
"If it has speech recognition, why do we have to use our fingers?" According to Bernie Brafman, Vice President of Business Development at Sensory, that simple question has been at the forefront of many of the company's customers' minds throughout Sensory's 19-year existence. That same question has therefore guided the privately held company's technology and product roadmap. But actualizing this aspiration involves, at first glance, difficult tradeoffs. Always-active speech recognition requires that the microphone, ADC, memory and DSP (or other processor running the speech recognition algorithms) be perpetually powered up, presumably leading to unacceptable battery drain in the portable electronics devices that constitute a dominant percentage of Sensory's various potential markets.
By preceding speech recognition with simpler voice detection, along with optimizing the software and the processing core(s) that run them, Sensory believes that it has resolved this quandary. And, through multiple generations of TrulyHandsfree algorithm releases, the company has not only added key features but also increased the allowable distance between the speech source and the microphone. The challenge here is perhaps obvious: as the mouth-to-microphone span increases, not only does the signal at the destination decrease in amplitude, but the degrading effects of ambient noise also become more pronounced.
Sensory's initial high volume success, therefore, came from the incorporation of TrulyHandsfree capabilities into systems paired with Bluetooth headsets, wherein the maximum mouth-to-microphone distance was measured in inches (or less). More recently, however, Brafman claims that TrulyHandsfree speech recognition can now operate robustly (both as measured by low false-negative and false-positive scores) on a smartphone, tablet or other battery-operated device several feet away from its owner. And in doing so, it consumes less than 7.5 mW of power, assuming a 3.75 V supply, and using Sensory's 2 mA current draw estimate. This is equivalent to a 20 minute reduction in operating life on a typical phone that's otherwise idle, and has an imperceptible battery life impact in normal phone usage settings, according to Sensory.
Sensory initially operated exclusively as an IC developer, and the company still supplies speech processors for toys and other dedicated-function consumer electronics devices. However, Brafman noted that a few years ago, the company increased its focus on software-only market opportunities, in acknowledgement of the increasing performance of third-party DSPs and other processors. Indicative of this trend, Sensory's mid-February press release trumpeting latest-generation TrulyHandsfree v3.0 was notably accompanied by partner announcements from CEVA, Tensilica (along with a second release from that company) and Wolfson Microelectronics. Quoting from the release, published during the Mobile World Congress:
- TrulyHandsfree 1.0 introduced single voice trigger technology, used for initial "no buttons required" voice activation of a device.
- TrulyHandsfree 2.0 introduced higher accuracy triggers with multiple phrase/trigger technology that recognizes, analyzes and responds to dozens of keywords, enabling a voice user interface that is more natural and intuitive, even from a distance or in the presence of noise.
- TrulyHandsfree 3.0 adds a host of new features including the ability for end users of products to create their own custom triggers, and custom biometric passphrases to unlock or access their devices without any touching required and with high security without inconveniencing the user.
TrulyHandsfree is highly configurable with respect to accuracy, speed, and confidence levels, capable of operating exclusively on pre-configured vocabulary sets or additionally supporting on-the-fly custom phrases, and also optionally customizable to respond to only one (or several) particular speakers' voices (Figure 1).
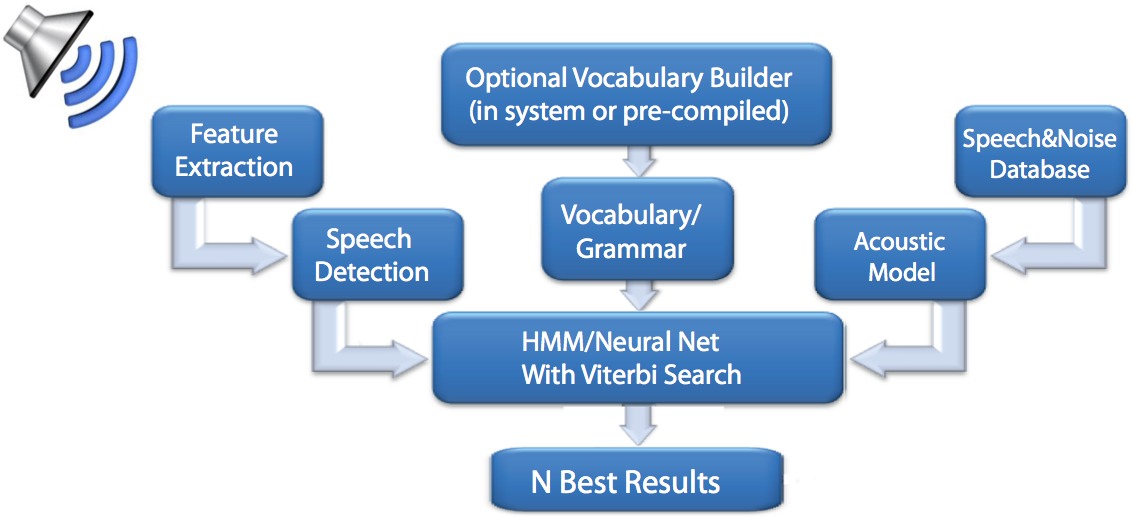
Figure 1. Sensory's TrulyHandsfree Voice Control optionally supports user-customized vocabulary sets and also allows for memory footprint-versus-recognition speed-and-accuracy tradeoffs to determine the size of the neural net recognition algorithms.
The speech recognition algorithms can be embedded within a DSP or other processor's firmware in an operating system-independent manner, for minimal processor load and memory footprint. Or, for ease of implementation and flexibility, they can run at the application level on top of a variety of operating systems (Figure 2).
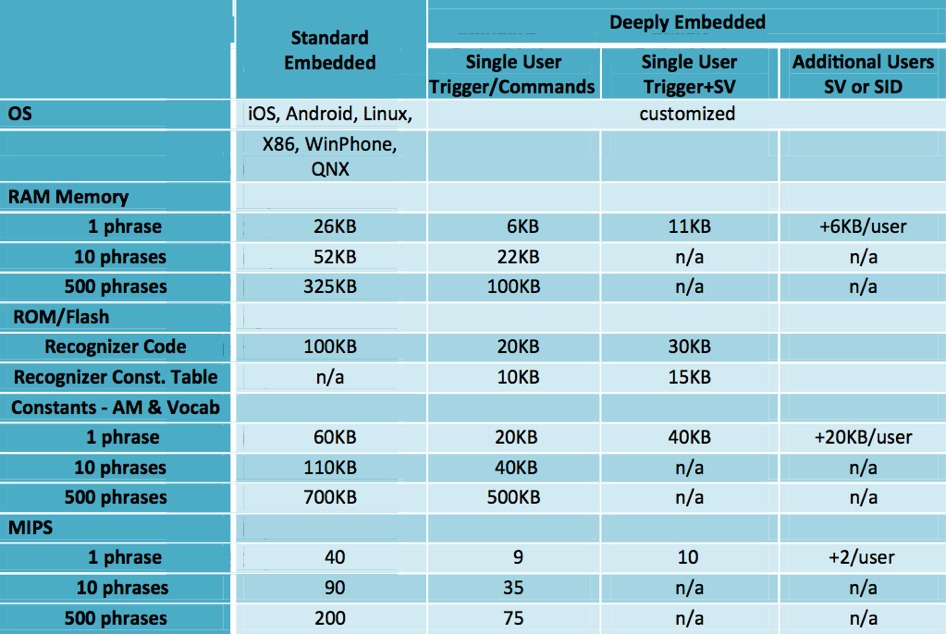
Figure 2. TrulyHandsfree's algorithms are highly configurable to address various memory and processing performance budgets, along with vocabulary set sizes and implementation scenarios, and the recognition code also comes in both firmware-based and application-level forms.
Sensory is unusually (and refreshingly) open and detailed about its algorithms' processing and memory requirements across a diversity of possible configuration scenarios. In the above table, note that the firmware-based approach is referred to as "deeply embedded," while the application-level approach is the "standard embedded" option. "SV" refers to speaker verification (for single-user scenarios), while "SID" is speaker identification (for multi-user setups). The memory footprint estimates are based on a five-syllable average phrase length. Also, acoustic models (AM) and vocabulary data are required for each language. Most non-English languages require slightly less data memory.
For even lower power consumption scenarios, deeply embedded applications can leverage Sensory’s sound detector algorithm as a front end to the recognizer routines. The sound detector monitors the environment and only activates the recognizer when it ascertains there's likelihood that speech is being received. The sound detector requires 0.50 MIPS of CPU resources, 1 KB of code memory, and a 10 KB "audio history" RAM buffer in order to initialize the recognizer subsequent to "waking it up."
Sensory's target applications support "medium" sized vocabulary sets of 1,000 words or less, which Brafman sees as more than sufficient for most speech recognition-based system control scenarios. Good user interface design, for example, only requires six to 10 phrase options per menu level in his opinion; hundred-plus word vocabularies are often only necessary in media search scenarios. But what about generalized voice-controlled search engines such as Apple's Siri and Google's Voice Search? Sensory is happy to coexist with them, handling basic speech recognition tasks itself via its power-stingy resident-stored vocabulary set(s) and, when necessary, handing off recognition responsibilities to the cloud-based alternatives (which are more battery-draining, due to the requisite wireless connections).
What about recognition success rate, both in distinguishing correct words and speakers of those words? As Sensory's documentation notes, "accuracy can vary widely with vocabulary size, vocabulary words, grammar specifications, noise conditions, accents of users, distance from mic to speaker, and technology used." One sample accuracy curve published by the company involves a single TrulyHandsfree trigger phrase and shows false accept and false reject results in various noise conditions (Figure 3). In the tests that generated these results, the in-vocabulary input data consisted of 250 recordings of the phrase "Hello BlueGenie" and was used to calculate the false reject rate. The out-of-vocabulary data encompassed approximately 23 hours of non-stop (therefore worst-case, compared to typical usage scenarios) background conversation speech recordings.
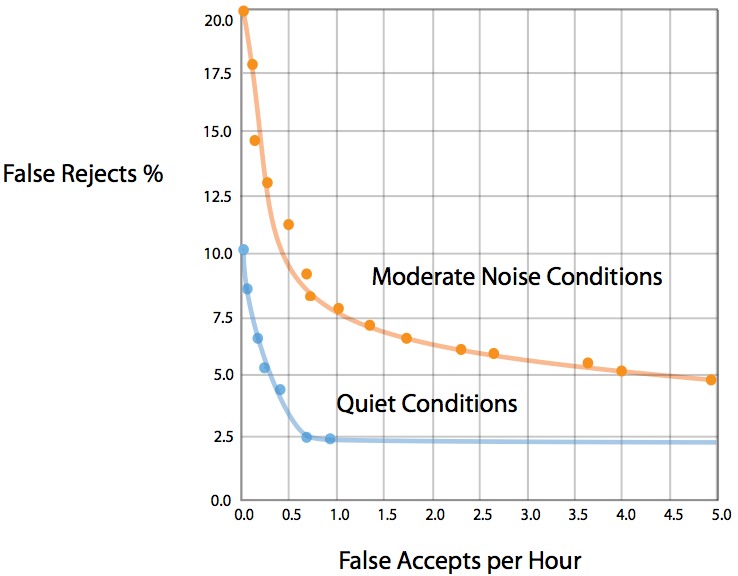
Figure 3. A Sensory-supplied accuracy curve for a single TrulyHandsfree phrase trigger shows false reject and false accept results for various background noise scenarios.
The quiet condition measurements were made with no background noise added to the "Hello BlueGenie" recordings. Moderate noise conditions, on the other hand, involved mixing out-of-vocabulary noise into the "Hello BlueGenie" recordings at a controlled signal-to-noise ratio (SNR). The latter case combined results for SNR=10 and SNR=infinity (i.e., quiet), with SNR defined as the ratio of peak speech level to average noise level. Note that Sensory’s use of peak rather than 'average' speech levels make the company's approach more challenging for a given SNR than if average/average or peak/peak signal-to-noise measurements had been used.
Sensory wasn't the only company to announce always-on, low-power speech recognition capabilities at the February 2013 Mobile World Congress. Qualcomm unveiled Snapdragon Voice Activation, currently offered only on the newest high-end Snapdragon 800 application processors and due to appear in production smartphones and tablets later this year. When I asked Sensory's Brafman about TrulyHandsfree support in Qualcomm's SoCs, specifically running on the on-chip QDSP6 DSP core, he declined to comment. As such, an interview with Qualcomm also seemed warranted in order to obtain a more comprehensive perspective on the mobile phone always-on speech recognition market.
Andrew Kostic, Qualcomm's senior product manager for audio and voice, was reluctant to discuss Snapdragon Voice Activation in great detail given the product's current under-development status. He did, however, confirm that the algorithms predominantly run on the QDSP6 DSP, befitting the DSP’s role as the lowest-power-consumption processor core (for applicable applications) in Qualcomm's multi-core SoCs. Like Sensory, Qualcomm sees always-on speech recognition as complementary to cloud-based speech recognition schemes such as Google Voice Search. But perhaps surprisingly, Kostic also views Sensory as a potential partner for more involved applications, via Qualcomm's Hexagon DSP Access Program.
According to Kostic, Qualcomm's intent was to develop a base level of speech recognition functionality available to all of the company's application processor customers. The main current market opportunity, he feels, involves OEM-specific single-phrase triggers; think, for example, of the aggressively Apple-branded phrase "Siri," or of the "Hey Snapdragon" phrase that Qualcomm demonstrated at MWC. With that said, Qualcomm is considering eventually enabling both user-customized phrases and speaker verification and identification. And nearer term, the company plans to expand speech recognition support beyond American English to other languages (and country-specific variants of them) as market conditions warrant.
Speaking of language capabilities, Sensory currently claims support in TrulyHandsfree for 43 languages and dialects, with more under development. TrulyHandsfree is contained within the company's FluentSoft SDKs, intended for development (therefore usable for up to six months license-free), selling for $2500 and containing:
- The company's speech technology library
- Reference code samples
- Documentation
- A technology API, and
- Five hours of technical support
SDK customers with plans to go to market would also sign a production license agreement (typically involving a per-unit royalty, with other business models also possible). Exemplifying the various available business models, Samsung's popular Galaxy S II and S III handsets used a version of TrulyHandsfree licensed by a company called Vlingo, while for the newer Galaxy S4, Samsung directly licensed TrulyHandsfree from Sensory, implementing it running on top of Android and within the S Voice application. Deeply embedded custom processor porting work can optionally be done by Sensory, in conjunction with the payment of an NRE fee.
Sensory's (and Qualcomm's) claims are aggressive: accurate identification of a particular speaker along with high-accuracy recognition of what he or she is saying, across a robustly sized vocabulary of locally stored words and phrases, even in high ambient noise environments with a several foot span between mouth and microphone, and with barely (if that) discernible negative impact on battery life. Time will tell to what degree the marketing promotion approximates reality. But if the results are deemed acceptable by users, it's hard to imagine that always-on speech recognition won't become a standard feature across a range of both wall outlet- and battery-powered systems. As Sensory competitor Nuance Communications suggested in a recent contributed opinion piece in Wired Magazine, and after decades' worth of speech recognition development and overenthusiastic forecasts and promises, it's perhaps finally "Time for a Conversational User Interface."
Add new comment