
This month NXP has unveiled more details on its new licensable core, the CoolFlux BSP, which targets low-power communications baseband processing. The core is based on the similarly named CoolFlux DSP, which was designed for use in low-power audio applications and introduced in 2004. Relative to the older core, NXP says that the CoolFlux BSP has been enhanced to increase its performance in baseband processing while retaining a small footprint and low power.
According to NXP, the CoolFlux BSP core will run at 290 MHz in a 65 nm process and consume about 65K gates; power consumption (for the core only) is about 20 mW at 1.2 volts and 290 MHz in a 65 nm process. The core is designed to be used as a co-processor or in standalone mode, and can also be used as part of a multi-core system.
The CoolFlux BSP uses a 24-bit data path, which is somewhat unusual for a baseband processor; most competitors (such as the Tensilica Xtensa LX, Ceva XC, and the Ceva TeakLite families) use either 16- or 32-bit data paths; those with 32-bit data paths often split their data paths to perform dual 16-bit operations. The CoolFlux BSP’s 24-bit width is a holdover from the CoolFlux DSP; audio-oriented processors often use 24-bit data paths as a compromise: 24-bit data eases implementation of high-fidelity audio algorithms relative to a 16-bit machine, and reduces area and power relative to a 32-bit design. As described below, the CoolFlux BSP can split its 24-bit data path into two 12-bit paths to increase computational throughput.
The CoolFlux BSP issues a single 32-bit instruction word per cycle, and NXP emphasizes that the 32-bit width enables an orthogonal instruction set and efficient C compiler. Unlike many DSPs and MCUs, CoolFlux BSP does not offer a separate compressed, 16-bit instruction set. Wide instruction words often lead to high program memory use, which in turn can increase chip size and power consumption. According to NXP, the BSP has several features to keep code size low: multiple operations can be encoded in a single instruction to reduce code size on tasks that are parallelizable, and for sequential code, the core supports an instruction mode that essentially allows two 16-bit instructions to be packed into a 32-bit instruction. NXP claims that for a USB software stack, its core has 6% better code density than an ARM7 (BDTI has not evaluated the memory use characteristics of the CoolFlux BSP core).
As shown in Figure 1, the CoolFlux BSP, like its predecessor, includes two 24x24-bit multiply-accumulate (MAC) units; two 24/56-bit ALUs and one 24-bit ALU; two 24-bit data memories and a 32-bit program memory; and two address generation units. The key difference is that the new core supports three modes of operation rather than just one: scalar (used in the CoolFlux DSP core), SIMD, and complex. The mode is determined based on the class of instruction used and a status bit.
![]()
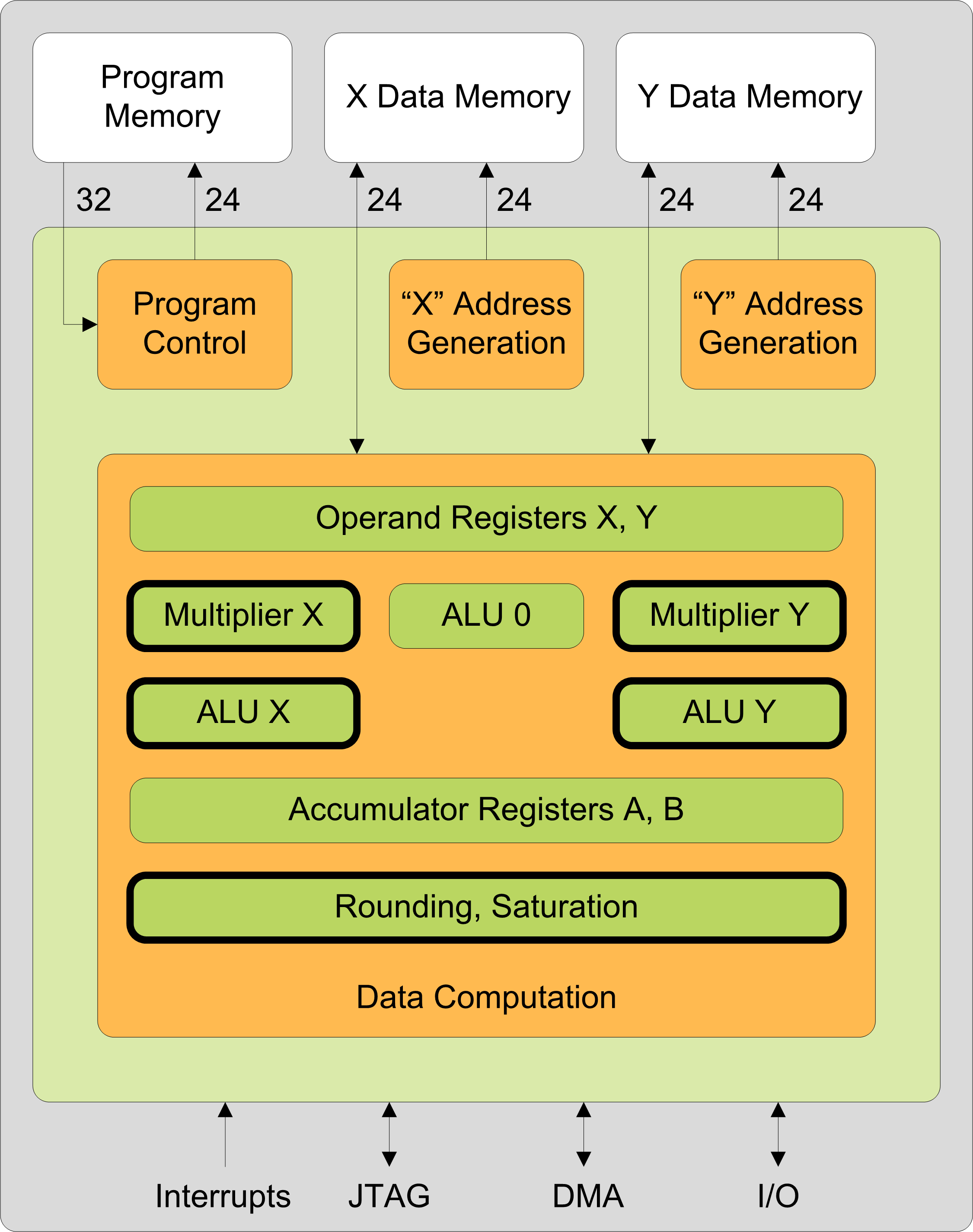
Figure 1. NXP CoolFlux BSP architecture. Figure courtesy of NXP.
In SIMD mode, each MAC unit (or ALU) is split such that it executes two 12-bit operations (the 56-bit ALUs can also perform dual 28-bit operations). In complex mode, the processor treats input data as a complex number with real and imaginary components, which can be 12 or 24 bits wide. The core can perform, for example, 12-bit complex multiplication (i.e., four real multiplications and two additions, as shown below) in two cycles, with single-cycle throughput:
(Ar x Bi) + (Ai x Br), (Ar x Br) – (Ai x Bi)
The core also explicitly supports complex addition and subtraction (Ai +/- Bi, Ar +/- Br), and can execute 24-bit complex calculations (with lower throughput). The BSP supports a range of specialized instructions for SIMD arithmetic, complex arithmetic, FFTs, Viterbi processing, and the CORDIC algorithm.
According to NXP, the new SIMD and complex math capabilities enable the core to calculate two taps per cycle for a 12-bit complex FIR filter, for example, or execute a 12-bit (with 28-bit intermediate results) radix-4 256-point complex FFT in 2480 cycles. (By way of comparison, the CoolFlux DSP core requires 8930 cycles for a 24-bit (with 56-bit intermediate results), radix-2 FFT.) Overall, the SIMD and complex modes provide a significant speedup across a range of algorithms, but because they are 12-bit operations, the speedup comes at the cost of precision and dynamic range.
Like with the CoolFlux DSP, NXP expects its customers to program the CoolFlux BSP in C. NXP has added C language extensions to support complex data types and SIMD data types, along with intrinsics for complex and SIMD functions. NXP is also developing a fairly extensive set of software components for the new core, including algorithms used for communication tasks (such as Viterbi decoding, OFDM, mapping/demapping) and basic DSP functions (such as real and complex FFTs, IIR and FIR filters, and quantizers). NXP previously developed a library of audio-oriented software components for the CoolFlux DSP; these components can be used on the new core but will need to be re-compiled since the instruction-set encoding is different.
The CoolFlux BSP will compete with licensable cores from Tensilica, VeriSilicon, and Ceva, among others. Benchmark results for several of the competitor cores are available at /Resources/BenchmarkResults/BDTIMark2000 (BDTI has not yet benchmarked the CoolFlux BSP.) According to NXP, the CoolFlux DSP core has been licensed by a number of (undisclosed) customers, both within NXP and outside NXP, and the BSP core will be used by a lead customer in a WiMax baseband applications.
The BSP has some unusual features, particularly its complex, 12-bit computational capabilities. Perhaps a key question is whether 12 bits is enough for many baseband operations. Based on its own analysis, NXP believes that it is—particularly because the core can use larger intermediate results to maintain precision. And when it isn’t, users can switch to the (slower) 24-bit mode. How well customers are able to make use of the core’s maximum throughput (using 12-bit data) will have a big effect on the performance they’re able to squeeze out of the core.
Add new comment