
Alan Kamas contributed to this article.
As processors have steadily become faster and less expensive, systems with signal processing algorithms have increasingly been implemented as software running on a processor. One of the first steps in the software development process is choosing the development language. Not too long ago, the choice of language was simple: only assembly language was efficient enough to meet the demands of most signal processing applications. Now that processors are faster, memories are larger, and compilers are better, there are higher level language choices. This article looks at the advantages and trade-offs of languages for signal processing software development—starting at the bottom and moving up from there.
Assembly Code: Next to the Machine
Hand optimized assembly code is still the most reliable way to get the maximum performance from a processor. This is an important consideration because demanding signal processing algorithms can tax even the fastest processors. The efficiency provided by assembly code might also be required for systems that use a slower processor to meet tight cost or power budgets. In order to realize the potential performance advantages of programming in assembly, the programmer must have an intimate knowledge of the internals of the processor. For example, the programmer must understand the details of the registers, specialized instructions, pipeline stages, memory accesses, and interrupts. Learning these details can be a slow, painful process. In addition to the long learning curve, it takes more time to code and debug in assembly. Because of these difficulties, a design may be prototyped or simulated in a higher level language first before it is rewritten in assembly for implementation on the embedded processor.
Another challenge with assembly is that it can be very difficult to read someone else’s code—or even to read one’s own code. This makes assembly code more difficult to maintain, modify, and upgrade. In a world of multiple and “evolving” standards, code updates can be a serious issue. Finally, the fact that assembly language is so close to the machine generally makes the code non-portable. If a different processor is chosen later, then the code will likely have to be rewritten. Figure 1 illustrates how assembly language can vary dramatically from one processor to the next.

Due to these serious drawbacks, assembly language is typically only used when necessary. The most critical functions may be coded in assembly while the rest of the system is written in a higher level language such as C. Recognizing this, some chip vendors and software vendors provide libraries of common functions written in hand coded assembly language that may be called from within the user’s C code for better performance. For more on function libraries, see “Software Building Blocks for Signal Processing Applications”.
C: The Common Choice
Compiled code may not run as efficiently as expertly crafted assembly code, but compiled C code is often efficient enough. Some general-purpose processors have had good compilers available for many years, and the compilers for many DSPs have improved in the last few years. Similarly, general-purpose processors have long been designed to be good compiler targets, and DSPs have recently evolved to better support high level languages and to make the compiler’s job easier. For more on compilers, see “Tools Make the Difference”. Often, code efficiency is not the most important factor when choosing a language. Since it is easier to program in a higher level language, development can be much faster than with assembly. But the real gain is in the debugging and maintenance effort. Errors found by a compiler may be easily fixed on the spot. Similar errors in assembly code may not be found until the code is run and debugging begins. Maintenance is easier too, which leads to faster turnaround times for fixes and upgrades. But these advantages are offered by all high-level languages. Why choose C?
There are many good reasons to use the C language. It has support for all of the basic control structures and native support for low-level bit manipulation. Because of this flexibility, all of the software in a system, from the signal processing to the control system to the user interface, can be developed together in C. But perhaps the greatest advantage of C is its popularity. The C language is widely used across a broad range of programming fields. Since almost every processor has at least one C compiler available, code written in C is more likely to be portable and reused. Finally, because C is widely known, the learning curve for bringing new programmers into a project is eased.
However, the C language was not designed with signal processing in mind. Some of its features are ill-suited for the needs of signal processing applications. The C language has no native support for fixed point fractional variables and it is not possible to set the bit width of integers with certainty. A “long int” may be 64 bits, 32 bits, or even 40 bits depending on the compiler and the target processor. C can obscure opportunities for optimization. It can be difficult for compilers targeting specialized processors, such as DSPs, to determine when the C code can be mapped to the processor’s special-purpose instructions.
Retroffiting C: Variations on a Theme
There are two basic approaches to making C a better fit for signal processing applications. The first is to add “intrinsics,” functions that the compiler converts directly into efficient assembly code. Another approach is to extend the C language with specialized data types and constructs that closely match the demands of signal processing algorithms. One such extension, Embedded C, adds fractional data types, saturation arithmetic, and multiple memory spaces to C. As shown in Figure 2, C code with extensions can produce better results because the compiler has a clearer path when mapping the code to the hardware. However, in order to use these variations of C, the programmer must first learn the new language features and when best to use them. Of course, a compiler that understands the extensions is also required. Because many compilers do not support these C extensions, using these extensions makes code less portable and less reusable.

Embedding C++
C++ has its heritage in C, but is a much more complex and powerful language, with strong support for object-oriented programming. So, while many embedded versions of the C language add new features to the language, embedded versions of C++ generally remove language features from C++. This is done to increase the efficiency of the compiled code, to reduce the size of the resulting executable, or to make compiler design easier. Trimming C++ is a compromise between the usefulness of a C++ language feature and the efficiency gained by its removal. Removing features from the language also allows the included libraries to be smaller.
Embedded C++ is an attempt to standardize a subset of C++ for embedded applications. It removes various features from C++ such as multiple inheritance, exception handling, templates, and namespaces. Some compilers which support Embedded C++ retain support for some of the removed features. For example, Texas Instrument’s TMS320C6000 C/C++ compiler supports Embedded C++ but retains support for C++ namespaces.
Code from MATLAB
Perhaps the most commonly used language for signal processing algorithm development and exploration is MATLAB from The MathWorks. The mathematical, matrix-based structure of the MATLAB language is a good fit for signal processing algorithms that can be expressed as mathematical functions. In fact, many algorithms can be described in a few lines of MATLAB code. In addition, MATLAB provides a full range of data display options, such as graphs and charts.
Although it is commonly used for algorithm development, MATLAB has not traditionally been used to generate code for embedded processors. Instead, a common practice is to validate an algorithm by writing and testing it in MATLAB, and then to rewrite it as a C program so that it can be compiled for the processor. Several companies are working to close this implementation gap by compiling MATLAB models so that they may be used for software implementation as well as algorithm development. For example, the MATLAB-to-C tool from Catalytic compiles a MATLAB model into fixed-point C code targeted for Texas Instruments’ ‘C64x processors.
Data Flow: Block by Block
In a data flow language, the design is expressed as a set of processes (blocks) which are connected together by data paths. Figure 3 shows an example of such a language. When the program runs, data flows through the data path connections. Each block in the system takes in its data, processes it, and passes it along to the next block. The data flow programmer chooses which blocks to use, sets the parameters (if any) of each block, and specifies the connections between the blocks. The data flow compiler then manages the scheduling of block execution and the flow of data between blocks.
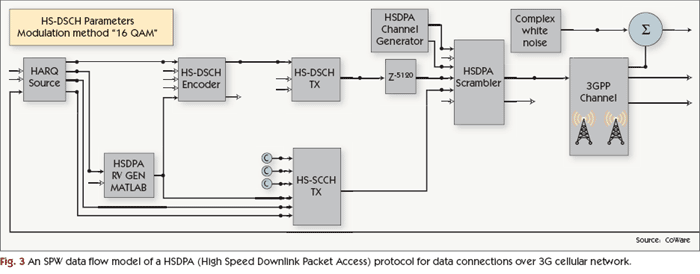
Signal processing algorithms often fit well into a data flow language because the data moves in a regular and predictable manner in many algorithms. However, an algorithm that employs a large amount of conditional branching, for example, might not be a good fit. Also, the non-signal-processing portions of the system, such as the user interface supervisory control, might be better expressed using a more general-purpose language. This can be an issue if there is a desire in the project to use one language for the entire system.
While most data flow languages are used for simulation, some can also be used to generate processor code from a data flow design. One method of code generation is to first supply target code for each block in a code generation library. The data flow language can then be used to generate additional code to handle scheduling, buffering, and the movement of data between the blocks.
Some data flow languages can produce code targeted for different processors depending on the block library used. For example, Simulink with Real-Time Workshop from The MathWorks produces generic C code that may be compiled for any processor. Simulink can also produce TI ‘C6x-specific code when the TI code generation block library is used. However, even within the same language, block libraries targeting one processor are often not compatible with the block libraries targeting another.
Not all data flow languages produce C code as an output. The RIDE environment from Hyperception (National Instruments) compiles a data flow graph into processor-specific assembly code. And some processor vendors offer proprietary data flow languages that can only be used with their processors. For example, VisualAudio language from Analog Devices can only be used with the company’s SHARC processors. The key disadvantage of these narrowly targeted data flow languages is that they offer limited portability. The benefit of this narrower targeting is that the data flow languages are more likely to generate efficient code.
An advantage of a data flow language is that if the block libraries contain all of the needed blocks, a design can be implemented extremely quickly. However, many designs will require one or more custom blocks. While it may be easy to add a new block that will work in a simulation run, it is often much more difficult to create a custom block that can also be used to generate processor code. Some languages, such as SPW from CoWare, allow the programmer to create a custom block by modifying the code of an existing one. In other data flow languages a custom block may have to be developed from scratch.
Multiprocessors: Programming Parallelism
When using a language such as C, the programmer must describe the algorithm as a series of sequential steps. This can mask parallelism that may be present in the algorithm. When looking at the resulting code it may be hard to tell if the program steps really must be done in the exact order in which they appear or if the ordering is only an artifact of the programming language. Furthermore, when partitioning a sequential program across multiple processors, it can be difficult to estimate how often a function will be called and what the resulting inter-processor communication might be.
In contrast, it can be easier to partition a data flow design across processors at the block level, since the connections between blocks are limited and clearly specified. Since the data movement between blocks is generally regular and predictable, the resulting inter-processor communications load can also be estimated. For example, Gedae, Inc. provides a data flow language and tool set that allows the designer to partition a data flow program across any number of processors while maintaining its functionality. As multiprocessor systems become more common, new language approaches like this will be needed to take advantage of the opportunities for parallelism.
Making the Choice
Often the choice of language is constrained by the choice of processor, for two reasons. First, a given processor typically has support only for a subset of languages. Second, if the processor can barely handle the workload assigned to it, then very efficient code will be required. This typically means that assembly language or assembly mixed with C may be the only option. But when factors like developer productivity, code portability, and ease of maintenance are critical, the choice of language may come first and may become a key factor in the choice of processor. And as processors become more powerful and compilers more sophisticated, signal processing software developers will have an expanding palette of languages from which to choose.
This article was contributed to by Alan Kamas, an independent consultant specializing in DSP, communications, and systems simulation & design.
Add new comment