
In February CEVA announced a new family of high-performance licensable DSP cores, the CEVA-XC family. CEVA-XC cores target 4G cellular applications, including LTE and WiMax, and are intended for use not just in handsets (as with previous CEVA cores) but also in infrastructure hardware. The CEVA-XC is an offshoot of the CEVA-X architecture (the “C” stands for communications), but the new core family is much more powerful than its predecessors. The highest-performance version supports, for example, up to 64 parallel multiply-accumulate (MAC) computations per cycle, compared to four for the CEVA-X1641. CEVA has not announced specific clock speeds, but says that it expects CEVA-XC to easily reach 500 MHz in a 65 nm process with a fully synthesizable design. Silicon area has not been disclosed.
As shown in Figure 1, the core includes a general computation unit for general DSP and control operations, and either one, two, or four “vector communication units”. Each vector unit includes a 256-bit SIMD engine that includes16-bit MAC, arithmetic, and logic units. According to CEVA, the vector units can operate in two modes: either they all execute the same instruction as an ultra-wide SIMD engine, or each unit can execute its own instruction using optional instruction set extensions (described below).
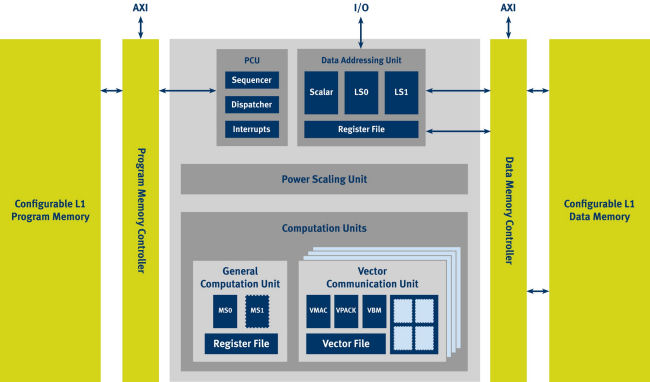
Figure 1. Block diagram for CEVA-XC. (Figure courtesy of CEVA.)
The CEVA-XC family is scalable and configurable, meaning that a chip designer using the core can specify the number of vector units to be included (one, two, or four) and whether to include any of the optional instruction sets, which offer support for transmitters, floating-point operations, and CORDIC (an algorithm used in OFDM receivers). The core’s scalability and configurability enable licensees to make area/performance trade-offs, and facilitate the ability to tackle both handsets and infrastructure equipment. In BDTI’s view, scalability is becoming increasingly important for processor architectures, as it allows a single architecture (and associated tool chain) to address a wide range of applications. It’s particularly useful in wireless communications products given the multitude of forms of communications transceivers (e.g., low-speed handset, high-speed handset, femtocell, picocell, macrocell base station).
CEVA estimates that the highest-performance version of the core will offer about 8-10x the “DSP efficiency” of a 1.2 GHz ‘C64x+ ¾ but this estimate is based on cycle counts rather than speed, which is misleading since it doesn’t factor in the fact that the ‘C64x+ operates at more than twice the estimated clock rate of the CEVA-XC. As another point of comparison, Silicon Hive (a vendor of licensable, massively parallel processors) offers a core that computes 25.6 GMACs/second, which is lower than the CEVA-XC’s projected rate of 32 GMACs/second.
We should note here that both CEVA’s ‘C64x+ performance estimate and our comparison to the Silicon Hive core are based on MAC throughput, which, as we’ve written about many times before, is often not a reliable performance metric. Still, it’s clear that the CEVA-XC is a very high-performance core family.
Of course, speed isn’t everything, and CEVA is also emphasizing the core’s power efficiency and programmability. The CEVA-XC includes a power scaling unit that supports speed and voltage scaling, along with a range of low-power modes that are designed to reduce leakage power in addition to reducing dynamic power. CEVA also touts the core’s compiler, which is based on the compiler developed for the earlier CEVA-X cores. It’s typically difficult for compilers to make good use of SIMD capabilities, so the CEVA-XC vector units may pose a bit of a challenge. CEVA says that they can be leveraged via intrinsics or using CEVA’s optimized C-callable library functions.
Add new comment