
Practical computer vision (i.e. "embedded vision") is rapidly becoming a mainstream reality. Numerous processor chip and core suppliers have responded to increasing market demand with a variety of processor options. One of the first companies to target the vision processor space, Quebec, Canada-based CogniVue, has just unveiled its third-generation core architecture.
CogniVue's path to the vision market involved several intermediate steps. The company was initially founded fifteen years ago by several university professors as a supplier of computational memory devices (a lineage still evident in the abundance of localized memory resources on today's APEX vision processor cores). In the mid-2000s, CogniVue transitioned to becoming a general-purpose multimedia coprocessor developer; the company's focus narrowed to vision processing around 2010. And whereas CogniVue initially strove to be a fabless semiconductor supplier, the company has been wholly focused on the processor core licensing business for the past three years.
CogniVue’s publicly disclosed design wins include partner Freescale, whose SCP2200 and newly released S32V SoC families are based on first- and second-generation CogniVue Image Cognition Processor (ICP) cores, respectively, and two generations of NeoLAB Convergence "smart pens". CogniVue's APEX architecture blends scalar and vector processing capabilities within a customizable core. Looking at the second-generation APEX, for example, each Array Processor Unit (APU) is comprised of a variable number of four-element vector VLIW SIMD computational units (CUs), each paired with a variable (512 bytes to 8 KBytes) amount of computational memory (CMEM) (Figure 1).
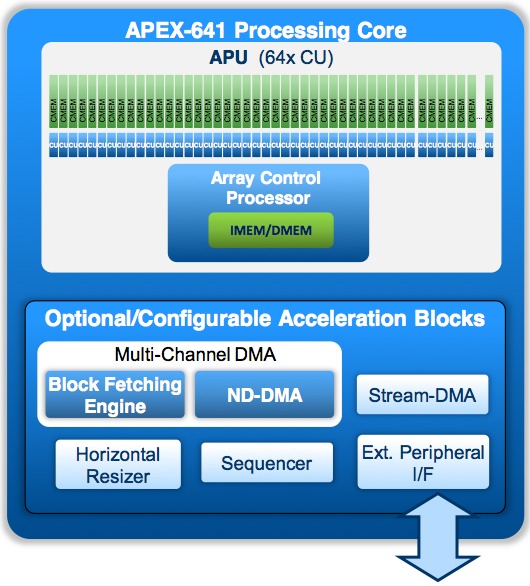

Figure 1. CogniVue's APEX vision processor core architectures embed both scalar and vector processing resources, along with fixed-function blocks, as this second-generation core example shows (top). Equally notable is the architecture's flexibility, enabling it to be expanded and otherwise custom-tailored for specific applications' speed, power consumption, and silicon area needs (bottom).
Conducting the symphony of CUs' activities, along with providing scalar processing facilities of its own, is the custom RISC array control processor (ACP), which has its own tightly coupled instruction and data memory (IMEM and DMEM). And completing the picture are various optional hardware function blocks, such as DMA controllers, sequencers, and interfaces to other SoC cores and on-chip resources. The ratio between CUs and ACPs within an APU is customer-definable, as is the number of APUs within an APEX core. Factors in determining the exact configuration for a particular implementation include the required proportion of scalar versus vector processing resources, along with the relative priority of performance versus silicon area.
According to the company's Vice President of Marketing, Tom Wilson, and Vice President of Engineering, Ali Osman Örs, with whom BDTI recently met, the new third-generation APEX core family's enhancements were driven by key evolving market requirements such as:
- Many more computer vision functions operating in parallel, as in forward-facing camera automotive safety applications
- The need for ever-higher precision results
- Increasing adoption of 2k-resolution video to support longer-distance image analysis and more reliable object detection
- Key-customer interest in Cascade object-recognition classifiers, along with emerging interest in the use of convolutional neural network (CNN)-based classifiers
- The expanded use of various 3D sensor technologies (stereo, time-of-flight, structured light, etc.) with associated computationally intensive disparity map, point cloud and other processing requirements
As a result, for example, the CUs in the third-generation APEX approach, code-named "Opus", are now 32-bit in nature, versus 16-bit in the prior generation. The "Opus" ACP has also grown, from 32-bit to 64-bit, and is now also VLIW in nature. The peak operating clock frequency has increased from 700 MHz to 1 GHz on a common 28 nm fabrication process node. And the amount of intra-core interconnect bandwidth has also been "significantly increased," according to Örs and Wilson, in a particular nod to the needs of CNN-based designs(Figure 2). The result, they estimate, is a 5-10x average performance increase when comparing second- and third-generation APEX cores of comparable CU and ACP counts.
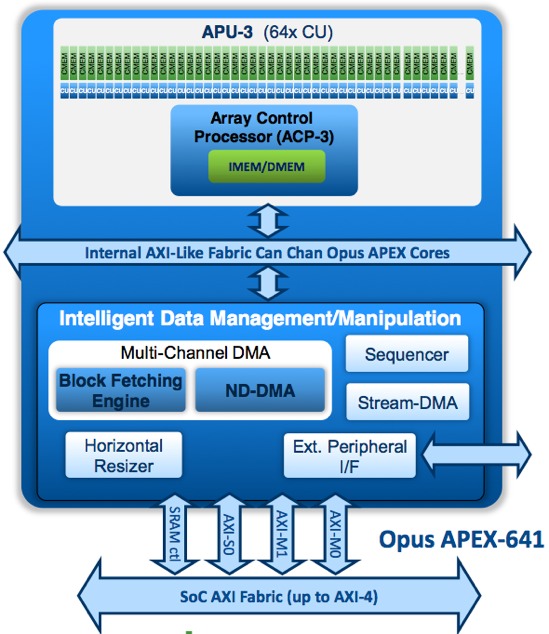
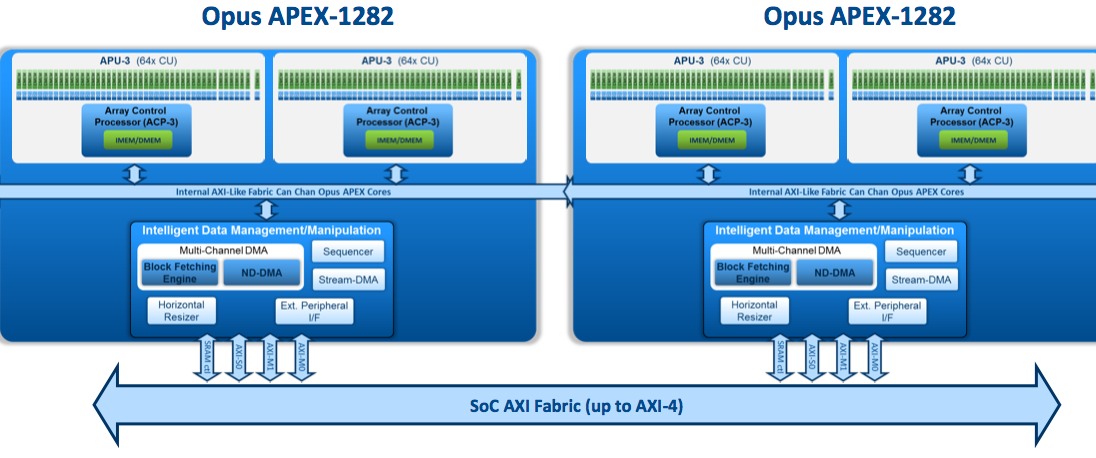
Figure 2. The latest third-generation "Opus" APEX architecture iteration widens both the scalar and vector processors, along with the buses interconnecting them to each other and their associated memory arrays (top). Multiple cores can communicate with each other over both internal "AXI-like" and external full-AXI fabrics (bottom).
CogniVue has also noted the increasing popularity of heterogeneous processing in SoCs for vision, a trend driven in part by the maturing OpenCL framework standard maintained by the Khronos Group. In response, the third-generation "Opus" architecture also makes notable improvements to its inter-core connectivity capabilities. An internal "AXI-like" interconnect fabric allows for chaining together multiple APEX cores. Inter-APEX core connections can alternatively be made via the external fabric, which is AXI-3-compliant, implements up-to-AXI-4 capabilities, and is primarily intended for stitching together an APEX vision coprocessor and other cores such as a CPU and GPU.
Silicon potential means little without development tools to actualize it, of course, and CogniVue strives to deliver here as well (Figure 3). An APU Compiler tool chain supports both conventional and OpenCL C source code inputs and generates corresponding kernel code, which the higher-level "Simulink-like" APEX Core Framework toolset stitches together, comprehending and accounting for data dependencies as well as maximizing the utilization of on-core memory resources to boost performance and minimize power consumption. According to CogniVue, Core Framework also enables developers to rapidly evaluate various proportions of per-core ACPs and CUs in order to optimize size, speed, and other parameters.
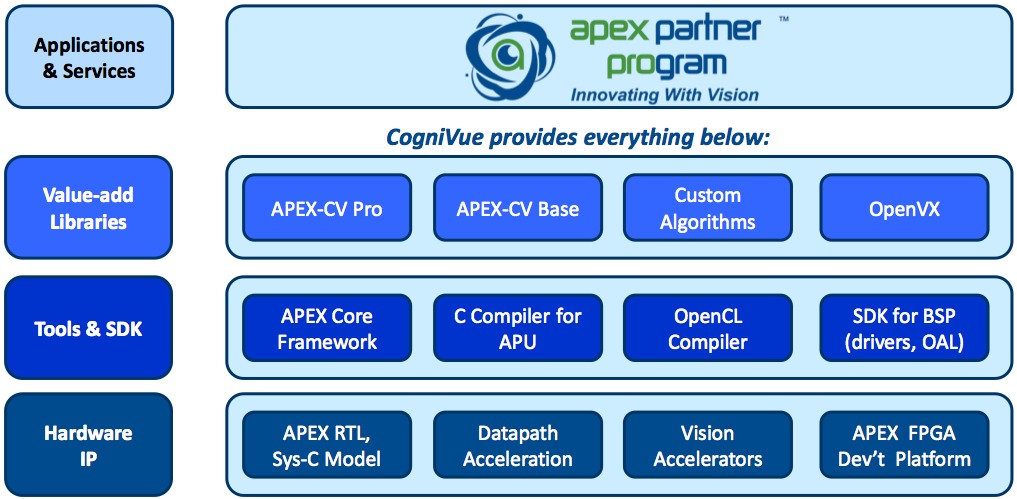
Figure 3. CogniVue is determined to not make the mistake of focusing predominantly on silicon to the detriment of associated (and necessary) compilers, libraries and other development tools.
To simplify software development, the company provides the APEX-CV base library for free to core licensees; its 87 optimized kernels handle various image manipulation, image filtering, color space and color format conversion, image statistics, morphology, shape analysis, interpolation, and image transform tasks. And the separately licensable APEX-CV Pro library includes optimized higher-level algorithms for classifiers, geometric image transforms, motion analysis, edge and line detection, key point detection, feature point descriptors, image segmentation, and computational photography.
CogniVue, a pioneer in the vision processor core space, is facing increasing competition from an increasing number of larger competitors. The company is responding not only by enhancing its foundation silicon architecture but also by bolstering its associated development tool suite as a means of enabling licensees to rapidly and cost-effectively deliver robust SoC designs to market. And the architecture's fundamental flexibility ("scalability from ultra-tiny APEX configurations with just 32 CUs for wearables up to > 256-CU configurations for high-end automotive vision," to quote CogniVue) will also serve the company well as it strives to secure licensee agreements across a range of applications and markets.
Add new comment