
Over the past 25 years, programmable logic devices have grown in capacity and capability through lithography advancements and the integration of specialized functional blocks. First were dedicated memory arrays derived from the same SRAM used to build logic cells. Next came dedicated-function logic blocks such as multiply-accumulate units (MACs), to accelerate digital signal processing and other math-intensive algorithms, along with the integration of high-performance transceivers to speed the flow of data onto and off the FPGAs. And more recently, MACs and their ilk have been supplemented by even higher-complexity logic blocks, such as the dual-core Cortex-A9 ARM CPU subsystem in Xilinx's Zynq-7000 Extensible Processing Platform devices.
As FPGAs have evolved, the means by which engineers create FPGA designs have also evolved. (Raise your hand if, like me, you still remember hand-crafting simple PAL, PLD and FPGA designs using ABEL, CUPL and PALASM...and if it feels like just yesterday that you were doing so!) In particular, design techniques employing increasingly higher levels of abstraction have been required to address the increasing chip capabilities. Initial FPGA design flows were schematic-based. These later gave way to HDLs (hardware description languages) such as VHDL and Verilog. And more recently, C-language-based high-level synthesis has entered the mainstream, after years' worth of research and development and early-adopter experimentation.
Effective high-level-language-based FPGA design flows have become desirable (by implementers) and sought after (by suppliers), since at least in theory they can enable big gains in design and verification productivity. C-language-based flows are particularly attractive in that they offer the potential for relatively straightforward hardware acceleration of functions that would alternatively run in software on a system processor. Enabling flexible (and rapid) movement of the hardware-versus-software partition in order to assess design alternatives becomes increasingly attractive once, as with Xilinx's Zynq-7000 EPP devices, the FPGA fabric and the microprocessor share the same sliver of silicon.
And even for designers committed to existing HDLs, the associated tools must evolve to keep pace with growing device capacity and complexity, and with design methodologies that are evolving to address that growing capacity and complexity, such as the increasing reliance on design reuse and IP cores (in diverse formats from HDL source to pre-placed-and-routed blocks). In the face of intensifying time-to-market pressures in many industries, the speed and efficiency of FPGA design tools has become an increasingly critical consideration, including how those tools handle late-stage ECOs (engineering change orders).
So it was that, approximately five years ago, Xilinx decided to implement a ground-up redesign of its FPGA toolset, at the time called ISE. The result, Vivado, was publicly unveiled in April after 500+ person-years of R&D, along with a year-long private beta testing period that included more than 100 customers (Figure 1).
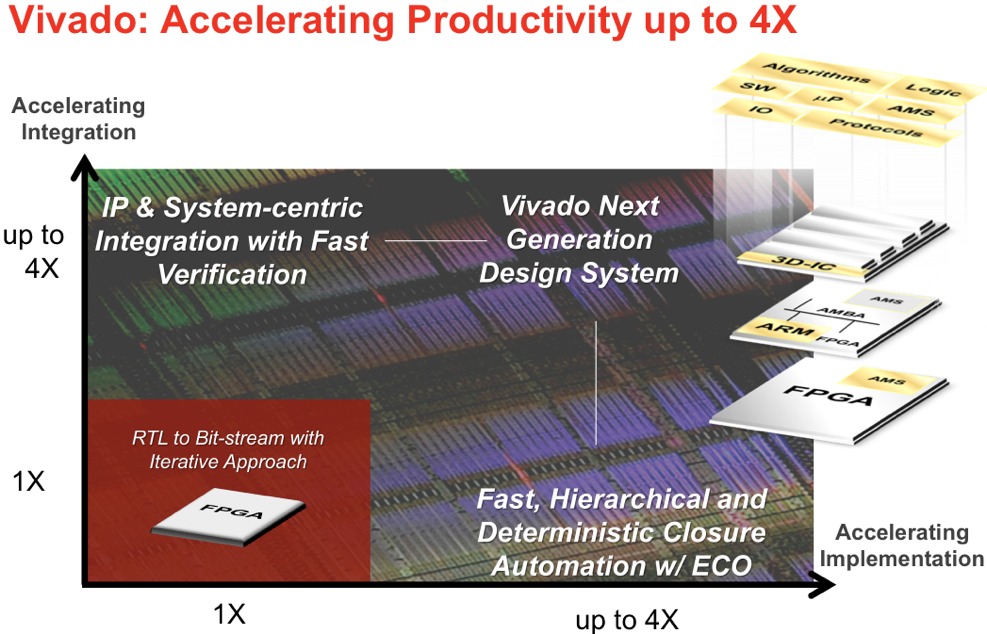
Figure 1. In responding to the increasingly diverse and challenging demands of today's designs, Xilinx strove with Vivado to improve numerous toolset capabilities versus those in the ISE predecessor: design entry (including IP integration), functional and timing verification, place-and-route speed and efficiency, etc.
Following the April announcement, however, Vivado's use was still restricted by Xilinx's "early access" approval process. But as of a few days ago, the toolset is publicly available to all Xilinx customers. Vivado supports the company's 28 nm-fabricated "7 Series" products; Artix-7, Kintex-7, and Virtex-7, with full integration support for system-level functions such as the Zynq-7000 CPU core to follow in the near future. Users of earlier-generation Xilinx FPGAs (such as implementers of designs using lower-complexity Spartan devices, or automotive, defense or space electronics designers for which qualified "7 Series" products are not yet available) will need to continue to use ISE.
To get a sense of Xilinx's underlying motivation for the Vivado clean-slate development approach, consider that ISE's synthesis engine, XST, dates from Xilinx’s 1998 acquisition of MINC. Similarly, the ISE place-and-route engine came from Xilinx's acquisition of NeoCAD in 1995. Other elements of the ISE toolset were of similarly disparate and dated origins, and in spite of Xilinx's admirable engineering efforts to keep tool capabilities in stride with the company's silicon advancements, ISE was increasingly showing its age. Another key shortcoming of Xilinx's ISE diversely sourced tool set approach was that tool-to-tool data transfer employed an array of incompatible data formats, making cross-probing of the design at various stages (HDL, LUTs, waveforms) a challenging aspiration. And tools' scripting capabilities, if they even existed at all, harnessed a diversity of incompatible language constructs.
Xilinx intends for Vivado to address all of these ISE shortcomings, both now and in the future, since the company forecasts that the toolset will be scalable to future FPGA-based device families of greater than 10 million logic cells. One key advancement involves the place-and-route engine; whereas ISE relied on a legacy timing-focused simulated annealing algorithm whose time (pun intended) had come and gone, Vivado transitions to a more modern, ASIC-like multi-dimensional P&R "engine" that simultaneously comprehends not only timing but also congestion and wire length minimization goals. As such, it produces not only faster and more resource-efficient results in the initial design "pass", it also responds more favorably to inevitable incremental re-designs due to ECOs, according to Xilinx (Figure 2).
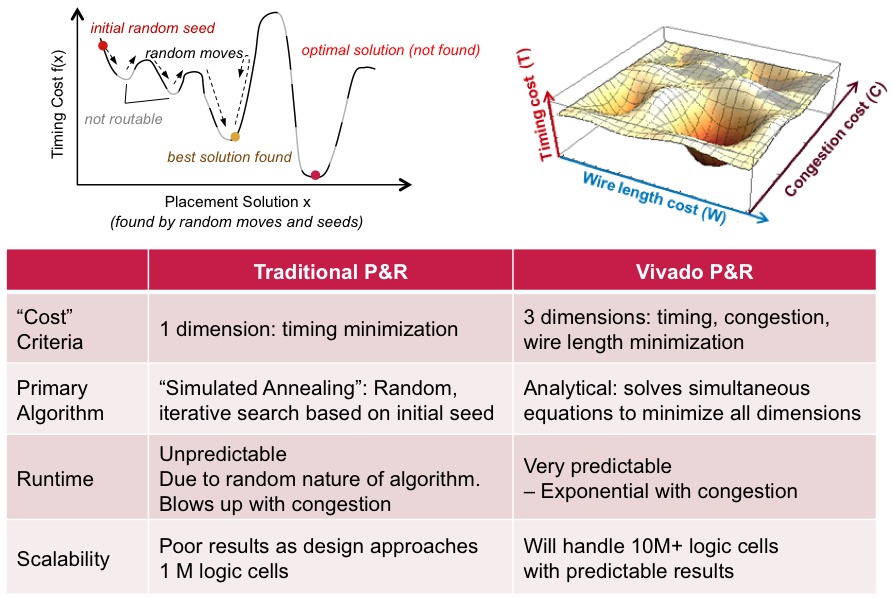
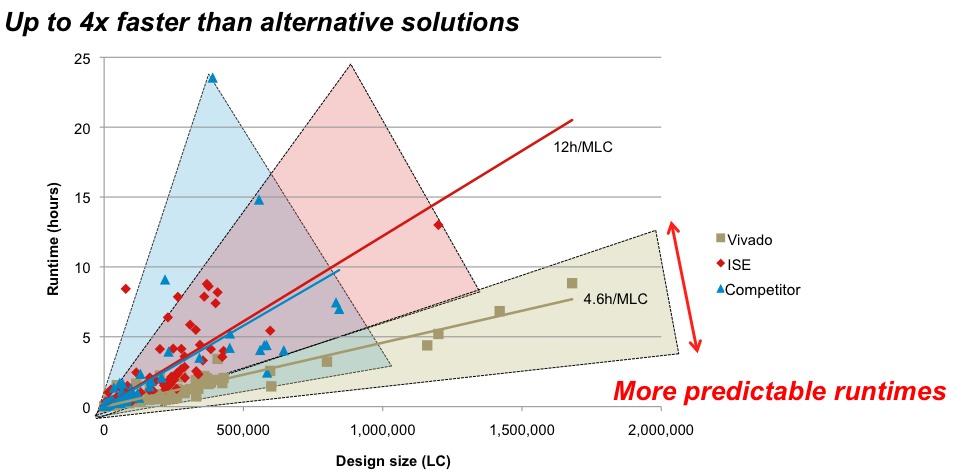
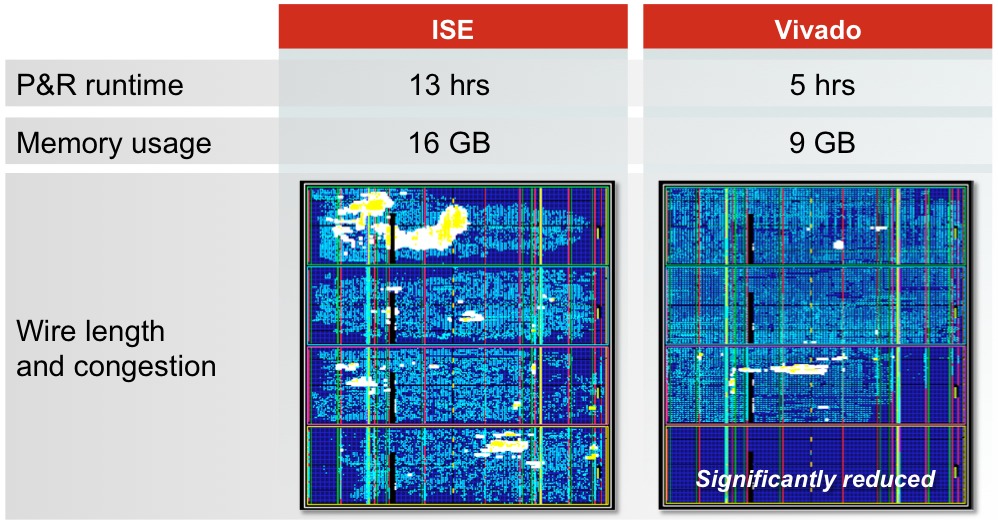
Figure 2. Vivado migrates beyond a timing-centric simulated annealing place-and-route algorithm to a more modern multi-dimensional scheme that comprehends not only timing requirements but also congestion and wire-length goals (upper graphic). The result is not only faster than its precursor and competitor, but also more predictable on a run-to-run basis, according to Xilinx (middle graphic). A 1.2 million logic cell design case study targeting Xilinx's V2000T Virtex-7 FPGA showcases Vivado's advantages over the P&R engine in ISE (bottom graphic).
Xilinx claims that the Vivado synthesis algorithm is up to 4x faster in "full" mode than that in ISE. Vivado's synthesis engine also offers a "quick" mode that delivers approximations of optimum design size and performance, at an up-to-15x compilation speed-up. Similarly, Xilinx forecasts that Vivado's simulator runs up to 3x faster than its ISE precursor, 100x faster if you leverage hardware co-simulation capabilities. The company offers Tcl-based scripting for the entire Vivado tool suite, along with a unified tool-to-tool data interchange format derived from the database used in Hier Design's PlanAhead, which Xilinx acquired in 2004. Vivado employs SDC (Synopsys' design constraints format) as its timing constraints language, a format that many other toolsets long ago standardized on. Other industry standardization steps embraced by Xilinx in Vivado include AMBA AXI4 (ARM's Advanced Microntroller Bus Architecture Advanced eXtensible Interface 4) for IP block interconnect, Accellera's IP-XACT metadata standard for IP packaging, and IEEE P1735 for IP security and rights management.
Xilinx offers Vivado in several different configurations with varying prices, ranges of device support and degrees of toolset integration (Figure 3). Particularly note the inclusion of HLS, a tool targeting the direct implementation C, C++, and SystemC specifications into FPGAs, within the sub-$5,000 Vivado System Edition. Xilinx obtained HLS via the acquisition of AutoESL and its AutoPilot product in January 2011. HLS had previously been an optional ISE toolset add-on that by itself had a list price of more than ten thousand dollars.
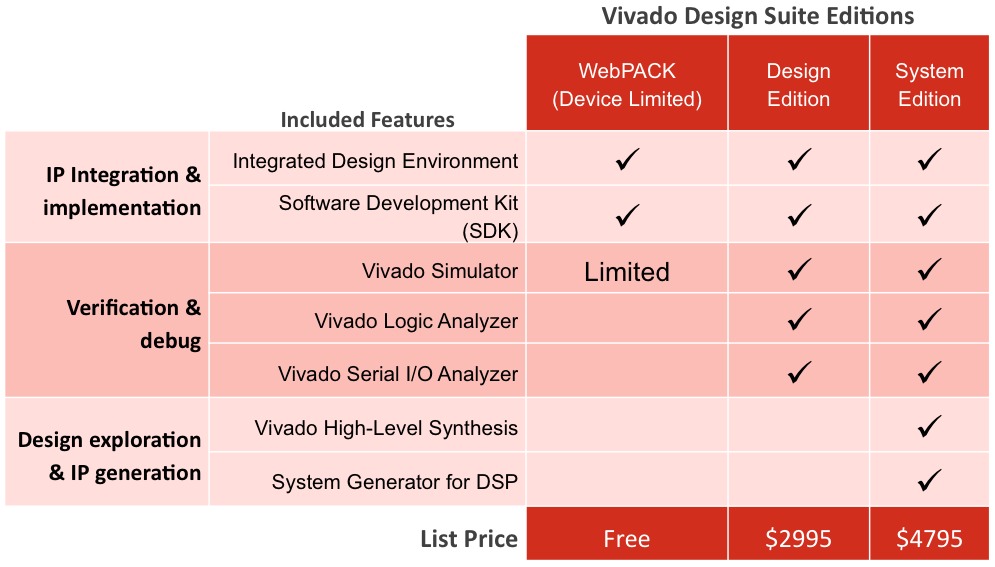
Figure 3. The Vivado toolset, in several variants (albeit simplified from the comparative diversity of available ISE options) has now exited both a year-long private beta process and a subsequent several-month "early access" cycle, and is available to all customers.
Considering that ISE dates from the early 1990s, the toolset has had an impressive run and likely ended up supporting device sizes and levels of complexity far beyond those initially envisioned by its developers. Hopefully, Vivado will have similar longevity; considering that Xilinx already ships FPGAs with 2 million logic cells, the 10-million logic cell threshold is likely only a few lithography shrinks away.
Add new comment