
At last month's MWC (Mobile World Congress), CEVA unveiled the XC12, its latest DSP core for communication infrastructure applications. A significant feature set upgrade to the XC4500 DSP core precursor, the XC12 is tailored for the bandwidth, latency and user count demands of next-generation "5G" cellular-supportive infrastructure equipment, ranging from remote digital front-end radio heads through multi-mode baseband processing in various-sized base stations, and all the way to wireless backhaul equipment. And nearer term, the XC12 also supports the ever-increasing implementation complexity of the latest variants of today's "4G" LTE, along with various advanced 802.11 Wi-Fi flavors.
"5G" was the primary topic of conversation at MWC; draft specifications had just been released, and infrastructure and mobile device manufacturers alike naturally clamor for any opportunity to sell cellular service operators and operators new and upgraded hardware, software and services. A perusal of those draft specifications reveals some daunting requirements; massively MIMO antenna array configurations, for example, along with 3D beam-forming to any particular user, not to mention the thousands of users expected to be supported by any particular 5G network node, and the 8x latency reduction target for 5G versus today's LTE. A range of broadcast frequency bands from 400 MHz to millimeter wave-based 80 GHz will require support in a full 5G implementation (reduced-functionality technologies such as 5G NR (New Radio) and Verizon's 5GTF fixed access approach for wired broadband replacement therefore intend to act as interim steps), along with 256- and 1024-QAM demodulation.
More immediate volume opportunities for the XC12 also beckon. Back in October 2013, when the XC4500 was unveiled, the higher-bandwidth "Advanced" tier of 4G LTE was still on the drawing board; widespread implementation in the United States, for example, didn't begin until last August. Similarly, dual-band 802.11n was the latest-and-greatest Wi-Fi technology available in the market at the time; the successor 802.11ac specification was still being finalized and standardized. Fast-forward three-plus years, and cellular carriers are now planning rollouts of LTE Advanced Pro, capable of Gbit download speeds in optimum real-life conditions. The U.S. FCC also recently ratified the LTE-U specification, which allows for LTE operation in the 5 GHz unlicensed frequency band also currently inhabited by Wi-Fi. And speaking of Wi-Fi, 802.11ac routers are now commonly selling for less than $100 (with entry-level versions at $10!), and short-range 60 GHz 802.11ad (formerly known as "WiGig"), rated for theoretical peak transfer speeds of up to 6.75 Gbit/sec, is also now entering the market.
Note, too, that a residential femtocell (for example) may be chartered with simultaneously supporting multiple of these wireless topologies, across multiple users, in a multi-RAT (radio access technology) approach. So regardless of the rollout and ramp schedule for 5G, according to Emmanuel Gresset, CEVA's Business Development Director for Wireless and Wireline Communications, existing technology evolutions and new technology revolutions both beg for a DSP upgrade to today's XC4500. And according to Gresset, the X12 delivers on these aspirations, beginning with the fact that it is forecasted to run at up to 1.8 GHz on a 10 nm process foundation, translating to 920 GOPs of peak performance, an up-to-8x boost compared to the XC4500 (Figure 1).
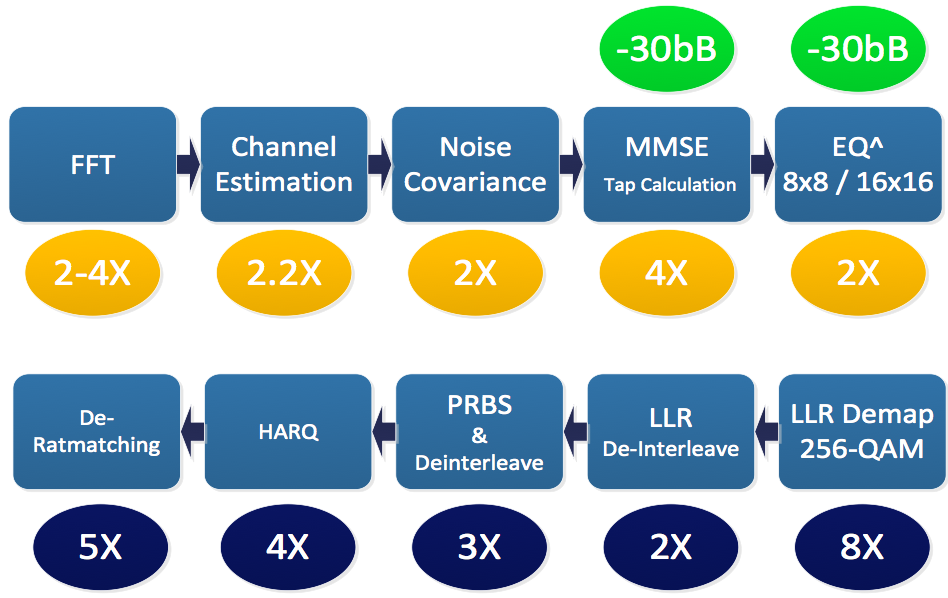
Figure 1. The combination of higher clock speeds and both evolutionary and revolutionary instruction set additions and other architecture advancements enable the XC12 to deliver notable performance and other improvements versus the XC4500, according to CEVA.
As with the wireless technologies it's chartered with supporting, the XC12 architecture is a combination of evolutionary and revolutionary advancements versus the XC4500 predecessor (Figure 2). The vector processing unit design has its origins in that in the XC4500, for example, although there are now twice as many of them (four versus two), for cumulative 128-bit single-cycle MAC (multiply-accumulate) capabilities. Numerous additional dedicated instructions (and associated hardware function blocks) have also been added, according to Gresset, to support operations required by 5G and other advanced communications standards.
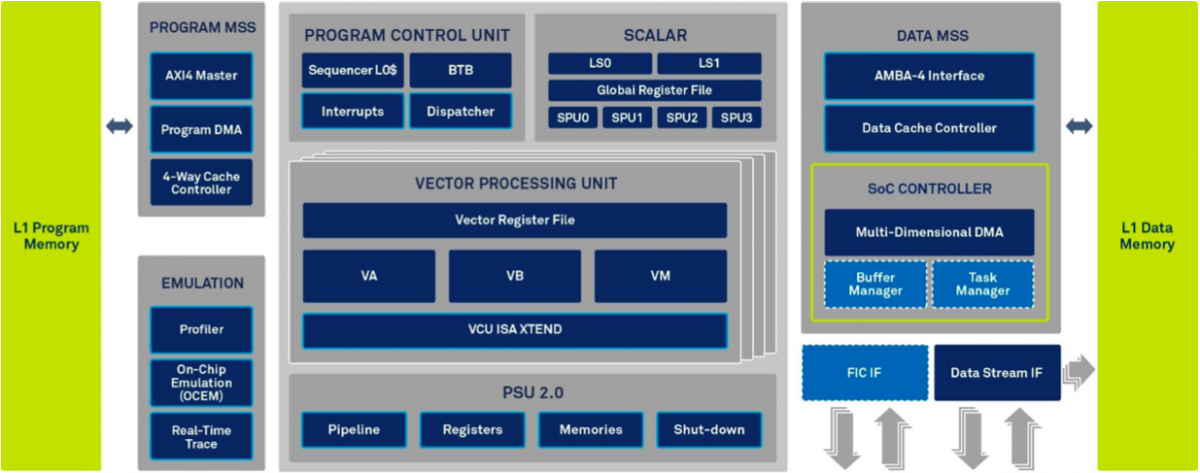
Figure 2. The XC12's vector processing units are descendents of those in the XC4500, albeit being more numerous and otherwise evolved; the new scalar units signify a more revolutionary advancement.
The XC12's scalar processing capabilities, conversely, mark a significant upgrade to those in the XC4500, and are architecturally reminiscent of those found in other newer CEVA-X Framework-based cores like the X1, X2, and X4 family, along with the XM6 vision processor. In this particular case, they come in the form of an eight-way VLIW implementation with a 14-stage pipeline. Each of the four scalar processing units, as with the CEVA X4, includes two 16x16 bit MACs, which can also be configured as a single 32x32 bit MAC. And, as with other CEVA-X Framework-based cores, Gresset touts the scalar units' expanded control code instruction set and other improvements: zero-latency capabilities for optimal performance on serial code, along with dynamic branch prediction support, as well as their support for fast context switches, supervisor and user modes, and semaphores for robust real-time operating system compatibilities.
With respect to the new core's floating-point facilities, each vector unit includes support for a focused set of both single-precision and half-precision floating-point arithmetic operations; the combination of high-precision fixed and floating-point arithmetic allows for up to 256x256 matrix processing (implementing massive MIMO, for example). Each scalar unit also optionally supports an IEEE-compliant single-precision floating-point unit, as has also been the case with prior CEVA cores. Gresset explained, however, that while a full IEEE-compliant FPU may be necessary in a general-purpose PC, for example, the FPU's need to support a full set of exception states (the root cause of the FDIV bug in the Intel Pentium CPU, as some of you may recall) results in high silicon area utilization and power consumption. Many embedded SoC licensees therefore dispense with including the scalar FPU in their designs, relying instead on the vector units' more optimized albeit CEVA-proprietary floating point capabilities.
Gresset believes that the bulk of production SoC activity incorporating the XC12 will be at 10 nm or 7 nm process lithographies, with a smaller percentage at 14 nm. The core is now available for licensing, and initial licensees now underway with designs may prototype their SoCs on the 16 nm process node.
Add new comment