
The number of vendors offering massively parallel processors for digital signal processing is growing. As independent technology analysis company BDTI explained in its earlier article, there are a wide range of architectural approaches, each with unique pros and cons. Regardless of the approach taken, these chips are all highly complex, and they all face a similar challenge: making it easier for users to get their applications up and running. In this article BDTI will discuss some of the new development tools that massively parallel processor companies have developed to help their customers implement signal processing applications.
Augmented Design Flows
In a single-core chip, the process of implementing a signal-processing application typically involves the following steps:
- Designing the software architecture and choosing algorithms
- Implementing the software in a high-level language or assembly code (or often, a mixture of both, and possibly incorporating off-the-shelf software components)
- Testing and debugging the code
- If necessary, optimizing the code to improve performance or efficiency.
Figure 1 shows the typical application development process and tools used for a single-core chip.
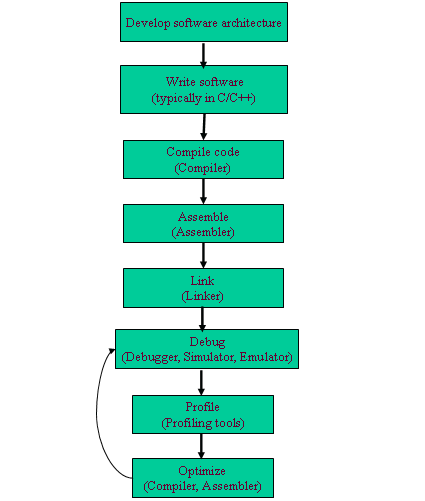
Figure 1. Typical software development tasks and associated tools for single-core chips. Optimization is typically an iterative process.
For many massively parallel processors, the application implementation process involves tasks similar to those shown in Figure 1, but these tasks tend to be more complicated because of the complexity of the target architecture. For example, one key difference between implementing an application on a single-core chip versus a massively parallel chip lies in the level of difficulty associated with developing an appropriate software architecture. SSoftware architecture encompasses a range of software design choices that affect how an application will be implemented and executed on the chip. For example, software architecture decisions include how the functionality of the application will be organized into software modules, how those modules will communicate which each other, and how the execution of the modules will be controlled and coordinated.
For a massively parallel chip, it’s crucial to develop an architecture (and algorithms) that is highly parallel and well-suited to the underlying chip. This software architecture will almost certainly be quite different from one that might be used for the same application on a single-core chip. As things currently stand, this is still mostly a manual process, and it remains a critical challenge for users of massively parallel chips.
Another difference between the single-core application development process described in Figure 1 and the process for developing an application on a massively parallel chip is that the latter typically requires an additional step—partitioning the application across an array of processing elements. As discussed in the next section, many vendors offer tools to help with this task.
Vendors of massively parallel chips that incorporate FPGA-like elements face an additional challenge: more engineers are familiar with the software development process than with the process of implementing an application on an FPGA. So although an FPGA is fundamentally quite different than a programmable processor, vendors of FPGA-based massively parallel chips often create development tools that look similar to those used on processors. Such tools give the programmer a way to access the compute power of FPGA-like chips without having to worry about concepts like hardware description languages or routing.
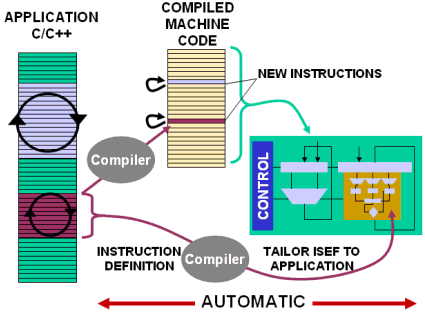
Stretch Inc., for example, offers massively parallel chips that combine a programmable processor core with reconfigurable FPGA-like compute fabric. In Stretch’s case, the design flow is very similar to that used for single-core chips, because the tools have been designed to largely hide the additional steps needed to configure and use the reconfigurable logic. Stretch offers a compiler that can take input C source code and generate custom instructions and associated hardware accelerators in the FPGA fabric (which Stretch refers to as the Instruction Set Extension Fabric, or ISEF). The programmer uses Stretch’s profiling tools to identify computationally demanding sections of the C code, and places those sections in a special file that is then used by the compiler to define application-specific instructions. These instructions both configure and execute in the FPGA fabric, and can be called from a C program. Figure 2 illustrates how multiple instructions in the source C code are mapped to a single custom instruction and used to configure the ISEF.
Add new comment