
HPC (high-performance computing) servers, which have notably embraced the GPGPU (general-purpose computing on graphics processing units) concept in recent years, are increasingly being employed for computer vision and other deep learning-based applications. Beginning in late 2014, NVIDIA supplemented its general-purpose CUDA toolset for GPU-accelerated heterogeneous computing with its proprietary CuDNN software library, which codifies the basic mathematical and data operations at the core of deep learning training. Similarly, AMD has now supplemented its ROCm heterogenous computing toolset, covered in last month's InsideDSP, with its upcoming open-source MIOpen deep learning algorithm library optimized for AMD GPUs (Figure 1).
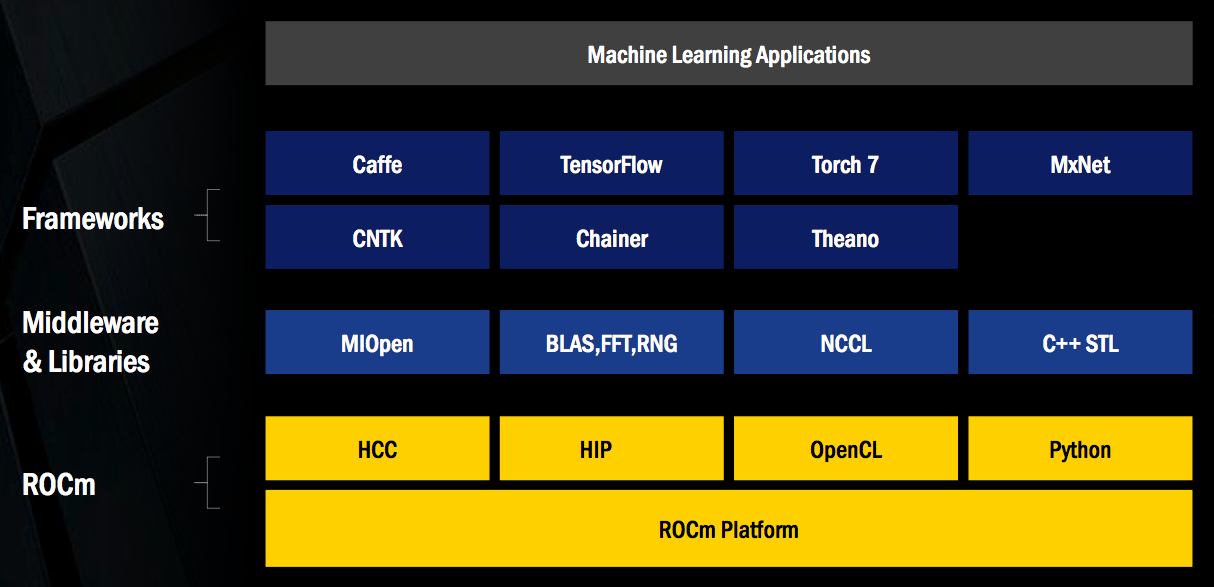
Figure 1. AMD is supplementing its recently announced ROCm GPGPU toolset with a deep learning-optimized and open source software library, MIOpen.
GPU usage in deep learning encompasses both initial model training and subsequent inference, when a neural network analyzes new data it's presented with based on this previous training. MIOpen strives to encompass both stages of the process, including GPU-tuned implementations of standard routines such as convolution, pooling, activation functions, normalization and tensor format. GEMM (general matrix-to-matrix multiplication)-based convolutions, for example, are a core operation in both deep learning training and inference and across multiple major deep learning frameworks, reflected in their notable presence in Baidu's DeepBench deep learning benchmark suite. And according to Gregory Stoner, AMD's Senior Director for Radeon Open Compute, the GPU-tailored GEMM convolutions found the MIOpen library run nearly three times faster than un-optimized algorithm alternatives would on the same GPU (Figure 2).
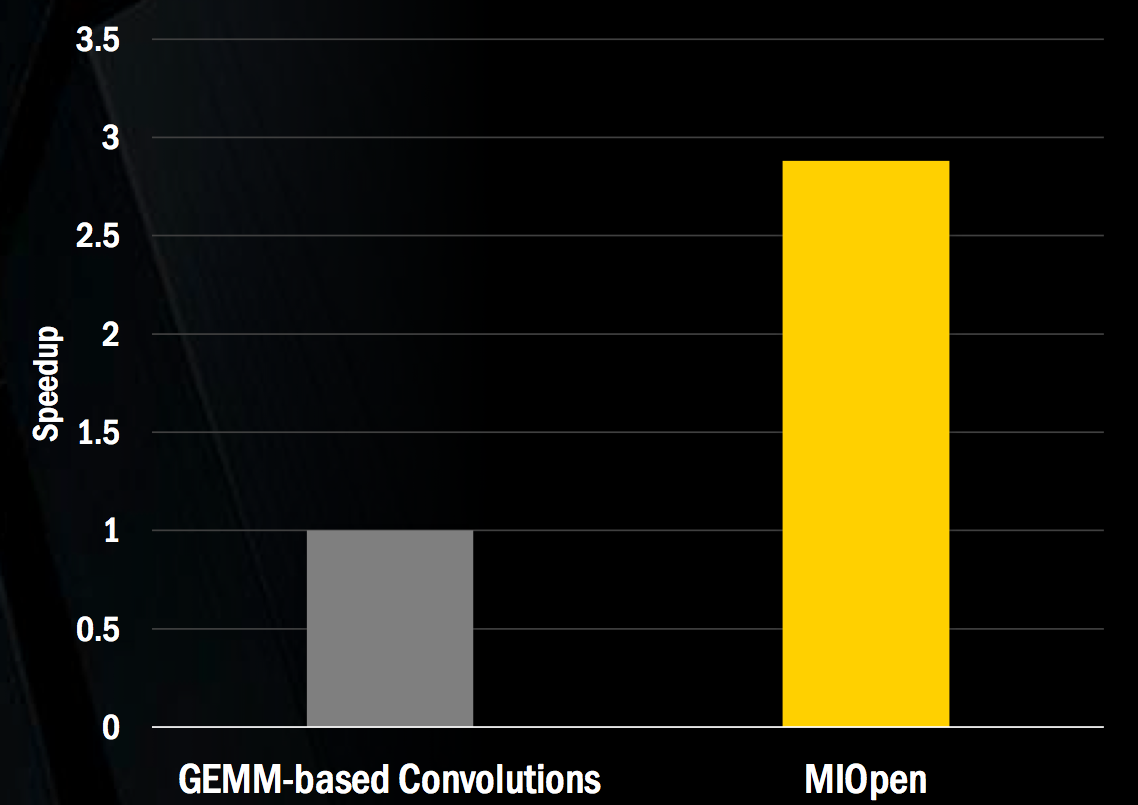
Figure 2. GEMM (general matrix-to-matrix multiplication)-based convolutions, a core function found in a variety of deep learning operations, are notably accelerated in their MIOpen library form versus generic alternatives, according to AMD.
AMD also gave a public preview of three new Instinct-branded add-in cards for deep learning acceleration (Figure 3). They're "headless," i.e. absent any video outputs as would be found in a conventional graphics card, since such a feature would be unnecessary in the target applications. Stoner allowed in a recent briefing that there's a high degree of ASIC commonality between the processors found in these boards and conventional GPUs, although the exposed instruction mix is different, analogous to the differentiation between professional- and consumer-targeted graphics chips and boards. Hardware-level optimizations in these deep learning product cases also include application-customized testing (the boards are manufactured by AMD itself, not a partner) and passive cooling, along with application-tailored memory types and array arrangements and sizes.

Figure 3. AMD's upcoming "headless" add-in board hardware family is feature-tailored for deep learning training and inference tasks.
The Radeon Instinct MI6 accelerator, based on the Polaris GPU architecture unveiled a year ago, is targeted at deep learning inference acceleration, with 5.7 TFLOPS of peak 16- and 32-bit floating-point performance, less than 150 watts of peak board power consumption and 16 Gbytes of GDDR5 SDRAM. Its sibling, the Radeon Instinct MI8 derived from the mid-2015 Fiji GPU and also targeted at inference, includes one-quarter of the memory (4 GBytes) albeit implemented in a higher-bandwidth stacked (HBM) fashion, and delivers 8.2 TFLOPS of peak FP16 and FP32 speed while consuming less than 175 watts of peak power.
At the performance pinnacle will be the Radeon Instinct MI25 training accelerator, which will leverage AMD's next-generation Vega GPU architecture; its target specifications include 25 TFLOPs of peak FP16 performance (via Vega's newly added support for packed math operations), 12.5 TFLOPs of peak FP32 performance, and less than 300 watts of peak power consumption. Other specifications, including memory size and type, are not yet public. All three boards will begin shipping at various points in the first half of this year; pricing has not yet been announced. The MIOpen deep learning library is currently in development and private beta testing; it will be released later this quarter.
NVIDIA has a notable lead in the HPC (generally) and deep learning (specific) spaces, and the company shows no signs of slowing down. With that said, AMD's belated presence is welcomed; the resultant competition will benefit not only both companies but also their common customers.
Add new comment