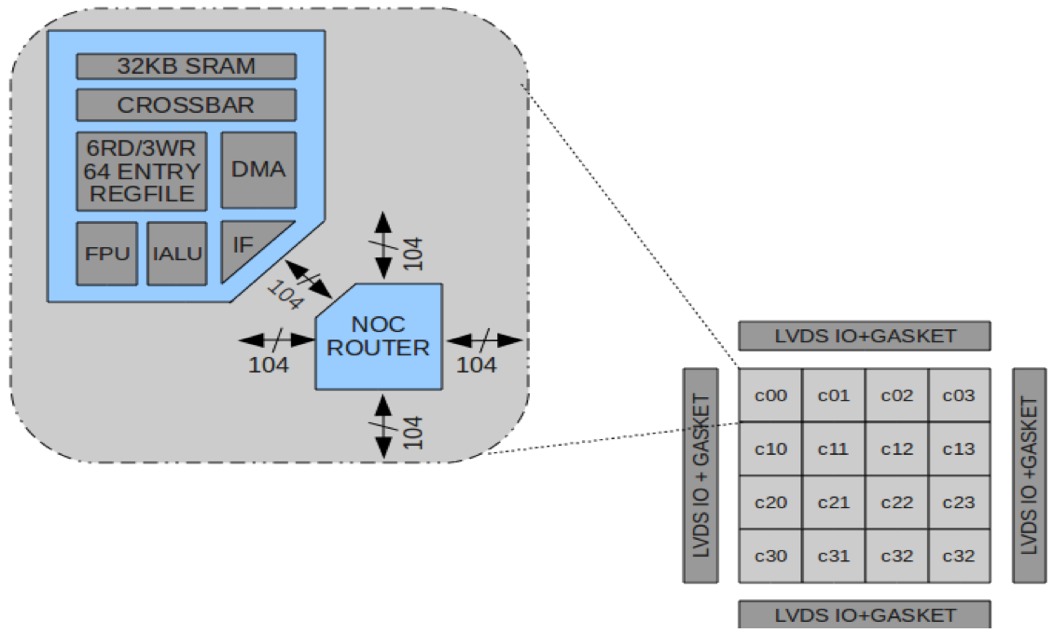
Figure 1. The tile-based Epiphany architecture achieves its silicon area, power consumption and performance results via leveraging "many-core" parallel processing
However, Adapteva claims that for the floating-point operations Epiphany does comprehend, it is an able performer both in terms of raw number-crunching capabilities and (particularly) when power consumption and cost are factored into the equation. The initial 65 nm 16-core chip version, which achieved first silicon availability in May 2011, ran at 1 GHz with 2 GFLOPS of peak processing performance and 2 watts of peak power consumption (Figure 2). The initial follow-on 28 nm product contains 64 cores and is now sampling after several schedule delays, with minor evolutions in the instruction set, DMA engine and inter-core connectivity schemes.
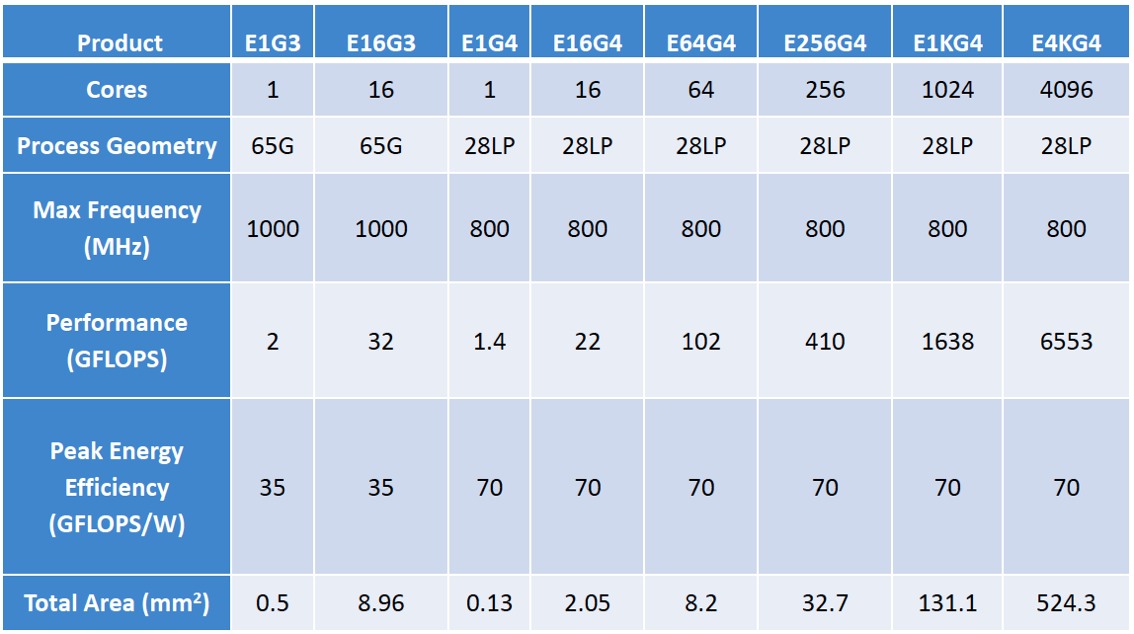
Figure 2. The E16G3 (65 nm) and E64G4 (28 nm) represent the first two standalone co-processor IC implementations of the Epiphany architecture, which is also capable of being integrated as an embedded core on a SoC
Epiphany runs at only 800 MHz on 28 nm, by virtue of its reliance on a low-power GlobalFoundries process versus the high-speed (and high leakage) process used in the precursor device. But it still only burns 2 watts of peak power (~25 mW per core, plus periphery power consumption overhead; alternatively 80 mW of total idle power) despite containing 4 times the core count. And those incremental cores lead to more than 100 GFLOPS of peak computational "muscle", while still translating to a smaller overall die size than with the 16-core 65 nm predecessor.
Epiphany is a tile-based approach, with multiple 104-bit buses (source and destination addresses, plus data) interconnecting each CPU core and associated SRAM array, with each link capable of 8 GByte/sec transfer speeds. Each mesh link "hop" incurs only 1.5 nsec of latency; effectively harnessing the cumulative capabilities of multiple cores in parallel via efficient inter-core communication is key to high-performing high-level functions. Adapteva is only a five-person company; it relies on partner (and investor) BittWare for board development and on UK-based Embecosm for compiler support. More recently, Adapteva announced an OpenCL SDK for Epiphany, completed in partnership with Brown Deer Technology. Robust compilers and other software development tools that efficiently and consistently harness the Epiphany "many-core" silicon potential will be critical to Adapteva's likelihood for success.
In a semiconductor world dominated by big-budget, large-headcount development projects that are constrained by instruction sets and other legacy confines, Adapteva's barebones and clean-slate approach is a notable divergence from the norm. The company's long-term fortunes are by no means certain; BittWare is currently the sole announced licensee, and Olofsson admits that while many other potential customers are currently taking a "look-see" at Epiphany, none of them prefers to be the first to take the plunge on an unproven approach. Nonetheless, that Adapteva has even made it to this point is notable, and the belated but ultimately fruitful migration of Epiphany to a 28 nm silicon foundation should bolster its chances.
Add new comment