
Nearly everyone who works with embedded processors relies on benchmark results in one way or another. Executives use them to help make critical business and technical decisions. Engineers and managers use them to evaluate in-house processors or to help choose a processor for a new product. Marketers use them for competitive analysis and to add credibility to their marketing programs.
Good benchmarks, used properly, are an invaluable tool for all of these purposes. Unfortunately, there are many ways to create bad benchmarks. Relying on bad benchmarks can result in poor decisions, ineffective marketing, and in some cases, products that don’t work.
Digital signal processing (DSP) benchmarks—like DSP applications—have their own set of unique requirements. If you’re developing your own DSP benchmarks or using someone else’s DSP benchmark data, then you need to understand the key factors that determine a DSP benchmark’s credibility, relevance, and applicability.
Benchmark Complexity Trade-Offs
Benchmarks can be defined with varying levels of complexity; that is, they can be designed to represent a full application, or a single operation, or anything in between. If a benchmark is too simple, it won’t do a good job of representing real-world performance. Too complex, and it won’t be practical to implement—which means that few processors will have results available.
Benchmarks that are more complex provide accurate performance assessments, but only for the specific applications they represent. They usually can’t be used to predict performance across a broad spectrum of applications. Simple benchmarks are more broadly useful, but are less accurate. Benchmark designers must weigh the trade-offs and choose a complexity level that will provide meaningful results without becoming completely impractical to implement.
We’ve defined four levels of DSP benchmark complexity, as shown in Figure 1. The simplest type is based on basic operations, such as MACs or additions. These metrics are easy to measure, but are much too simple to provide reliable information about how a processor will perform in a real application. For example, although many signal processing applications make heavy use of MACs, many others do not. And even the most MAC-intensive application performs many other types of processing. Furthermore, a processor may not be able to reach its peak MAC rate because of limiting factors such as memory bandwidth, pipeline latencies, or algorithm feedback requirements. None of these performance issues are captured by operation-level benchmarks, making them nearly useless for evaluating a processor’s suitability for an application.
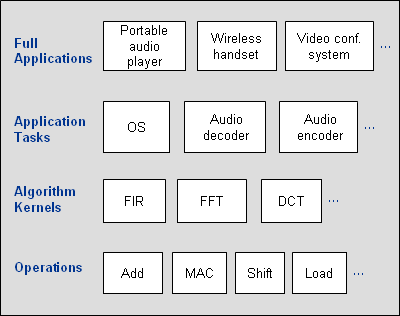
Figure 1. Levels of DSP benchmark complexity, from most complex (full applications) to least complex (operations).
At the other end of the complexity spectrum are full-application benchmarks, such as the complete functionality found in wireless handsets and portable audio players. Like operation-level benchmarks, full-application benchmarks have several significant drawbacks. Because of their complexity, they are unlikely to be implemented on many processors. This is particularly true if benchmark implementers will be optimizing key portions of the implementation (as is typically done in real-world signal processing applications). Most companies don’t have the resources to optimize application-level benchmarks on multiple processors. Thus, there are likely to be few results available to users—which can make it impossible to do meaningful competitive analyses. In addition, results for full-application benchmarks have very narrow utility. They reveal little about a processor’s performance in applications other than the one used for benchmarking—even if those applications are seemingly similar.
Between these extremes lie DSP algorithm kernel benchmarks (like FIRfilters and DCTs) and application task benchmarks (which model key signal processing tasks, and are often representative of an overall application workload). Collectively, these two types of benchmarks are, in BDTI’s view, a "sweet spot" for benchmarking. They’re complex enough to capture real-world performance characteristics, but not so complex that it takes years to implement them.
Benchmarks Should Be Tied to Applications
Whether the benchmark is an algorithm kernel or an application task,the benchmark workload must be closely tied to the application it represents. Benchmarks designed to measure processors’ performance in embedded signal processing applications should be different from benchmarks designed to measure processor performance on other types of embedded applications—because the applications themselves are different.
There are two distinct areas in which benchmarks must be representative of the applications for which they are used. The first is most obvious—regardless of the benchmark’s complexity level, it must perform the kinds of work that a processor will be expected to handle in real-world applications.
The second area is more subtle, and it’s one where many signalprocessing benchmarks go astray. Not only must the benchmark performrelevant work, it must be implemented in a way that is similar to how the corresponding real-world applications are implemented.
Implementation Approaches
There are many approaches for implementing processor benchmarks. Forexample, benchmarks can be implemented using unmodified high-level reference code or can be optimized by hand at various levels. Benchmarks can be optimized to achieve maximum speed, to achieve minimum cost, or to achieve some other application-specific goal. When you’re using benchmark results, it is critical to understand the implementation approach and assess whether it is relevant to your application.
Embedded signal processing software, for example, is typically hand-optimized—at least the performance-critical sections (which are often the sections that benchmarks attempt to model). This is because these applications often have stringent constraints on speed, energy consumption, memory efficiency, and/or cost, and unmodified compiled code is typically not efficient enough to meet these constraints. Therefore, a benchmark that is implemented using unmodified reference C or C++ code is unlikely to yield results that are representative of how the processor will perform when used in a real application, running optimized software.
The implementation approach should be defined based on what’s commonly used in relevant end-products. For example, algorithm kernel benchmarks should be carefully hand-optimized, because this is howsignal processing kernels are most often implemented in products. Application task benchmarks, on the other hand, should be implemented using some combination of high- and low-level coding and optimization, the specific ratio of which is guided by trade-offs in memory, speed, and programming effort. The difference here is that applicationtask benchmarks are similar to full applications, which are typically not completely hand-optimized; performance-critical sections are well optimized, but other sections may be left to the compiler.
Allowable Optimizations
Once the benchmark workload and general implementation approach is defined, careful attention must be given to the types of optimizations that are permitted. One approach is to allow every possible optimization. This is unlikely to yield realistic benchmark results because it tends to encourage implementations that ignore performance on one metric (such as memory efficiency) in exchange for optimal performance on another metric (such as speed). It’s an approach that’s rarely taken in real applications, which tend to have constraints on multiple metrics.
For the benchmarks to be relevant and useful, benchmark implementers must make reasonable trade-offs between all of the relevant metrics. These may include speed, memory use, energy efficiency, or cost efficiency. Of course, it’s essential that the optimization strategy be applied consistently across all processors if you want to compare their results.
Evaluating Benchmark Credibility
Assuming that a benchmark has been thoughtfully designed and fairly implemented, it is tempting to assume that the benchmark results are trustworthy. Unfortunately, even when the benchmarks are sound, there are a number of ways in which benchmark results can be presented misleadingly.
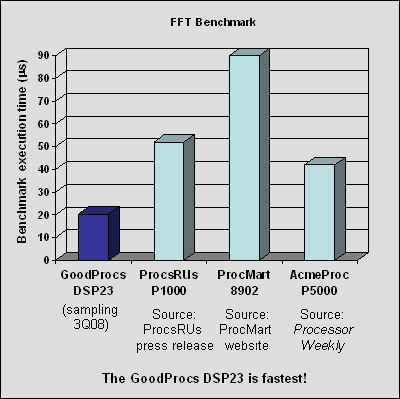
Figure 2. Example of processor vendor (GoodProcs) benchmark presentation.
Consider the sample presentation of benchmark results shown in Figure 2.
At first glance, the benchmark results look reasonable—but there are several red flags that would cause us to ask further questions. These include the following:
- Are the results really comparable? The benchmark results shown here are from several different sources, which usually means that they aren’t apples-to-apples numbers. It’s common practice for processor vendors to implement their own benchmarks and compare their results to benchmark results published by other vendors or by third parties. While vendors’ benchmarks can be useful and informative, they are often designed to highlight the specific strengths of one particular processor, not to make fair and accurate comparisons across many processors. More generally, benchmark results from one vendor may not be comparable to results from other vendors, even if the algorithm is apparently the same. For example, some vendors include descrambling in their FFT benchmarks, others don’t—and details such as these are rarely disclosed. And implementation strategies (such as optimization approaches) are unlikely to be consistent.
- Does it make sense to compare a processor (the GoodProcs processor) that won’t be available until late 2008 with processors that are available today? Projections can be useful, but should be evaluated with the knowledge that the chip may not actually reach the target performance in the time period projected—and even if it does, the competitors’ products may have improved in the interim. In addition, processors fabricated in silicon often behave differently than predicted by initial simulations. For example, a processor may require more instruction cycles to execute a given task than expected. If benchmark results are based on simulations for a processor that has never been fabricated, then it’s a good idea to regard these results as rough estimates.
- The chart shows only one benchmark. Is this benchmark really the one benchmark that matters to the target applications, or was it chosen because it shows the GoodProcs product to best advantage? Is this a common FFT variant, or one that’s rarely used in real applications?
These are just a few of the kinds of problems we’ve seen in vendors’ product presentations (For additional problems to look for, see Jeff Bier’s "Impulse Response" columns on benchmark scams.) To avoid being misled, it’s essential to view benchmarks with a critical, informed eye.
Choose Your Benchmarks Wisely
For DSP benchmarks to be accurate and credible, they need to be well designed, consistently implemented, and thoughtfully used. If they fail in any of these areas the repercussions can be disastrous. Whether you’re using benchmarks to help make decisions or to sell your product, your outcome will depend on the quality of the benchmarks you’re using, and on how well you use them. Make sure that the benchmarks are worthy of your confidence.
Add new comment