
Toward the end of an article published in the February 2013 edition of InsideDSP, analyzing BDTI's published benchmark results of Qualcomm's QDSP6 (aka "Hexagon") v4 DSP core, you'll find the following prescient quote:
Qualcomm is, of course, not done innovating with Hexagon. The June 2012 InsideDSP article uncovered evidence of an upcoming QDSP6 v5, which the company officially unveiled at the Consumer Electronics Show last month within its newest Snapdragon 800 Series SoCs. QDSP V5 expands on the v4 foundation in several notable areas:
- Byte-vector operations, a particularly appealing enhancement in embedded vision and imaging applications, which generally require less data precision than audio (for example) and benefit from more operations per second, and
- Floating-point support, which helps with high dynamic range audio and location (GPS, etc.) processing applications, among others, and which also simplifies the initial porting of floating point-based software that originates with PC-developed code.
Stay tuned for more on QDSP6 v5 in a future edition of InsideDSP, commensurate with BDTI's publication of benchmarking results on the new architecture generation.
That time is now. QDSP6 v5 BDTIsimMARK2000 scores, both fixed (PDF) and (for the first time with QDSP6) floating-point (PDF), are now available on the BDTI website. From a fixed-point processing standpoint, the v4 and v5 cores are largely identical, save for the fact that the newer variant runs at a slightly higher maximum specified clock rate (267 MHz versus 233 MHz) and supports the previously mentioned byte-vector operations.
The initial QDSP6 v5 instantiation is specified at 600 MHz (200 MHz per thread) in Snapdragon 800-series SoCs, as Qualcomm's product page notes. Therefore, here's an updated version of the "QDSP6 version key attributes" table found in the earlier February 2013 article, with the initial v5 instantiation included (Table 1):
|
Version |
Process lithography |
Peak number of simultaneous threads |
Per-thread clock speed (initial instantiation) |
Cumulative per-core clock speed (initial instantiation) |
|
QDSP6 v2 |
65 nm |
6 |
100 MHz |
600 MHz |
|
QDSP6 v3 |
45 nm |
6 |
67 MHz |
400 MHz |
|
QDSP6 v4 |
28 nm |
3 |
167 MHz |
500 MHz |
|
QDSP6 v5 |
28 nm |
3 |
200 MHz |
600 MHz |
Table 1. QDSP6 version key attributes
As a reminder, here's a conceptual description of the QDSP6 multi-threaded architecture, again from the February 2013 article (the v4 example applies equally to v5):
Hexagon's multithreaded nature is a key differentiator from competitive DSP architectures developed by companies like CEVA, Tensilica and other suppliers. Each QDSP6 thread is fully supported in hardware, with a distinct register file, and execution of the threads operates in a round-robin fashion, on a cycle-by-cycle basis. For example, here's the best-case execution sequence for the three-thread QDSP6 v4 core:
- First clock (cycle): First instruction for first thread
- Second clock: First instruction for second thread
- Third clock: First instruction for third thread
- Fourth clock: Second instruction for first thread
- Fifth clock: Second instruction for second thread
- Sixth clock: Second instruction for third thread
- Etc.
And here's an update to the previous article's fixed-point benchmark score summary table, adding the QDSP6 v5 results (Table 2):
|
Processor Family |
Clock rate (min-max) |
BDTIsimMark2000TM (min-max) |
|
QDSP6 v2 (one thread) |
67-100 MHz (per thread) |
1040–1550 (one thread) |
|
QDSP6 v2 (six threads) |
67-100 MHz (per thread) |
6240–9300 (projected best case for 6 threads) |
|
QDSP6 v4 (one thread) |
100–233 MHz (per thread) |
1810–4220 (one thread) |
|
QDSP6 v4 (three threads) |
100–233 MHz (per thread) |
5430–12660 (projected best case for 3 threads) |
|
QDSP6 v5 (one thread) |
100–267 MHz (per thread) |
1810–4840 (one thread) |
|
QDSP6 v5 (three threads) |
100–267 MHz (per thread) |
5430–14520 (projected best case for 3 threads) |
Table 2. BDTIsimMark2000TM Speed Scores for Fixed-Point Packaged Processors (Higher is Better)
Next, let's look at floating-point benchmarks. Since floating-point support is new to QDSP6 v5, comparative v2 and v4 scores are not available in this case (Table 3):
|
Processor Family |
Clock rate (min-max) |
BDTIsimMark2000TM (min-max) |
|
QDSP6 v5 (one thread) |
100–267 MHz (per thread) |
900–2400 (one thread) |
|
QDSP6 v5 (three threads) |
100–267 MHz (per thread) |
2700–7200 (projected best case for 3 threads) |
Table 3. BDTIsimMark2000TM Speed Scores for Floating-Point Packaged Processors (Higher is Better)
Compare the QDSP6 v5 floating-point results to those of other DSP architectures in the full report (PDF), and you'll likely conclude that QDSP6 compares favorably to competitive alternatives, particularly considering its low power consumption attributes, and especially when software is able to efficiently utilize the processing resources available in all three threads.
Finally, let's look at the graphic shown in BDTI's earlier June 2012 QDSP6 architecture coverage, taken from a plenary talk at the January 2012 IEEE International Conference on Emerging Signal Processing Applications (IEEE-ESPA), by Dr. Raj Talluri, Qualcomm's Vice President of Product Management. This figure provided InsideDSP with the first public disclosure of QDSP6 v5 on Qualcomm's roadmap (Figure 1).
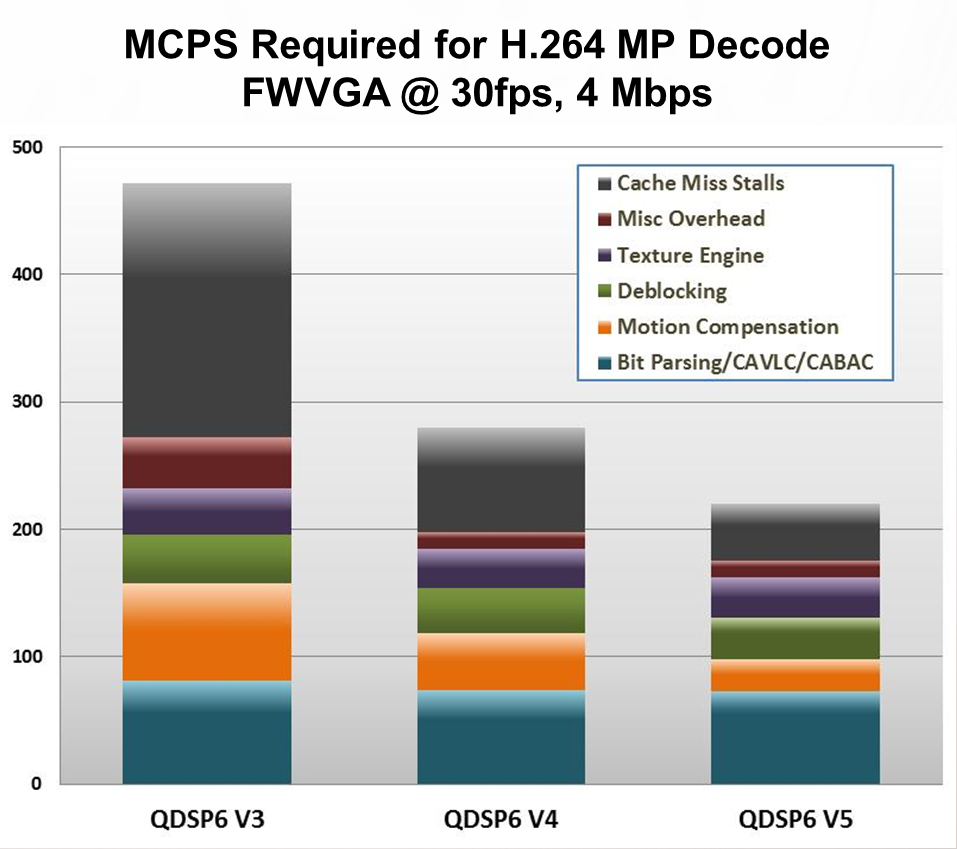
Figure 1. Version-to-version instruction set, cache and other enhancements make successive QDSP6 generations increasingly efficient "engines," as measured in millions of cycles per second, for decoding H.264 video bitstreams, according to Qualcomm (CAVLC = content-adaptive variable-length coding, CABAC = context-adaptive binary arithmetic coding)
Note that the two biggest areas of improvement (in terms of MCPS reductions) in the QDSP6 v4-to-v5 transition were regarding cache miss stalls and motion compensation. Qualcomm has presumably made data cache prefetch architectural enhancements in QDSP6 v5 that translate to an improvement in cache miss stalls. And QDSP6 v5's added support for byte-vector operations is a possible explanation for the motion compensation performance boost.
Although QDSP6 v5 is currently found only in Qualcomm's highest-end Snapdragon 800 series SoCs, its presence will likely expand over time to also encompass mid-range and (eventually) low-end application processors as well, as has been the case with previous generations of the core. QDSP6 v5's floating-point benchmark scores are roughly half of its fixed-point results, but this disparity isn't atypical for DSPs. And, as previously mentioned, its floating-point support is beneficial for—among others—high dynamic range audio and location processing applications, as well as for simplifying initial porting of floating-point software that originates with PC-developed code. I wonder what Qualcomm has in store for us with QDSP6 v7...or will it be QDSP7?
Add new comment